
”scrapy爬虫项目实战“ 的搜索结果
Python-Scrapy 入门级爬虫项目实战 糗事百科段子爬取
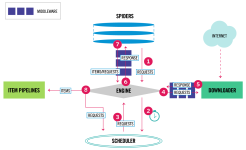
Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。 Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。 ...

Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
终端中执行scrapy startproject 项目名称 如scrapy startproject lagouspider 执行命令后生成的项目目录结构如下: 在项目目录中执行生成爬虫模板文件的命令 执行scrapy genspider 爬虫文件名 域名 如scrapy ...
Scrapy是:由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要实现少量的代码,就能够快速的抓取。入门案例,需要细心,主要是基础知识的巩固,以便于...
『scrapy爬虫』02.实战豆瓣小例子(保姆级图文)
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。...在之前的博文当中,简要介绍了Scrapy相关工具命令的介绍,以及Scrapy爬虫项目的基本结构。
好的,下面给你介绍一下Scrapy爬虫项目实战。 1. 确定目标网站和爬取目标 首先需要确定要爬取的目标网站和要爬取的目标信息。可以通过观察网站的页面结构和URL规律来确定。 2. 创建Scrapy项目 使用命令行工具创建...
有很多网站可以用于 scrapy 爬虫项目实战,以下是一些常用的网站: 1. 爬取新闻网站:可以爬取像新浪新闻、腾讯新闻、网易新闻等大型新闻网站,获取最新的新闻信息。 2. 爬取电商网站:可以爬取像淘宝、京东、天猫...
本文将介绍如何使用Scrapy爬虫框架,构建一个豆瓣电影爬虫,爬取豆瓣电影排行榜中的电影信息。 1. 创建Scrapy项目 首先,我们需要创建一个Scrapy项目。在命令行中执行以下命令: ``` scrapy startproject douban ...


需求: 要求:将所有对应的大类的标题和 urls、子类的标题和 urls、...import Scrapy import sys reload(sys) sys.setdefaultencoding("utf-8") class SinaItem(scrapy.Item): partenTitle =...
将已有的新浪分类资讯 Scrapy 爬虫项目,修改为基于 RedisSpider 类的 scrapy-redis 分布式爬虫项目 注:items 数据直接存储在 Redis 数据库中,这个功能已经由 scrapy-redis实现。除非单独做额外处理(如直接存...
爬虫进阶之scrapy项目实战 前言 觉得Scrapy确实挺强大的,并且要想更加熟悉和了解这个框架,应该要多做一些项目来强化对Scrapy的理解,本次的项目是针对Boss直聘,想要爬取boss直聘根据关键词(地点和工作)的工作...
import scrapy import json from..items import Db250Item class W666Spider(scrapy.Spider): name = 'w666' allowed_domains = ['movie.douban.com'] start_urls = ['http://movie.douban.com/top250'] page_...
不会的同学可参考我的另一篇博文,这里不再赘述:Python之Scrapy爬虫实战–新建scrapy项目 这里只讲一下几个关键点,完整代码在文末。 由于爬取的网站有反爬,一开始没绕过反爬,debug几下代码就被封了ip(我只是在...
目录Scrapy是啥Scrapy的安装实例:爬取美剧天堂new100:(1)创建工程:(2) 创建爬虫程序(3) 编辑爬虫(4)设置item模板:(5) 设置配置文件(6)设置数据处理脚本:(7)运行爬虫 Scrapy是啥 scrapy是一个使用python...
WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"FEE
Scrapy 是一个强大的开源网络爬虫框架,用于从网站上提取数据。它以可扩展性和灵活性为特点,被广泛应用于数据挖掘、信息处理和历史数据抓取等领域。官网链接(外)
python爬虫 python爬虫_爬虫项目实战之Scrapy抓手机今日头条App数据并存入MongoDB
1、创建爬虫项目 在命令行输入: scrapy startproject xiaoshuo 2、创建自己的爬虫文件 scrapy genspider xiaoshuo zwdu.com 3、修改 start_urls = ['https://www.zwdu.com/book/7846/195393...
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤pycharm是无法创建一个scrapy项目的因此,我们需要用命令行的方法新建一个scrapy项目请确保已经安装了scrapy,twisted...
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地