17.网络爬虫—Scrapy入门与实战_scrapy网络爬虫实战-程序员宅基地
技术标签: 爬虫 Python网络爬虫从入门到精通 scrapy mongodb
网络爬虫—Scrapy入门与实战
前言:
️️个人简介:以山河作礼。
️️:Python领域新星创作者,CSDN实力新星认证
第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
第十六篇文章《网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
《Python网络爬虫》专栏累计发表十六篇文章,上榜七篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
Scrapy基础
Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
Scrapy的主要组件包括:
ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理。Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
Scrapy运行流程原理
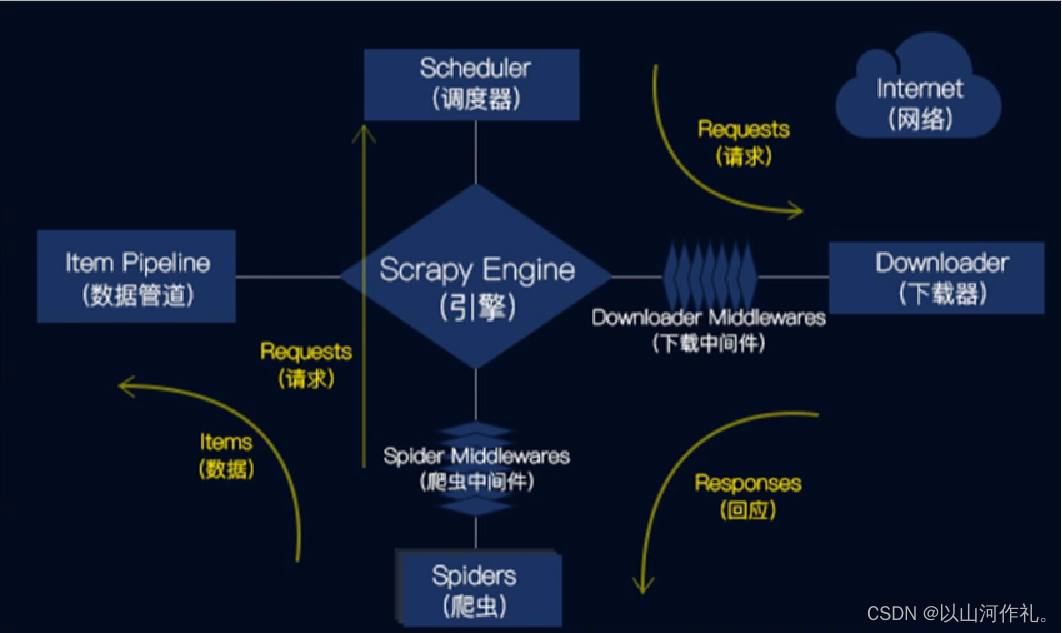
Scrapy的工作流程
1.引擎从爬虫的起始URL开始,发送请求至调度器。
2.调度器将请求放入队列中,并等待下载器处理。
3.下载器将请求发送给网站服务器,并下载网页内容。
4.下载器将下载的网页内容返回给引擎。
5.引擎将下载的网页内容发送给爬虫进行解析。
6.爬虫解析网页内容,并提取需要的数据。
7.管道将爬虫提取的数据进行处理,并保存到本地文件或数据库中。
Scrapy的优点
1.高效:Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
2.可扩展:Scrapy提供了丰富的扩展接口,可以通过编写自定义的中间件来扩展其功能。
3.灵活:Scrapy支持多种数据格式的爬取和处理,包括HTML、XML、JSON等。
4.易于使用:Scrapy提供了丰富的文档和示例,可以快速入门。
Scrapy基本使用(豆瓣网为例)
安装scrapy模块:
pip install Scrapy
创建项目
选择需要创建项目的位置
进入cmd命令窗口(win+r),或者pycharm中打开终端也可以。
第一种方式:
第二种方式:
进入到需要创建文件的盘符,在命令窗口使用命令(C:/D:/E:/F:)进入对应的盘符

进入需要创建的路径:cd 路径
cd D:\新建文件夹\pythonProject1\测试\scrapy入门

当输入命令的前面部分出现对应的路径,代表进入成功

检测scrapy是否成功,直接输入scrapy按确认,
注意:如果没有成功(需要配置pip的环境变量,检测scrapy是否下载成功,是否安装到了其他的解释器中)
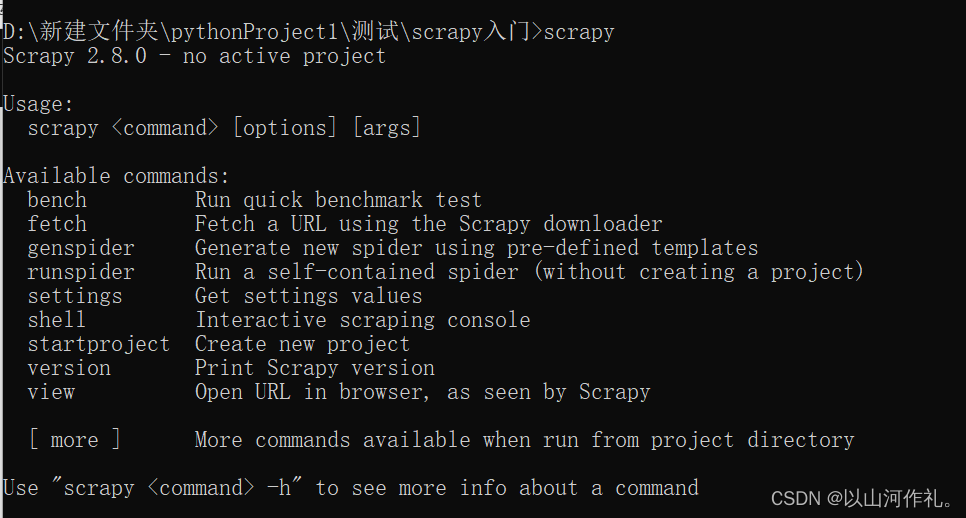
创建项目,使用命令在命令窗口输入:
scrapy startproject douban # douban是项目的名称
确认输入的命令后,会在当前路径下创建一个项目,以下为成功案例:

New Scrapy project 'douban', using template directory 'D:\Python3.10\Lib\site-packages\scrapy\templates\project', created in:
D:\新建文件夹\pythonProject1\测试\scrapy入门\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
创建完成后,如果没有出现文件,进行刷新即可

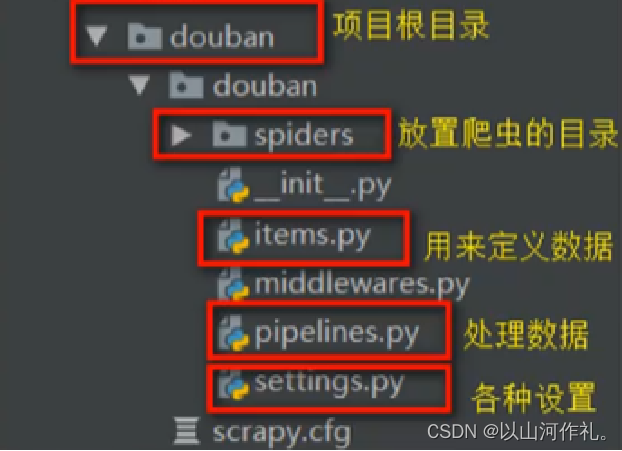
创建爬虫
进入到spiders文件下创建创建爬虫文件
cd 到spiders文件下
例如:
cd douban\douban\spiders
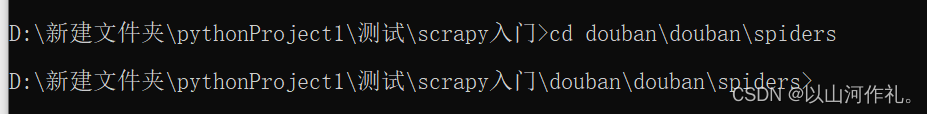
创建爬虫 命令:
[scrapy genspider 爬虫的名称 爬虫网站]
爬虫的名称不能和项目名称一样
爬虫的网站是主网站即可
成功后返回如下
Created spider 'douban_data' using template 'basic' in module:
{
spiders_module.__name__}.{
module}
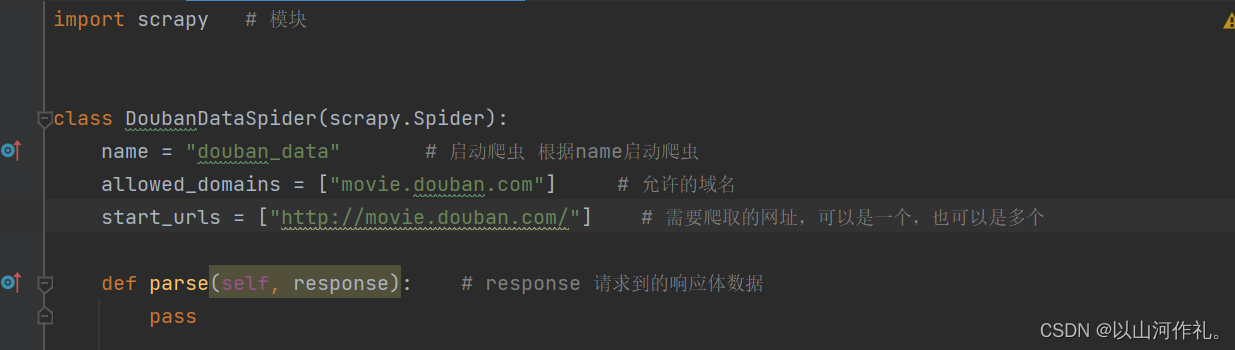
配置爬虫
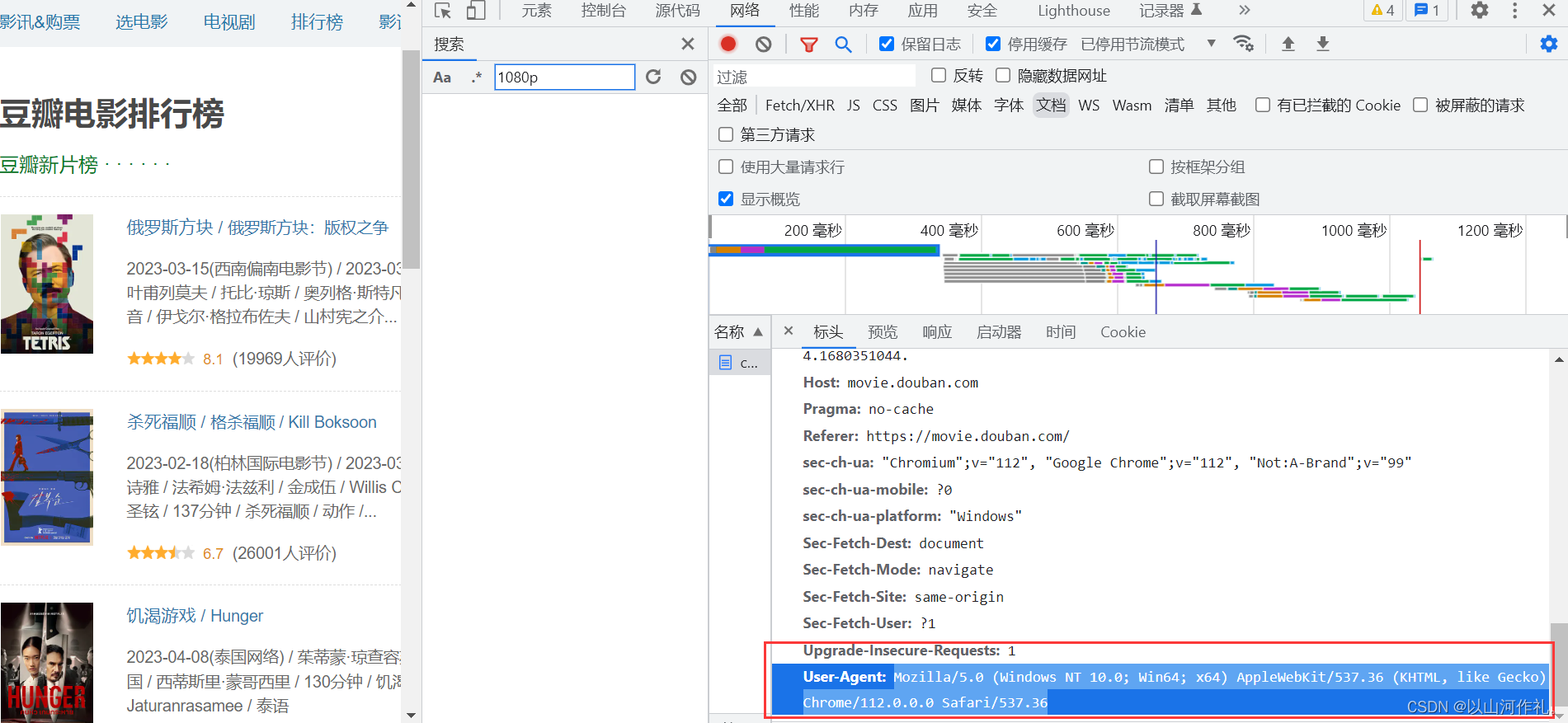
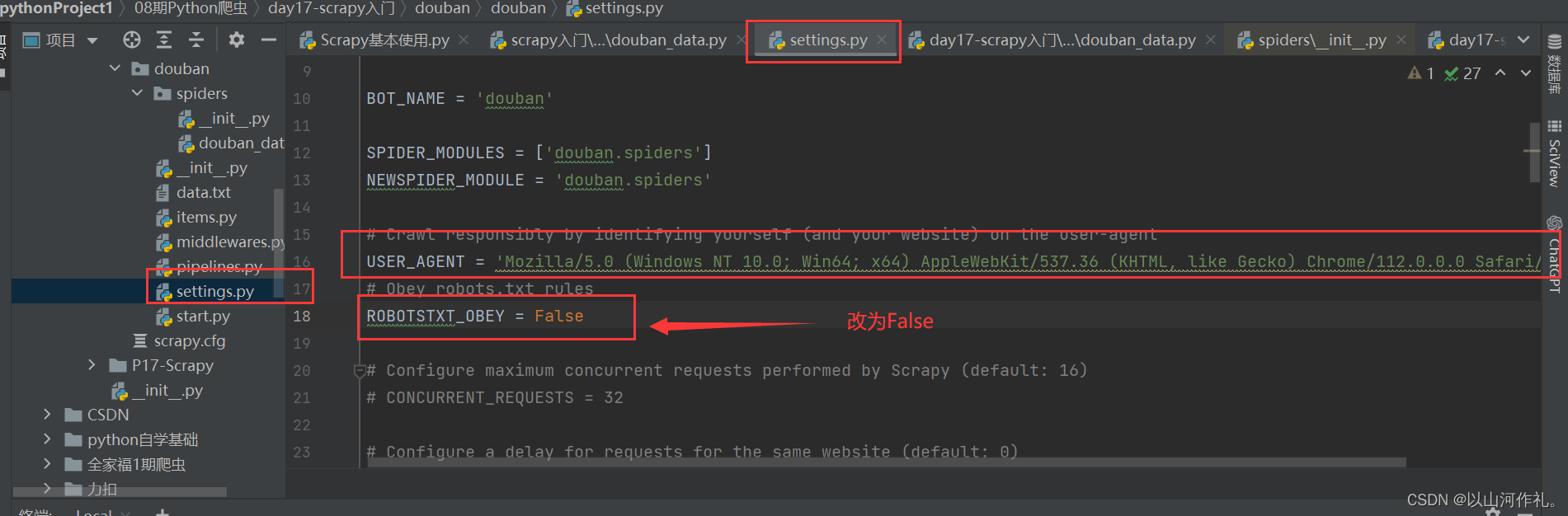
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
运行爬虫
启动爬虫文件 scarpy crawl 爬虫名称
例如
scrapy crawl douban_data
运行结果:
如何用python执行cmd命令
终端获取的数据无法进行搜索,所以我们使用python的模块来运行cmd命令,获取相同的数据,方便我们数据的搜索和筛选。
我们创建一个start的py文件,帮助我们运行程序:
方法/步骤:
- 打开编辑器,导入python的os模块
- 使用os模块中的system方法可以调用底层的cmd,其参数
os.system(cmd) - sublime编辑器执行快捷键Ctrl+B执行代码,此时cmd命令执行
代码如下:
# 'scrapy crawl douban_data'
import os
os.system('scrapy crawl douban_data')
运行结果(展示部分内容):
红色不是报错,是日志文件,日志输出也是红色。
数据解析
我们需要对全部数据进行分析,拿到我们想到的数据,电影名称和电影评分:
title = re.findall('<a class="nbg" href=".*?" title="(.*?)">', response.text)
print(title)
nums = re.findall('<span class="rating_nums">(.*?)</span>', response.text)
print(nums)
打包数据
# 打包数据 /在items中定义传输数据的结构(结构可以定义,或者不进行定义)
item = DoubanItem()
# 需要将一条数据存入到字典中
for title, nums in zip(title, nums):
item['title'] = title
item['nums'] = nums
yield item

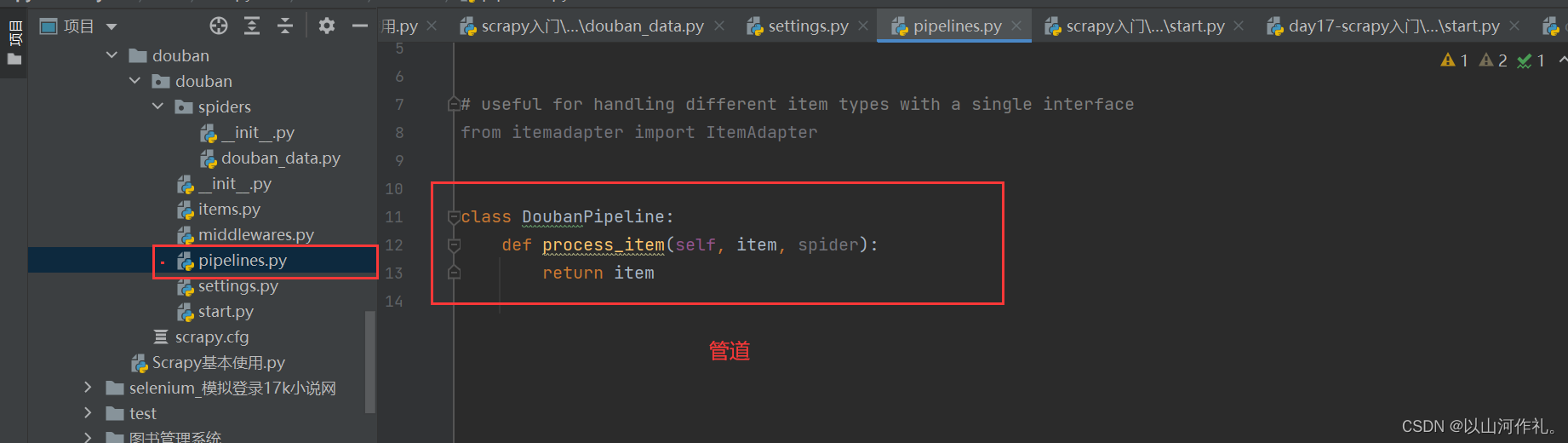
打开管道
解除注释,打开管道

pipeline使用注意点
1. 使用之前需要在settings中开启
2. pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
3. 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
4. pipeline中process_item的方法必须有,否则item没有办法接受和处理
5. process_item方法接受item和spider,其中spider表示当前传递item过来的spider
6. open_spider(self, spider) :能够在爬虫开启的时候执行一次
7. close_spider(self, spider) :能够在爬虫关闭的时候执行一次
8. 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
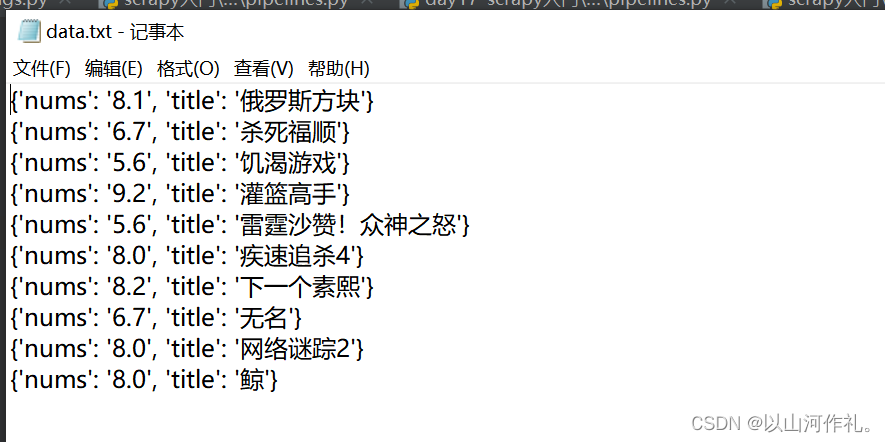
打开管道将数据写入txt文件中
class DoubanPipeline:
def __init__(self):
self.f = open('data.txt', 'w+', encoding='utf-8')
def process_item(self, item, spider):
self.f.write(f'{
item}\n')
return item
def close_spider(self, spider):
self.f.close()
print('文件写入完成')
运行结果:
后记
本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!
智能推荐
苹果电脑第一次用pygame创建主窗口卡死的解决方法_pycharm的pygame.display.set_mode很卡怎么办?-程序员宅基地
文章浏览阅读1.3k次,点赞4次,收藏2次。第一次使用pygame写游戏时,我创立窗口的时候遇到了这样的困难。首先给出我出现卡顿原因的代码:import pygamedef main(): screen = pygame.display.set_mode((350, 500), depth=32) background = pygame.image.load('/Users/chenyang0804/Desktop/屏幕快照 2020-08-17 下午8.54.21.png') pygame.display.set_ca_pycharm的pygame.display.set_mode很卡怎么办?
【Unity】Unity Editor中使输入框失去焦点_guiutility.keyboardcontrol-程序员宅基地
文章浏览阅读2.2k次。【Unity】Unity Editor中使输入框失去焦点Unity自定义编辑器窗口时,如果想让当前正在输入文本的输入框失去焦点,必须把焦点移动到另一个输入控件。如果用代码使当前输入框失去焦点的话,很简单,就一行代码:GUIUtility.keyboardControl = 0;..._guiutility.keyboardcontrol
Linux阅码场 - Linux内核月报(2020年06月)-程序员宅基地
文章浏览阅读1.4k次。关于Linux内核月报Linux阅码场Linux阅码场内核月报栏目,是汇总当月Linux内核社区最重要的一线开发动态,方便读者们更容易跟踪Linux内核的最前沿发展动向。限于篇幅,只会对..._memory tag
c++ pair make_pair_make_pair返回值-程序员宅基地
文章浏览阅读193次。pair 的用法std::pair主要的作用是将两个数据组合成一个数据,两个数据可以是同一类型或者不同类型。C++标准程序库中凡是“必须返回两个值”的函数, 也都会利用pair对象。class pair可以将两个值视为一个单元。容器类别map和multimap就是使用pairs来管理其健值/实值(key/value)的成对元素。pair被定义为struct,因此可直接存取pair中的个别值..._make_pair返回值
微信公众号开发工具汇总-程序员宅基地
文章浏览阅读8.4k次。前面写了篇入坑指南,介绍了下开发微信公众号的基本流程。最近又捣鼓了一阵,发现这开发工具的选择对于提高开发效率真是有莫大的帮助,所谓“只要工具选得好,月底奖金跑不了”。今天得空,笔者就给各位老哥列举几个绝对能派上用场的小工具,保证没毛病!微信公众平台技术文档这货实际上是必需品,没了它,您还真是寸步难行。官方文档包含了一个产品最直接也最全面的说明,在微信公众平台技术文档中,详细说明了微信公众号开发的概念_微信公众号开发工具
获得硬盘ID(序列号、机器码)的C++代码源码_硬盘id获取 c++-程序员宅基地
文章浏览阅读612次。获得硬盘的序列号(ID/机器码)的C++源码_硬盘id获取 c++
随便推点
最长上升子序列优化(贪心+二分)(超级详细的讲解)-程序员宅基地
文章浏览阅读2.6k次,点赞20次,收藏27次。详细讲解优化的原理,并给出通俗的证明和简单的代码帮助你彻底掌握优化过程!!_最长上升子序列优化
AttributeError: module ‘tensorflow.compat.v1’ has no attribute ‘contrib’_attributeerror: module 'tensorflow' has no attribu-程序员宅基地
文章浏览阅读3.5k次,点赞4次,收藏22次。项目场景:提示:这里简述项目相关背景:AttributeError: module ‘tensorflow.compat.v1’ has no attribute ‘contrib’问题描述提示:这里描述项目中遇到的问题:公司的是3080显卡,跑tensorflow1.x的代码,最终的环境时tensorflow2.6的,运行会报这个错原因分析:提示:这里填写问题的分析:原因是tensorflow1.x的contrib包被整合进了三个包里(据这位大佬说:https://blog.csd_attributeerror: module 'tensorflow' has no attribute 'contrib
学成在线(一)项目介绍_学成在线项目怎么写成简历-程序员宅基地
文章浏览阅读3.4w次,点赞12次,收藏99次。CMS接口开发1 项目的功能构架1.1 项目背景1.2 功能模块1.3 项目原型2 项目的技术架构2.1技术架构2.2 技术栈2.3 开发步骤3 CMS需求分析3.1 什么是CMS3.2 静态门户工程搭建3.2.1 导入门户工程3.2.2 配置虚拟主机 在nginx中配置虚拟主机:3.2.3 SSI服务端包含技术3.3 CMS页面管理需求4 CMS服务端工程搭建注释也是必不可少的KaTeX数学公..._学成在线项目怎么写成简历
使用指针实现字符串拷贝_字符指针拷贝-程序员宅基地
文章浏览阅读488次。【代码】使用指针实现字符串拷贝。_字符指针拷贝
Qt自定义控件9:波浪进度条1_qt 波浪进度球-程序员宅基地
文章浏览阅读502次。Qt自定义控件8:波浪进度条1先看效果图:思路:利用QPaintPath画出封闭路径,填充颜色,圆弧使用正弦函数,根据横坐标递增,画出正弦函数线。关键代码:void WaterProgressBar1::paintEvent(QPaintEvent *event){ int width = this->width(); int height = this->h..._qt 波浪进度球
5G协议批量下载 python3_批量下载3gpp 协议-程序员宅基地
文章浏览阅读673次。最近需要3GPP的5G协议,手动一个一个下载比较麻烦,抽空用python3写了个下载程序,可以从3gpp的ftp服务器批量下载协议文件。3GPP协议下载地址:https://www.3gpp.org/ftp/Specs/archive/38_series/代码使用了线程池,可以多线程从3gpp下载协议。代码流程:1、首先从下载地址获取要下载的所有文件的 文件名、url、大小、日期、本地存储地址,写入ini文件2、读取ini文件中的信息,使用线程池进行文件下载#coding:utf-_批量下载3gpp 协议