实时计算 Flink性能调优_rps flink-程序员宅基地
自动配置调优
实时计算 Flink新增自动调优功能autoconf。能够在流作业以及上下游性能达到稳定的前提下,根据您作业的历史运行状况,重新分配各算子资源和并发数,达到优化作业的目的。更多详细说明请您参阅自动配置调优。
首次智能调优
- 创建一个作业。如何创建作业请参看快速入门。
-
上线作业。选择智能推荐配置,指定使用CU数为系统默认,不填即可。点击下一步。
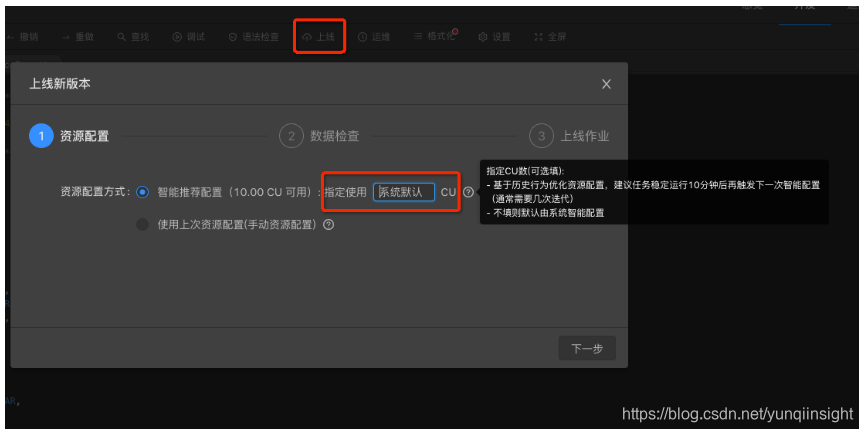
-
数据检查,预估消耗CU数。
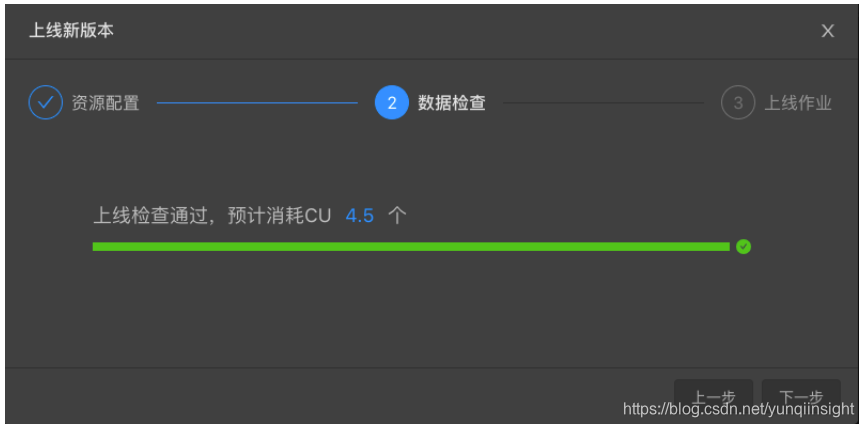
-
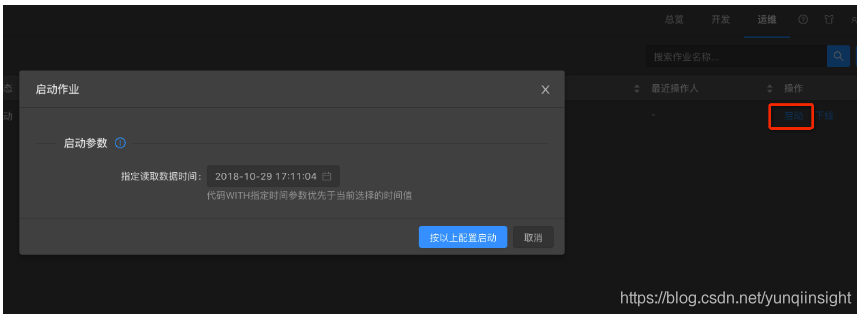
在运维界面启动作业,根据实际业务需要指定读取数据时间。

说明:实时计算作业启动时候需要您指定启动时间。实际上就是从源头数据存储的指定时间点开始读取数据。指定读取数据时间需要在作业启动之前。例如,设置启动时间为1小时之前。
-
待作业稳定运行10分钟后,且以下状态符合要求,即可开始下一次性能调优。
- 运行信息拓扑图中IN_Q不为100%。

- 数据输入RPS符合预期。
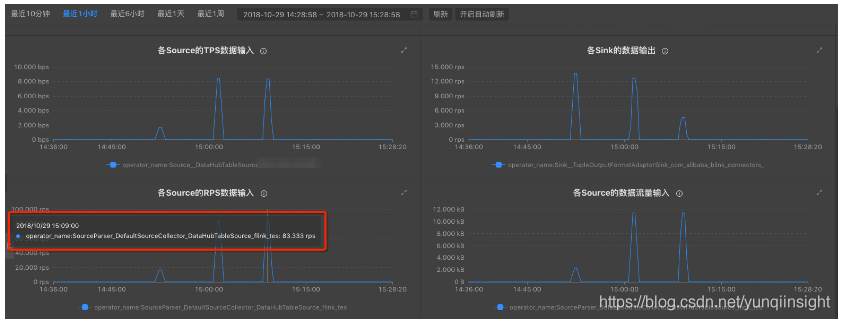
- 运行信息拓扑图中IN_Q不为100%。
非首次性能调优
-
停止>下线作业。
-
重新上线作业。选择智能推荐配置,指定使用CU数为系统默认,不填即可。点击下一步。
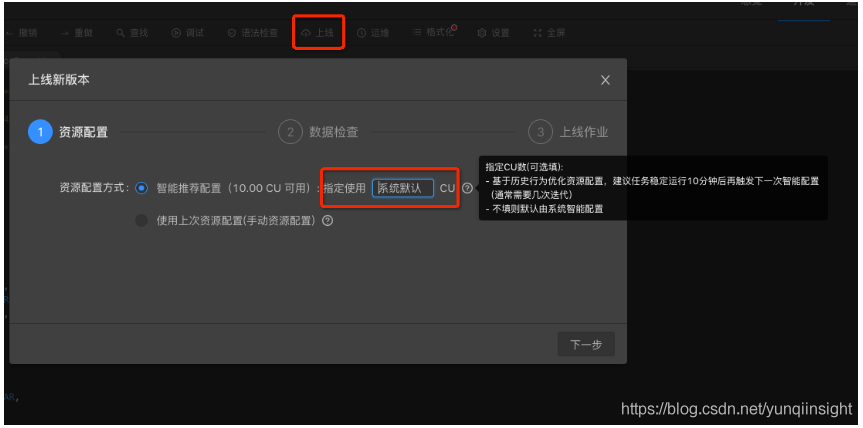
-
数据检查,再次预估消耗CU数。
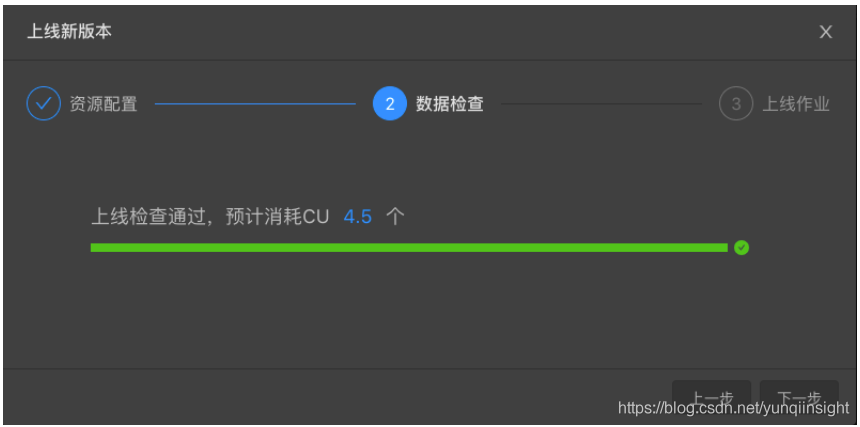
-
在运维界面启动作业,待作业稳定运行十分钟后,即可再一次性能调优。
说明:
- 自动配置调优一般需要3到5次才能达到理想的调优效果。请完成首次性能调优后,重复非首次性能调优过程多次。
- 每次调优前,请确保足够的作业运行时长,建议10分钟以上。
- 指定CU数(参考值) = 实际消耗CU数*目标RPS/当前RPS。
- 实际消耗CU数:上一次作业运行时实际消耗CU
- 目标RPS:输入流数据的实际RPS(或QPS)
- 当前RPS:上一次作业运行时实际的输入RPS
手动配置调优
手动配置调优可以分以下三个类型。
- 资源调优
- 作业参数调优
- 上下游参数调优
资源调优
资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。
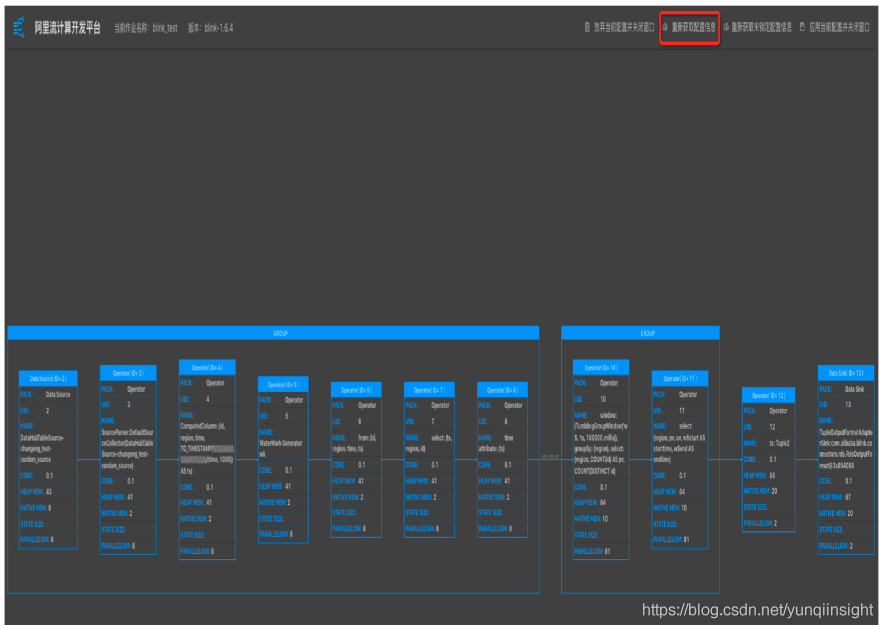
性能瓶颈节点为Vertex拓扑图最下游中参数IN_Q值为100%的一个或者多个节点。如下图,7号节点为性能瓶颈节点。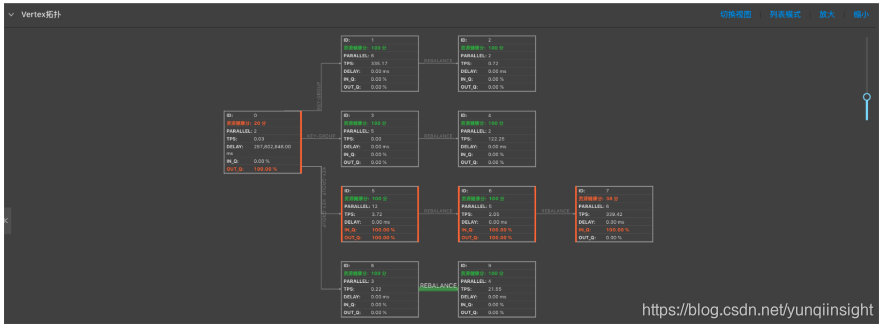
性能瓶颈的可分为三类。
- 并发(parallelism)不足
- CPU(core)不足
- MEM(heap_memory)不足
如下图,7号节点的性能瓶颈是资源(CPU和/或MEM)配置不足所导致。
说明:判断性能瓶颈因素方法
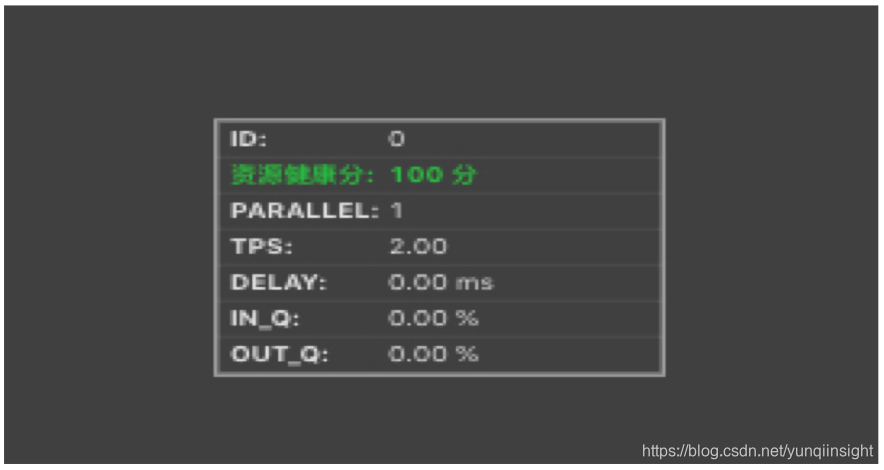
- 瓶颈节点的资源健康分为100,则认为资源已经合理分配,性能瓶颈是并发数不足所导致。
- 瓶颈节点的资源健康分低于100,则认为性能瓶颈是单个并发的资源(CPU和/或MEM)配置不足所导致。
- 无持续反压,但资源健康分低于100,仅表明单个并发的资源使用率较高,但暂不影响作业性能,可暂不做调优。
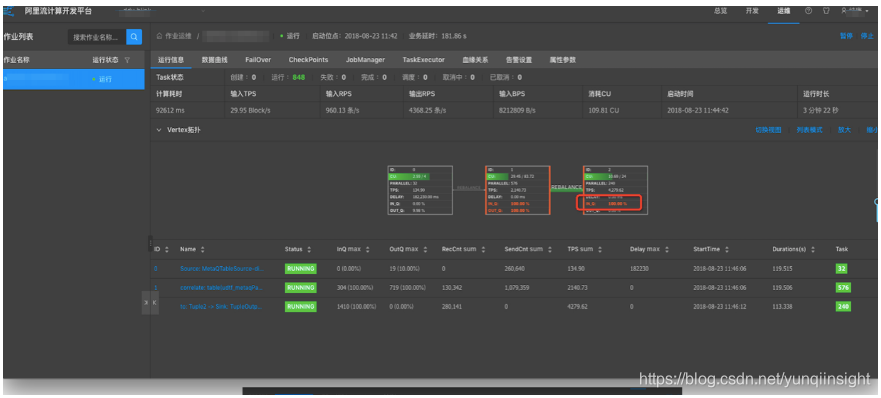
通过作业运维页面中Metrics Graph功能,进一步判断性能瓶颈是CPU不足还是MEM不足。步骤如下。
-
运维界面中,点击TaskExecutor,找到性能瓶颈节点ID,点击查看详情。
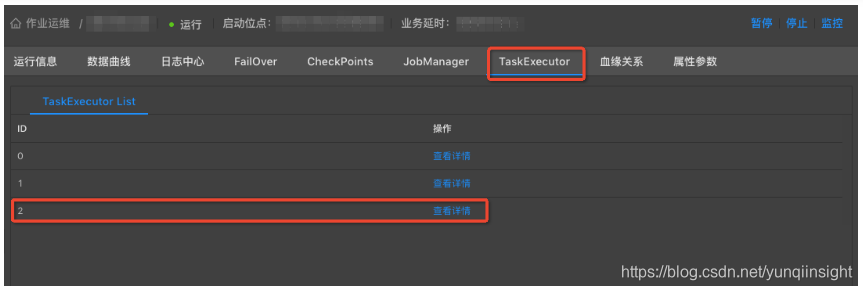
-
选择Metrics Graph,根据曲线图判断CPU或者MEM是否配置不足(很多情况下两者同时不足)。

完成了性能瓶颈因素判断后,点击开发>基本属性>跳转到新窗口配置,开始调整资源配置。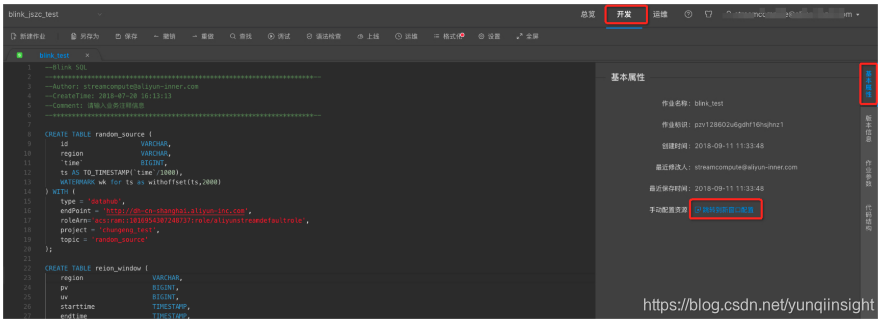
-
点击GROUP框,进入批量修改Operator数据窗口。
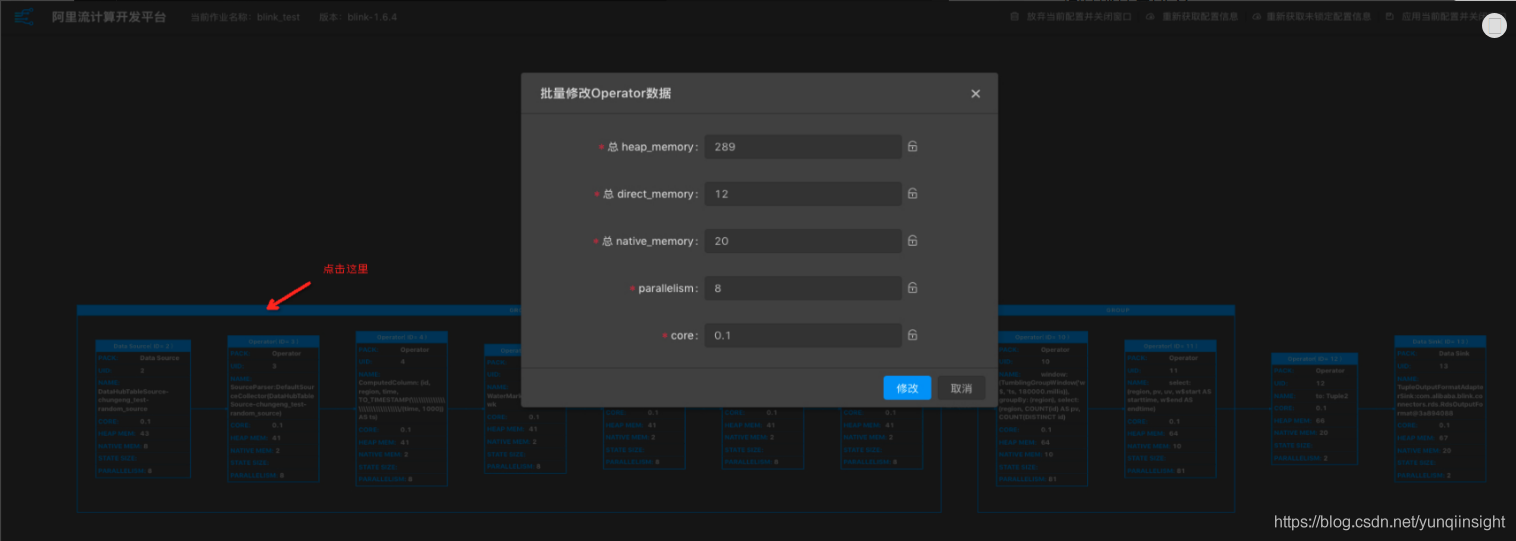
说明:
- GROUP内所有的operator具有相同的并发数。
- GROUP的core为所有operator的最大值。
- GROUP的_memory为所有operator之和。
- 建议单个Job维度的CPU:MEM=1:4,即1个核对应4G内存。
-
配置修改完成后点击应用当前配置并关闭窗口。
-
点击Operator框,进入修改Operator数据窗口。
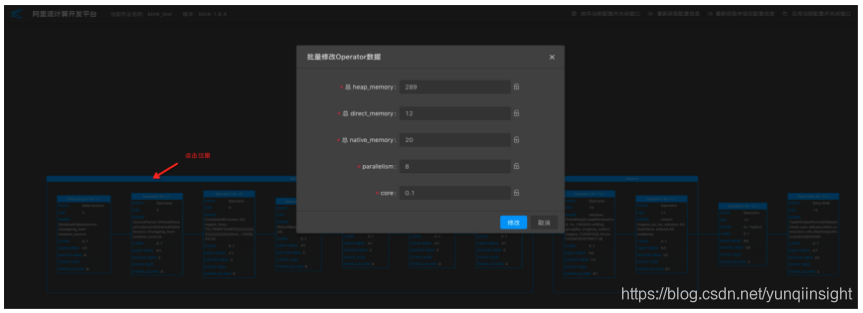
-
配置修改完成后点击应用当前配置并关闭窗口。
您只需调整parallelism、core和heap_memory三个参数,即能满足大部分的资源调优需求。
- Parallelism
- source节点
资源根据上游Partition数来。例如source的个数是16,那么source的并发可以配置为16、8、4等。不能超过16。 - 中间节点
根据预估的QPS计算。对于数据量较小的任务,设置和source相同的并发度。QPS高的任务,可以配置更大的并发数,例如64、128、或者256。 - sink节点
并发度和下游存储的Partition数相关,一般是下游Partition个数的2~3倍。如果配置太大会导致数据写入超时或失败。例如,下游sink的个数是16,那么sink的并发最大可以配置48。
- source节点
- Core
即CPU,根据实际CPU使用比例配置,建议配置值为0.25,可大于1。 - Heap_memory
堆内存。根据实际内存使用状况进行配置。 - 其他参数
- state_size:默认为0,group by、join、over、window等operator需设置为1。
- direct_memory:JVM堆外内存,默认值为0, 建议不要修改。
- native_memory:JVM堆外内存,默认值为0,建议修改为10MB。
- chainingStrategy:chain策略,根据实际需要修改。
作业参数调优
-
在开发页面的右侧选择作业参数。
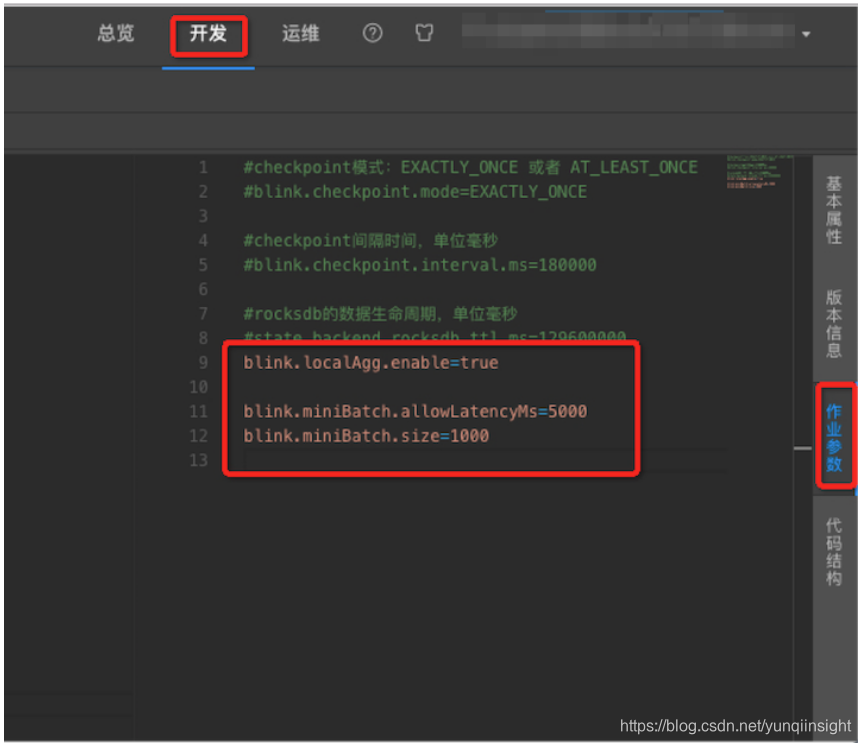
-
输入调优语句。
| 优化 | 解决问题 | 调优语句 |
|---|---|---|
| MiniBatch | 提升吞吐,降低对下游压力仅对Group by有效。 | blink.miniBatch.allowLatencyMs=5000blink.miniBatch.size=1000 |
| LocalGlobal | 优化数据倾斜问题 | blink.localAgg.enable=true |
| TTL | 设置State状态时间 | 1.x:state.backend.rocksdb.ttl.ms=1296000002.x:state.backend.niagara.ttl.ms=129600000其中,1.x 表示需显式开启,2.x 表示默认开启。 |
注意:添加或删除MiniBatch或LocalGlobal参数,job状态会丢失,修改值大小状态不会丢失。
上下游参数调优
实时计算 Flink可以在with参数内设置相应的参数,达到调优上下游存储性能的目的。
调优步骤:
- 进入作业的开发界面。
- 确定需要调优的上下游引用表的语句。
- 在with参数中配置相应的调优参数。如下图。

实时计算 Flink的每条数据均会触发上下游存储的读写,会对上下游存储形成性能压力。可以通过设置batchsize,批量的读写上下游存储数据来降低对上下游存储的压力。
| 名字 | 参数 | 详情 | 设置参数值 |
|---|---|---|---|
| Datahub源表 | batchReadSize | 单次读取条数 | 可选,默认为10 |
| Datahub结果表 | batchSize | 单次写入条数 | 可选,默认为300 |
| 日志服务源表 | batchGetSize | 单次读取logGroup条数 | 可选,默认为10 |
| ADB结果表 | batchSize | 每次写入的批次大小 | 可选,默认为1000 |
| RDS结果表 | batchSize | 每次写入的批次大小 | 可选,默认为50 |
注意: 添加、修改或者删除以上参数后,作业必须停止-启动后,调优才能生效。
| 名字 | 参数 | 详情 | 设置参数值 |
|---|---|---|---|
| RDS维表 | Cache | 缓存策略 | 默认值为None,可选LRU、ALL。 |
| RDS维表 | cacheSize | 缓存大小 | 默认值为None,可选LRU、ALL。 |
| RDS维表 | cacheTTLMs | 缓存超时时间 | 默认值为None,可选LRU、ALL。 |
| OTS维表 | Cache | 缓存策略 | 默认值为None, 可选LRU,不支持ALL。 |
| OTS维表 | cacheSize | 缓存大小 | 默认值为None, 可选LRU,不支持ALL。 |
| OTS维表 | cacheTTLMs | 缓存超时时间 | 默认值为None, 可选LRU,不支持ALL。 |
注意: 添加、修改或者删除以上参数后,作业必须停止-启动后,调优才能生效。
手动配置调优流程
- 资源调优、作业参数调优、上下游参数调优
- 开发上线作业
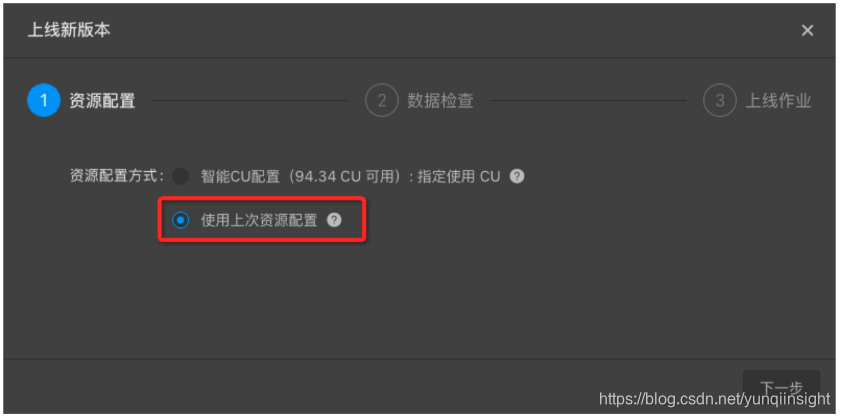
- 资源配置方式:使用上次资源配置
- 数据检查
- 上线
说明:完成资源、作业参数、上下游参数调优后,手动配置调优后续的步骤与自动配置调优基本一致。区别在于资源配置环节需要选择使用上次资源配置。
FAQ
A:可能性1:首次自动配置时指定了CU数,但指定的CU数太小(比如小于自动配置默认算法的建议值,多见于作业比较复杂的情况),建议首次自动配置时不指定CU数。
可能性2:默认算法建议的CU数或指定的CU数超过了项目当前可用的CU数,建议扩容。
Q:Vertex拓扑中看不到持续反压,但延迟却非常大,为什么?
A:可能性1:若延时直线上升,需考虑是否上游source中部分partition中没有新的数据,因为目前delay统计的是所有partition的延时最大值。
可能性2:Vertex拓扑中看不到持续反压,那么性能瓶颈点可能出现在source节点。因为source节点没有输入缓存队列,即使有性能问题,IN_Q也永远为0(同样,sink节点的OUT_Q也永远为0)。
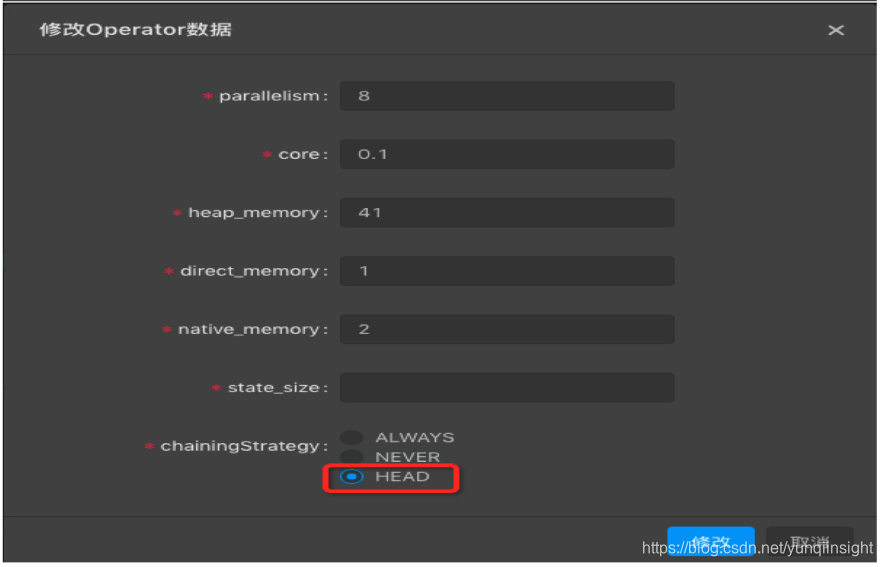
解决方案:通过手动配置调优,将source节点(GROUP)中的operator中chainingStrategy修改为HEAD,将其从GROUP中拆解出来。然后上线运行后再看具体是哪个节点是性能瓶颈节点,若依然看不到性能瓶颈节点,则可能是因为上游source吞吐不够,需考虑增加source的batchsize或增加上游source的shard数。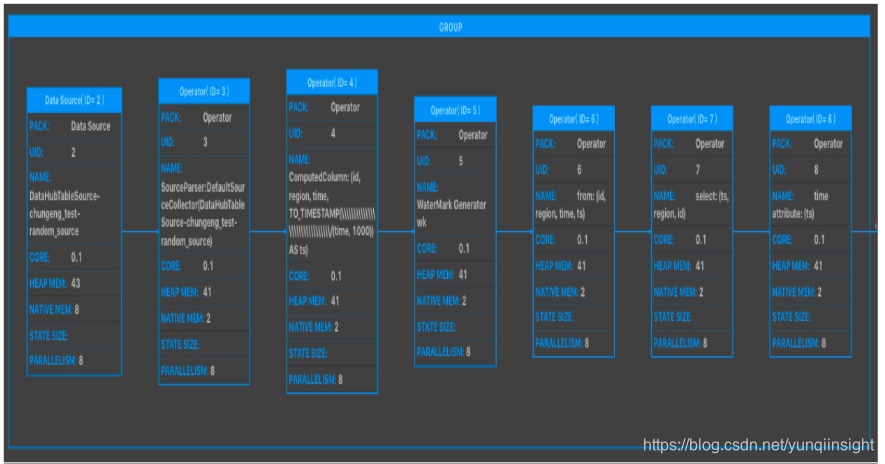
A:Vertex拓扑中某些节点的IN_Q持续为100%则存在持续反压情况,最后一个(或多个)IN_Q为100%的节点为性能瓶颈点。如下示例: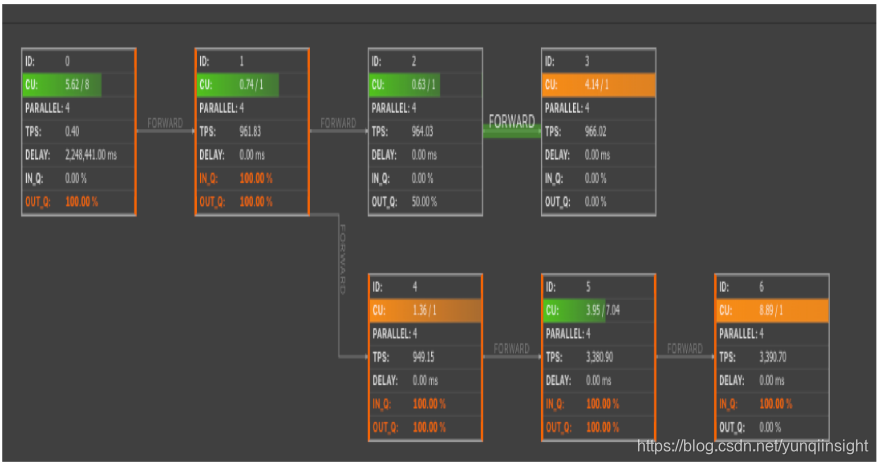
上图存在反压,瓶颈在6号节点。
上图存在反压,瓶颈在2号节点。
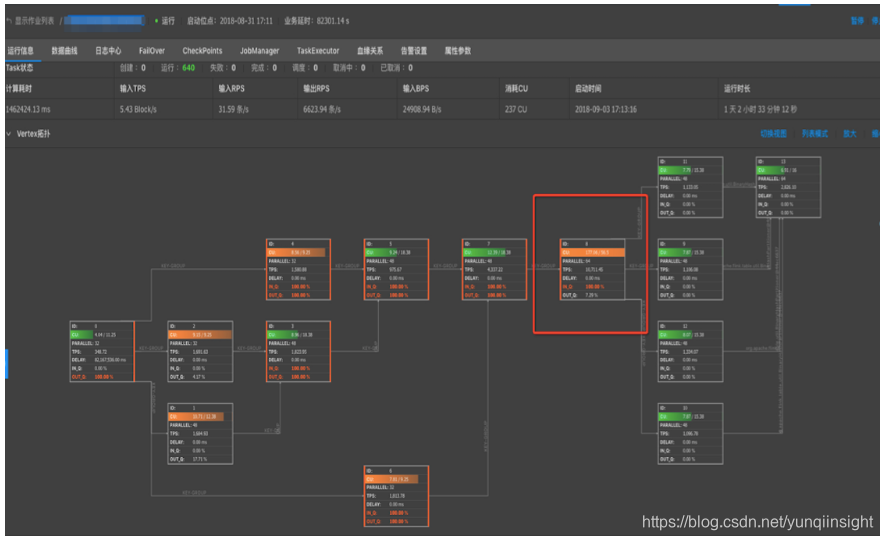
上图存在反压,瓶颈在8号节点。
上图可能存在节点,瓶颈在0号节点。
A:(1)表象上看,某些节点不论增加多大的并发仍存在性能瓶颈,则可能存在数据倾斜。
(2)在Vertex拓扑中点击疑似存在数据倾斜的节点(一般为性能瓶颈节点),进入SubTask List界面,重点观察RecvCnt和InQueue,若各ID对应的RecvCnt值差异较大(一般超过1个数量级)则认为存在数据倾斜,若个别ID的InQueue长期为100%,则认为可能存在数据倾斜。
解决方案:请您参看GROUP BY 数据出现热点、数据倾斜。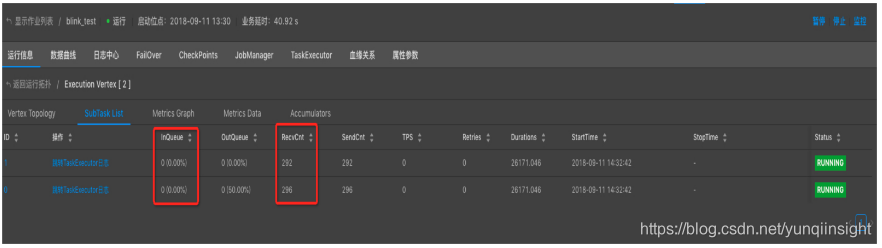
Q: 上线时指定15CU,但是上线后实际消耗仅为10CU,什么原因?
A:这种问题一般发生在Vertex只有一个节点的情况,此时由于source上游的物理表的shard数为1,Flink要求source的并发不能超过上游shard数,导致无法增加并发,因此亦无法增加到指定的CU数。
解决方案:
- 增加上游物理表的shard数。
- 将ID0的节点中的operator拆开,将source节点(GROUP)中的operator chainingStrategy修改为HEAD,将其从GROUP中拆解出来,然后手动配置调优。
Q: 上线时出现如左上图的告警,或出现诸如“Cannot set chaining strategy on Union Transformation”错误,如何处理?
A:这是由于作业的SQL有改动,导致DAG改变。
解决方案:通过重新获取配置解决,开发-基本属性-跳转到新窗口配置-重新获取配置信息。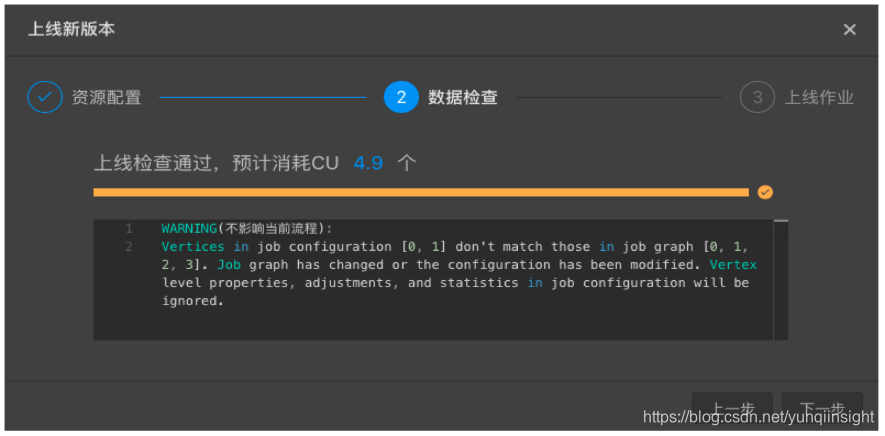
原文链接
本文为云栖社区原创内容,未经允许不得转载。
智能推荐
已知num为无符号十进制整数,请写一非递归算法,该算法输出num对应的r进制的各位数字。要求算法中用到的栈采用线性链表存储结构(1<r<10)。-程序员宅基地
文章浏览阅读74次。思路:num%r得到末位r进制数,num/r得到num去掉末位r进制数后的数字。得到的末位r进制数采用头插法插入链表中,更新num的值,循环计算,直到num为0,最后输出链表。//重置,s指针与头指针指向同一处。//更新num的值,至num为0退出循环。//末位r进制数存入s数据域中。//头插法插入链表中(无头结点)//定义头指针为空,s指针。= NULL) //s不为空,输出链表,栈先入后出。
开始报名!CW32开发者扶持计划正式进行,将助力中国的大学教育及人才培养_cw32开发者扶持计划申请-程序员宅基地
文章浏览阅读176次。武汉芯源半导体积极参与推动中国的大学教育改革以及注重电子行业的人才培养,建立以企业为主体、市场为导向、产学研深度融合的技术创新体系。2023年3月,武汉芯源半导体开发者扶持计划正式开始进行,以打造更为丰富的CW32生态社区。_cw32开发者扶持计划申请
希捷硬盘开机不识别,进入系统后自动扫描硬件以识别显示_st2000dm001不认盘-程序员宅基地
文章浏览阅读5.7k次。2014年底买的一块2TB希捷机械硬盘ST2000DM001-1ER164,用了两年更换了主板、CPU等,后来出现开机不识别的情况,具体表现为:关机后开机,找不到硬盘,就进入BIOS了,只要在BIOS状态下待机半分钟左右再重启,硬盘就会出现。进入系统后,重启(这个过程中主板对硬盘始终处于供电状态),也不会出现不识别硬盘的现象。就好像是硬盘或主板上某个电容坏了一样,刚开始给硬盘通电的N秒钟内电容未能..._st2000dm001不认盘
ADO.NET包含主要对象以及其作用-程序员宅基地
文章浏览阅读1.5k次。ADO.NET的数据源不单单是DB,也可以是XML、ExcelADO.NET连接数据源有两种交互模式:连接模式和断开模式两个对应的组件:数据提供程序(数据提供者)&DataSetSqlConnectionStringBuilder——连接字符串Connection对象用于开启程序和数据库之间的连接public SqlConnection c..._列举ado.net在操作数据库时,常用的对象及作用
Android 自定义对话框不能铺满全屏_android dialog宽度不铺满-程序员宅基地
文章浏览阅读113次。【代码】Android 自定义对话框不能铺满全屏。_android dialog宽度不铺满
Redis的主从集群与哨兵模式_redis的主从和哨兵集群-程序员宅基地
文章浏览阅读331次。Redis的主从集群与哨兵模式Redis的主从模式全量同步增量同步Redis主从同步策略流程redis主从部署环境哨兵模式原理哨兵模式概述哨兵模式的作用哨兵模式项目部署Redis的主从模式1、Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。2、为了分担读压力,Redis支持主从复制,保证主数据库的数据内容和从数据库的内容完全一致。3、Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。全量同步Redis全量复制一般发_redis的主从和哨兵集群
随便推点
mysql utf-8的作用_为什么不建议在MySQL中使用UTF-8-程序员宅基地
文章浏览阅读116次。作者:brightwang原文:https://www.jianshu.com/p/ab9aa8d4df7d最近我遇到了一个bug,我试着通过Rails在以“utf8”编码的MariaDB中保存一个UTF-8字符串,然后出现了一个离奇的错误:Incorrect string value: ‘ð 我用的是UTF-8编码的客户端,服务器也是UTF-8编码的,数据库也是,就连要保存的这个字符串“????..._mysql utf8的作用
MATLAB中对多张图片进行对比画图操作(包括RGB直方图、高斯+USM锐化后的图、HSV空间分量图及均衡化后的图)_matlab图像比较-程序员宅基地
文章浏览阅读278次。毕业这么久了,最近闲来准备把毕设过程中的代码整理公开一下,所有代码其实都是网上找的,但都是经过调试能跑通的,希望对需要的人有用。PS:里边很多注释不讲什么意思了,能看懂的自然能看懂。_matlab图像比较
16.libgdx根据配置文件生成布局(未完)-程序员宅基地
文章浏览阅读73次。思路: screen分为普通和复杂两种,普通的功能大部分是页面跳转以及简单的crud数据,复杂的单独弄出来 跳转普通的screen,直接根据配置文件调整设置<layouts> <loyout screenId="0" bg="bg_start" name="start" defaultWinId="" bgm="" remark=""> ..._libgdx ui 布局
playwright-python 处理Text input、Checkboxs 和 radio buttons(三)_playwright checkbox-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏13次。playwright-python 处理Text input和Checkboxs 和 radio buttonsText input输入框输入元素,直接用fill方法即可,支持 ,,[contenteditable] 和<label>这些标签,如下代码:page.fill('#name', 'Peter');# 日期输入page.fill('#date', '2020-02-02')# 时间输入page.fill('#time', '13-15')# 本地日期时间输入p_playwright checkbox
windows10使用Cygwin64安装PHP Swoole扩展_win10 php 安装swoole-程序员宅基地
文章浏览阅读596次,点赞5次,收藏6次。这是我看到最最详细的安装说明文章了,必须要给赞!学习了,也配置了,成功的一批!真不知道还有什么可补充的了,在此做个推广,喜欢的小伙伴,走起!_win10 php 安装swoole
angular2里引入flexible.js(rem的布局)_angular 使用rem-程序员宅基地
文章浏览阅读1k次。今天想实现页面的自适应,本来用的是栅格,但效果不理想,就想起了rem布局。以前使用rem布局,都是在原生html里,还没在框架里使用过,百度没百度出来,就自己琢磨,不知道方法规范不规范,反正成功了,操作如下:1、下载flexible.js2、引入到angular项目里3、根据自己的需要修改细节3.1、在flexible.js里修改每份的像素,3.2、引入cssrem插件,在设置里设..._angular 使用rem