[NLP]使用Alpaca-Lora基于llama模型进行微调教程_you are using the legacy behaviour of the <class '-程序员宅基地
Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。
因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调(full fine-tuning)类似的效果。
LoRA 的原理其实并不复杂,它的核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路BA=0从,而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
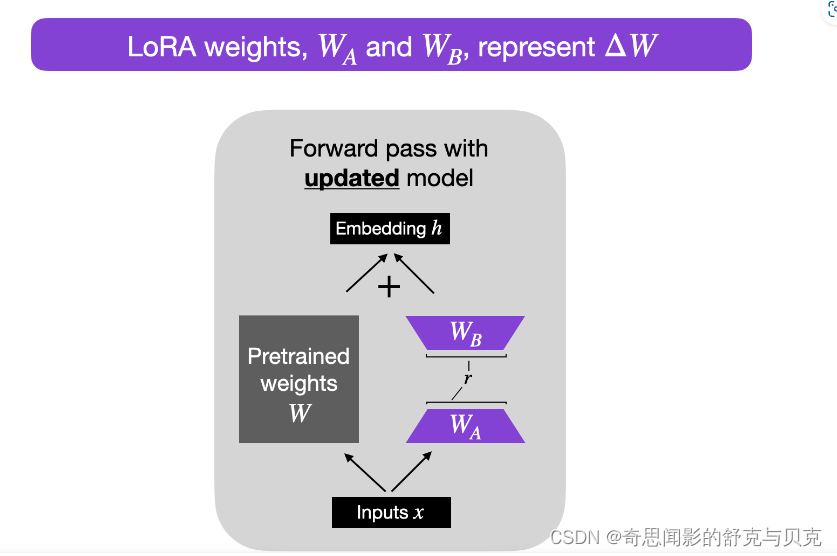
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
准备数据集
fine-tune 的目标通常有两种:
- 像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,让模型完成特定任务
- 语言填充,收集文本用于训练,让模型补全 prompt。
以第一种目标为例,假设我们的目标是让模型讲中文,那么,我们可以通过其他 LLM (如 text-davinci-003)把一个现有数据集(如 Alpaca)翻译为中文来做 fine-tune。实际上这个想法已经在开源社区已经有人实现了。
为了达成这个目标,我使用的数据集是 Luotuo 作者翻译的 Alpaca 数据集,训练代码主要来自 Alpaca-LoRA。
wget https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.jsonAlpach-LoRA 目录中也包含fine-tune的English数据集:

除此之外,可参考GPT-4-LLM项目,该项目还提供了使用Alpaca的Prompt翻译成中文使用 GPT4 生成了 5.2 万条指令跟随数据。
一 环境搭建
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 4 卡 A100 80GB GPU
- Docker Image: pytorch:1.13.0-cuda11.6-cudnn8-devel
1.在 Alpaca-LoRA 项目中,作者提到,他们使用了 Hugging Face 的 PEFT。PEFT 是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。下面安装PEFT。
#安装peft
git clone https://github.com/huggingface/peft.git
cd peft/
pip install .2. bitsandbytes是对CUDA自定义函数的轻量级封装
特别是针对8位优化器、矩阵乘法(LLM.int8())和量化函数。
#安装bitsandbytes。
git clone [email protected]:TimDettmers/bitsandbytes.git
cd bitsandbytes
CUDA_VERSION=116 make cuda11x
python setup.py install如果安装 bitsandbytes出现如下错误: /usr/bin/ld: cannot find -lcudart
请行执行如下命令
cd /usr/lib
ln -s /usr/local/cuda/lib64/libcudart.so libcudart.so3.Alpaca-Lora微调代码
#下载alpaca-lora
git clone [email protected]:tloen/alpaca-lora.git
cd alpaca-lora
pip install -r requirements.txtrequirements.txt文件具体的内容如下:
accelerate
appdirs
loralib
bitsandbytes
black
black[jupyter]
datasets
fire
git+https://github.com/huggingface/peft.git
transformers>=4.28.0
sentencepiece
gradio二 模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。可以直接从Hugging Face下载转换好的模型如下:
下载方法可以参考:[NLP]Huggingface模型/数据文件下载方法
decapoda-research/llama-7b-hf · Hugging Face
decapoda-research/llama-13b-hf · Hugging Face
三 模型微调
Alpaca Lora 作者采用了 Hugging Face 的轻量化微调库(Parameter Efficient Fine-Tuning,PEFT)中所支持的 LoRA 方法。LoRA 方法的两项配置会直接影响需要训练的参数量:
1)LoRA 目标模块(lora_target_modules),用于指定要对哪些模块的参数进行微调。比如我们可以对 Q, K, V, O 都进行微调;也可以只对 Q、V 进行微调。不同的设定会影响需要微调的参数量,也会影响训练过程中的计算量。比如当我们设定只对 Q、V 进行微调时,需要训练的参数量(trainable parameters)只占整个模型参数总量的 6% 左右。
2)LoRA 的秩(lora_r)也是影响训练参数量的一个重要因素。客观来说,使用 LoRA 这样的方法训练得到的模型,在效果上必然会和直接在原始大模型基础上进行训练的效果有一定差异。因此,可以结合所拥有的机器配置、可以容忍的最大训练时长等因素,来灵活地配置 LoRA 的使用方法。
1. 这是微调时的默认参数如下:
batch_size: 128
micro_batch_size: 4
num_epochs: 3
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca2. 使用单块GPU运行如下:
nohup python finetune.py \
--base_model '/home/llama-7b' \
--data_path '../alpaca_data_cleaned.json' \
--output_dir './lora-alpaca-7b-1gpu' \
> torchrun-7b-1gpu.log 2>&1 &
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... On | 00000000:10:00.0 Off | 0 |
| N/A 00C P0 293W / 400W | 10813MiB / 81920MiB | 94% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
3 使用4块GPU运行如下:
nohup torchrun --nproc_per_node=4 --master_port=1234 finetune.py \
--base_model '/home/llama-7b' \
--data_path '../alpaca_data_cleaned.json' \
--output_dir './lora-alpaca-7b-4gpu' \
--num_epochs 1 \
> torchrun-7b-4gpu.log 2>&1 &+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... On | 00000000:16:00.0 Off | 0 |
| N/A 11C P0 282W / 400W | 17055MiB / 81920MiB | 93% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-SXM... On | 00000000:47:00.0 Off | 0 |
| N/A 12C P0 339W / 400W | 14275MiB / 81920MiB | 93% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-SXM... On | 00000000:4B:00.0 Off | 0 |
| N/A 13C P0 324W / 400W | 14773MiB / 81920MiB | 94% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A100-SXM... On | 00000000:89:00.0 Off | 0 |
| N/A 14C P0 325W / 400W | 14385MiB / 81920MiB | 94% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
4.输出如下:
Training Alpaca-LoRA model with params:
base_model: /disk1/llama-13b
data_path: ./alpaca_data_cleaned_archive.json
output_dir: ./lora-alpaca
batch_size: 128
micro_batch_size: 8
num_epochs: 1
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 3%|███▊ | 1330/49759 [00:01<00:39, 1216.23 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 0%| | 0/49759 [00:00<?, ? examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 1%|▊ | 272/49759 [00:00<00:36, 1350.21 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1294.31 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1284.04 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1283.95 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1221.03 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:39<00:00, 1274.42 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1285.16 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1281.27 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1290.31 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
0%| | 0/388 [00:00<?, ?it/s]/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
{'loss': 2.249, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.03}
{'loss': 2.1927, 'learning_rate': 5.6999999999999996e-05, 'epoch': 0.05}
{'loss': 2.0813, 'learning_rate': 7.8e-05, 'epoch': 0.08}
{'loss': 1.7206, 'learning_rate': 0.00010799999999999998, 'epoch': 0.1}
11%|████████████████▋ 11%|███████████▋ | 42/388 [10:50<1:27:2四 合并模型
1.导出为 HuggingFace 格式:
可以下载: Angainor/alpaca-lora-13b · Hugging Face 的lora_weights
修改export_hf_checkpoint.py文件:
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
BASE_MODEL = os.environ.get("BASE_MODEL", "/disk1/llama-13b")
LORA_MODEL = os.environ.get("LORA_MODEL", "./alpaca-lora-13b")
HF_CHECKPOINT = os.environ.get("HF_CHECKPOINT", "./hf_ckpt")
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
lora_model = PeftModel.from_pretrained(
base_model,
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
lora_weight = lora_model.base_model.model.model.layers[
0
].self_attn.q_proj.weight
assert torch.allclose(first_weight_old, first_weight)
# merge weights - new merging method from peft
lora_model = lora_model.merge_and_unload()
lora_model.train(False)
# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)
lora_model_sd = lora_model.state_dict()
deloreanized_sd = {
k.replace("base_model.model.", ""): v
for k, v in lora_model_sd.items()
if "lora" not in k
}
LlamaForCausalLM.save_pretrained(
base_model, HF_CHECKPOINT, state_dict=deloreanized_sd, max_shard_size="400MB"
)python export_hf_checkpoint.py
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:26<00:00, 1.56it/s]查看模型输出文件:
hf_ckpt/
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00082.bin
├── pytorch_model-00002-of-00082.bin
├── pytorch_model-00003-of-00082.bin
├── pytorch_model-00004-of-00082.bin
├── pytorch_model-00005-of-00082.bin
├── pytorch_model-00006-of-00082.bin
├── pytorch_model-00007-of-00082.bin
├── pytorch_model-00008-of-00082.bin
├── pytorch_model-00009-of-00082.bin
├── pytorch_model-00010-of-00082.bin
├── pytorch_model-00011-of-00082.bin
├── pytorch_model-00012-of-00082.bin
├── pytorch_model-00013-of-00082.bin
├── pytorch_model-00014-of-00082.bin
├── pytorch_model-00015-of-00082.bin
├── pytorch_model-00016-of-00082.bin
├── pytorch_model-00017-of-00082.bin
├── pytorch_model-00018-of-00082.bin
├── pytorch_model-00019-of-00082.bin
├── pytorch_model-00020-of-00082.bin
├── pytorch_model-00021-of-00082.bin
├── pytorch_model-00022-of-00082.bin
├── pytorch_model-00023-of-00082.bin
├── pytorch_model-00024-of-00082.bin
├── pytorch_model-00025-of-00082.bin
├── pytorch_model-00026-of-00082.bin
├── pytorch_model-00027-of-00082.bin
├── pytorch_model-00028-of-00082.bin
├── pytorch_model-00029-of-00082.bin
├── pytorch_model-00030-of-00082.bin
├── pytorch_model-00031-of-00082.bin
├── pytorch_model-00032-of-00082.bin
├── pytorch_model-00033-of-00082.bin
├── pytorch_model-00034-of-00082.bin
├── pytorch_model-00035-of-00082.bin
├── pytorch_model-00036-of-00082.bin
├── pytorch_model-00037-of-00082.bin
├── pytorch_model-00038-of-00082.bin
├── pytorch_model-00039-of-00082.bin
├── pytorch_model-00040-of-00082.bin
├── pytorch_model-00041-of-00082.bin
├── pytorch_model-00042-of-00082.bin
├── pytorch_model-00043-of-00082.bin
├── pytorch_model-00044-of-00082.bin
├── pytorch_model-00045-of-00082.bin
├── pytorch_model-00046-of-00082.bin
├── pytorch_model-00047-of-00082.bin
├── pytorch_model-00048-of-00082.bin
├── pytorch_model-00049-of-00082.bin
├── pytorch_model-00050-of-00082.bin
├── pytorch_model-00051-of-00082.bin
├── pytorch_model-00052-of-00082.bin
├── pytorch_model-00053-of-00082.bin
├── pytorch_model-00054-of-00082.bin
├── pytorch_model-00055-of-00082.bin
├── pytorch_model-00056-of-00082.bin
├── pytorch_model-00057-of-00082.bin
├── pytorch_model-00058-of-00082.bin
├── pytorch_model-00059-of-00082.bin
├── pytorch_model-00060-of-00082.bin
├── pytorch_model-00061-of-00082.bin
├── pytorch_model-00062-of-00082.bin
├── pytorch_model-00063-of-00082.bin
├── pytorch_model-00064-of-00082.bin
├── pytorch_model-00065-of-00082.bin
├── pytorch_model-00066-of-00082.bin
├── pytorch_model-00067-of-00082.bin
├── pytorch_model-00068-of-00082.bin
├── pytorch_model-00069-of-00082.bin
├── pytorch_model-00070-of-00082.bin
├── pytorch_model-00071-of-00082.bin
├── pytorch_model-00072-of-00082.bin
├── pytorch_model-00073-of-00082.bin
├── pytorch_model-00074-of-00082.bin
├── pytorch_model-00075-of-00082.bin
├── pytorch_model-00076-of-00082.bin
├── pytorch_model-00077-of-00082.bin
├── pytorch_model-00078-of-00082.bin
├── pytorch_model-00079-of-00082.bin
├── pytorch_model-00080-of-00082.bin
├── pytorch_model-00081-of-00082.bin
├── pytorch_model-00082-of-00082.bin
└── pytorch_model.bin.index.json
0 directories, 85 files2 导出为PyTorch state_dicts:
同理修改export_state_dict_checkpoint.py文件:
第五步:quantization(可选)
最后,Quantization 可以帮助我们加速模型推理,并减少推理所需内存。这方面也有开源的工具可以直接使用。
第六步:相关问题
保存检查点(checkpoint model)时出现显存溢出OOM(Out Of Memory)
调优过程中,遇到保存检查点model(checkpoint model)时出现显存溢出OOM(Out Of Memory)的问题,经过查看issue-CUDA out of memory中的讨论,发现是 bitsandbytes 的新版0.38.1存在bug,需要将版本退回0.37.2,问题解决。
调优结束后adapter_model.bin 没有参数(大小为443)
这个问题主要是由于alpaca-lora和peft库之间的兼容性问题,根据 fix issues to be compatible with latest peft #359 中的讨论来看,目前最简单的做法是修改 finetune.py文件,具体如下:
model.save_pretrained(output_dir) # 原来275行的代码
model.save_pretrained(output_dir,state_dict=old_state_dict()) # 修改后的275行的代码参考文档:
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数