今天,斯坦福发布了一个由LLaMA 7B微调的模型Alpaca,训练3小时,性能比肩GPT-3.5。一觉醒来,斯坦福大模型Alpaca(草泥马)火了。没错,Alpaca是由Meta的LLaMA 7B微调而来的全新模型,仅用了52k数据,性能约等于GPT...
”斯坦福Alpaca“ 的搜索结果
Stanford Alpaca是一个Instruction-following的LLaMA模型,即一个对LLaMA模型进行指令调优的结果模型。更多细节可以参考。
先是斯坦福提出了70亿参数Alpaca,紧接着又是UC伯克利联手CMU、斯坦福、UCSD和MBZUAI发布的130亿参数Vicuna,在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力。 最近伯克利又发布了一个新模型「考拉Koala」,...
性能上作者对Alpaca进行了评估,与openai的text-davinct-003模型在self-instruct[2]场景下的性能表现相似。Alpaca 是 LLaMA-7B 的微调版本,使用Self-instruct[2]方式借用text-davinct-003构建了52K的数据,同时在其...
斯坦福的 Alpaca 是一种基于指令执行的语言模型,它可以根据用户给出的指令,生成不同类型的文本内容,例如诗歌、故事、代码等。Alpaca 的特点是它可以快速地适应新的任务和数据集,而不需要重新训练或微调。Alpaca ...
比如,斯坦福的草泥马(Alpaca)、UC伯克利联手CMU、斯坦福等骆马(Vicuna),初创公司Databricks的Dolly等等。 针对不同任务和应用构建的各种类ChatGPT的大型语言模型,在整个领域呈现出百家争鸣之势。 那么问题...
最近,UltraLM-13B 在斯坦福大学 Alpaca-Eval 榜单中位列开源模型榜首,是唯一一个得分在 80 以上的开源模型。ChatGPT之后,开源社区内复现追赶 ChatGPT 的工作成为了整个领域最热的研究点。其中,对齐(Alignment)...
除了在 AlpacaEval 评测集上进行评估外,我们还自己构建了一个指令评测集,该评测集包含了 80 条 Vicuna 测试集,以及其他 300 条由 GPT-4 生成的不同领域不同难度的指令,涵盖了对常识知识、世界知识、专业知识、...
GPT-3.5 (text-davinci-003)、ChatGPT、Claude 和 Bing Chat 等指令遵循模型现在被许多用户广泛使用,包括用于与工作相关的任务。然而,尽管它们越来越受欢迎,但这些模型仍然存在许多需要解决的缺陷。...
毕竟是斯坦福大学训练的模型,对中文的确支持的不好。1、自己买个GPU服务器(如果不训练,可以随便买个高内存的即可),有些网站很便宜,小时起租!3、上面两个模型搞定跑起来之后,是否能训练自己的模型呢?,不...
还开始研究一系列开源模型(包括各自对应的模型架构、训练方法、训练数据、本地私有化部署、硬件配置要求、微调等细节)该项目部分一开始是作为此文《》的第4部分,但但随着研究深入 为避免该文篇幅又过长,将把『第...
翻译与解读时间2023年3月13日地址GitHUb地址:作者我们介绍了Alpaca 7B,这是一个在52,000个instruction-following示范中,通过对LLaMA 7B模型进行微调得到的模型。在我们对单轮instruction-following的初步评估中,...
从上面可以看到,在一台8卡的A800服务器上面,基于Alpaca-Lora针对指令数据大概20分钟左右即可完成参数高效微调,相对于斯坦福羊驼训练速度显著提升。参考文档LLaMA:斯坦福-羊驼。
个人电脑即可,不需要GPU,但要主要内存最好大于8G。我直接在虚拟机中安装成功,且流程运行。...1. 首先使用如下命令下载 alpaca.cpp 项目。如果运行时报错,有可能是内存或CPU性能不足。2.进入项目后,下载模型。
去年的Alpaca 7B模型,不仅展示了在处理指令任务上的出色能力,还因其相对小的规模和低廉的复现成本而引起了大家的注意。在本篇博客中,汇总了官方报告和官方Git的内容,通过阅读可以了解Alpaca 7B模型的起源、训练...

模型就是用的transformer的decoder,模型设计的不同点在于
预训练模型:decapoda-research/llama-7b-hf 会自动下载。共计33个405M的bin文件,...该数据基于斯坦福alpca数据进行了清洗。由于微调时间较长,这里直接后台运行。效果如下,显存占用约8个G。1、将项目下载到本地。
Alpaca是斯坦福大学在Meta开源的大模型LLaMA 7B基础上使用自构建的52K指令数据重新训练得到的增强模型,它的数据构造和训练成本极低,总计约600美元(数据构建500美元+机器训练100美元),效果却逼近OpenAI的,这篇...
Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 ...
AI工具免费使用
, 原因可能是由于训练的步数不够,只迭代了约1/4个epoch,远小于 Alpaca 的迭代次数(3 epochs),模型处于欠拟合。但是我们的结果初步验证了假设:仅使用翻译数据和英文指令,也可以使 LLaMA 获得中文指令能力,...
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读 ...《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读...
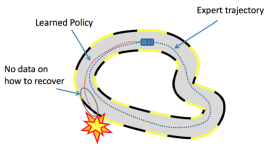
LLMs之Chinese-LLaMA-Alpaca:基于单机CPU+Windows系统实现中文LLaMA算法进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版LLaMA转HF格式+合并llama_hf和chinese-alpaca-lora-7b→下载...

LLMs之Alpaca_LoRA:Alpaca_LoRA简介(痛点/改进)、实战案例—基于CentOS和多卡(A800+并行技术)实现全流程完整复现Alpaca_7B—安装依赖、转换为HF模型文件、模型微调(LoRA+单卡/多卡)、模型推理(CLI/llama.cpp/Docker...
三月中旬,斯坦福发布的 Alpaca (指令跟随语言模型)火了。其被认为是 ChatGPT 轻量级的开源版本,其训练数据集来源于text-davinci-003,并由 Meta 的 LLaMA 7B 微调得来的全新模型,性能约等于 GPT-3.5。斯坦福...
使用 GPT-4 作为判断的初步评估表明,Vicuna-13B 达到了 OpenAI ChatGPT 和 Google Bard 90% 以上的质量,同时在>90%的情况下优于 LLaMA 和 Stanford Alpaca 等其他模型。剧透下,后文实测效果,其实吧,还行吧。...
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读 目录 《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与...
推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地