Oracle数据学习笔记六——Oracle数据库的sql优化_创建plustrace角色-程序员宅基地
实验六 Sql优化与实践
一、前提概要
为什么要Sql优化?事实上,在实际运用场景中,若开发的时候写了一些慢sql,数据量小的时候可能还好,一旦数据量上来了,查询效能极低,并且请求次数过多的话很可能会因为这一个慢sql把你整个系统拖垮,不能正常对外提供服务,因此要进行sql优化。
事实上,SQL优化有许多方法,本文只介绍其中的两种:
批处理方式和索引方式
二、环境准备
2.1 事先操作
#启动监听
lsnrctl start
#导入实例
export ORACLE_SID=orcl
#以数据库管理员身份登录
sqlplus / as sysdba
2.2创建PlusTrace角色
角色plustrace是Oracle数据自带一个角色,他由$ORACLE_HOME/sqlplus/admin/路径下的plustrce.sql脚本执行得来,如图:
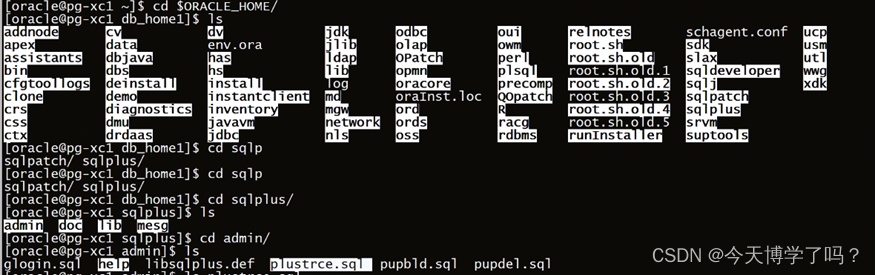
随后在SQL>命令行中执行plustrce.sql脚本,用@关键字
@/u01/app/oracle/product/19.2.0/db_home1/sqlplus/admin/plustrce.sql
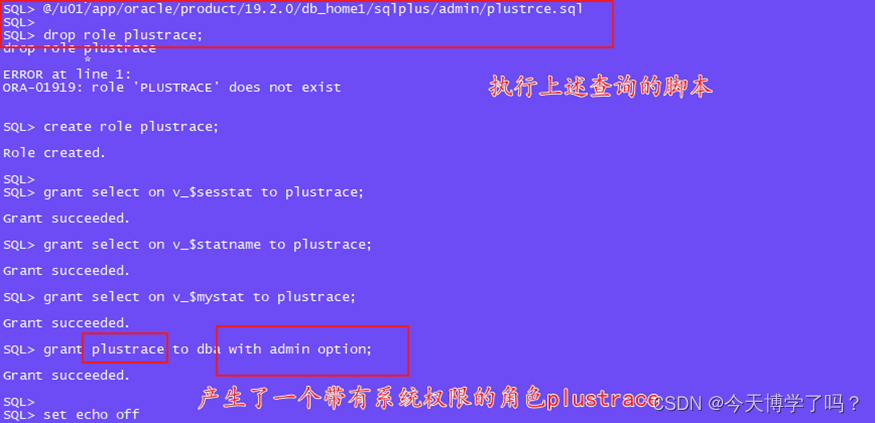
如此,产生了一个角色plustrace
2.3 创建用户并赋予权利
#创建用户txp
grant connect,resource to txp identified by txp;
grant connect,resource to ly identified by ly;
#将角色plustrace的权利赋予txp
grant plustrace to txp;
grant plustrace to ly;
#将表空间无限使用权赋予
grant unlimited tablespace to txp;
grant unlimited tablespace to ly;

2.4 建表
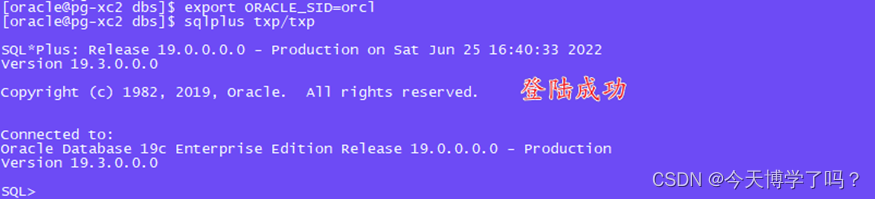
2.4.1登录txp用户
注:这里的用户是上文所创建并赋予完权限的用户
sqlplus txp/txp
2.4.2建表
CREATE TABLE EMP
(EMPNO NUMBER(4),
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2));

2.4.3插入数据
#插入多条数据
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO EMP VALUES
(7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO EMP VALUES
(7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO EMP VALUES
(7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO EMP VALUES
(7788,'SCOTT','ANALYST',7566,to_date('13-6-87','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES
(7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO EMP VALUES
(7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO EMP VALUES
(7876,'ADAMS','CLERK',7788,to_date('13-JUL-87')-51,1100,NULL,20);
INSERT INTO EMP VALUES
(7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO EMP VALUES
(7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES
(7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);
#一定要commit提交
commit;
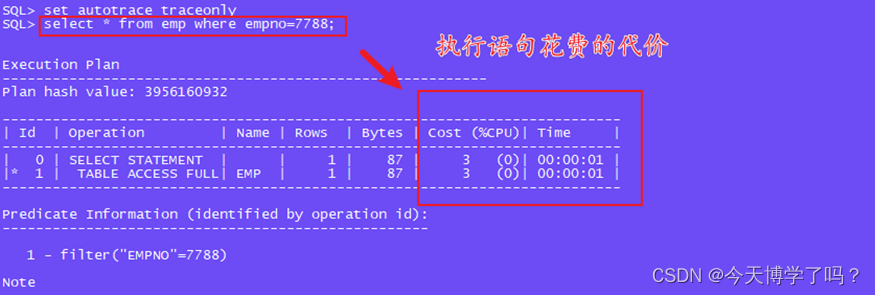
2.5查看执行计划
#查看语句花费的代价
set autotrace traceonly
select * from emp where empno=7788;
2.6创建一张新表
#子查询创建新表
create table emp2 as select * from emp where 1=2;

#为接下来防止插入数据做准备
alter table emp2 modify empno number(9);
alter table emp2 modify ENAME varchar2(20);

2.7往表插入大量记录
#开启一个语句块
begin
for i in 1..50000 loop
insert into emp2
values (i,'orcl'||i,'CLERK',7698,sysdate,3000,1000,10);
end loop;
commit;
end;
/

注:大量的数据插入可能会导致内存空间不足,谨慎插入数据!
至此,准备工作完成
三、SQL优化
3.1 批量处理方式优化
3.1.1概要
redolog:重做日志,在操作⼀条数据之前需要记录redo log,然后再修改数据,因而在数据操作后会产生大量的redolog
undolog:撤销日志,为了保证读⼀致性,在更新数据到提交之前,Oracle会先把旧数据写⼊到undolog中,因而也会产生大量数据在磁盘中
因而大量数据产生磁盘中,全盘扫描(full)故而花费更大的代价去执行查询语句
针对这个问题,故出现以下优化思路:
1.更少的产生undo数据->阶段性的提交数据
2.产生更少的redolog -> nologging
3.取消归档模式
因此,接下来一一执行
3.1.2 调整优化
1.改变数据库运行方式
#关闭数据库
shutdown abort
#启动到mount状态
startup mount
#改变模式
alter database noarchivelog;
alter database open;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hm1tn0aA-1657162534808)(C:\Users\22450\Desktop\生产实习截图\day5\image-20220625172911891.png)]](https://img-blog.csdnimg.cn/699902d1edb843228b033db30407fca8.png)
2.调整表,少产生redolog
注:这里txp用户需要重新登录,因为第一步数据库shutdown abort异常关闭
#重新登录
export ORACLE_SID=orcl
sqlplus txp/txp
#修改模式
alter table emp2 nologging;

3.阶段性提交,少产生undo数据
begin
for i in 1..50000 loop
insert into emp2
values (i,'orcl'||i,'CLERK',7698,sysdate,3000,1000,10);
if mod(i,1000) =0 then
commit; #阶段性提交
end if;
end loop;
end;
/
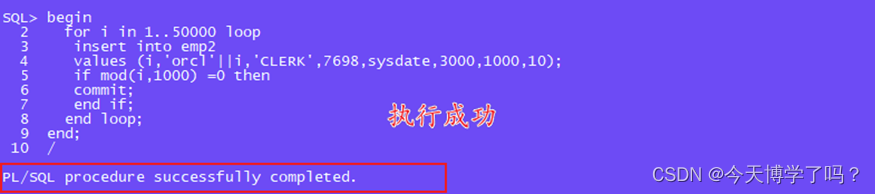
注:可以看到这里的插入速度还是不怎么慢,因为受实验环境受限数据量插入不大,可自行调整
4.删除emp2数据
truncate table emp2;

5.打开计时器
set timin on
#目的是查看执行时间
6.执行修改后的sql语句
select * from emp where empno=7788;

注:若环境准备步骤中插入的数据量足够多,几十万甚至几千万,插入的时候会等待很长时间,可以用下面的代码来观察数据文件增长情况,undo表空间的数据文件
#查看增长情况
set linesize 120
col name for a50
select name,bytes/1024/1024 from v$datafile;
#查看emp2表数据增长情况
select count(*) from emp2;
7.还原原来环境,与优化环境做对比
alter table emp2 logging;

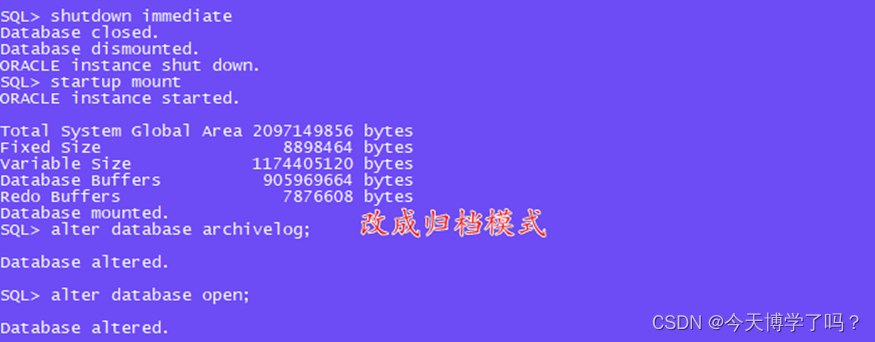
8.改成归档模式
#关闭数据库
shutdown immediate
#启动到mount状态
startup mount
#修改模式
alter database archivelog;
alter database open;
9.操作前清理emp2:
truncate table emp2;

10.重新登录操作,与优化作对比
注:这里是因为改变了模式,数据库关闭,需要重新登录txp用户
#打开计时器
set timin on
#插入数据
begin
for i in 1..50000 loop
insert into emp2
values (i,'orcl'||i,'CLERK',7698,sysdate,3000,1000,10);
end loop;
commit; #注意:这里没有采用阶段性的提交数据
end;
/
#注意前后对比两种插入花费的时间开销
补充说明:由于实验本人实验环境的数据库的容量有限,为防止导入大量数据占据恢复区空间而导致数据库崩溃,这里作者导入的数据量是偏少的,因此能察觉到的变化很小。事实上,若插入的数据在几十万条或者几千万条的时候,优化和不优化前后执行的插入数据语句执行速度,有着明显的快慢区别
至此,批处理优化方法介绍完毕
3.2 建立索引的优化方法
3.2.1概要
在日常开发中,select查询sql很慢,大部分都可以通过添加索引来解决。但索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
值得一提的是,索引是Oracle优化中效果最明显的方式
3.2.2 调整优化
1.未创索引前
#查看执行计划
set autotrace traceonly
#执行查询语句
SQL> select * from emp2 where empno=7788;
注:索引优化主要优化查询select语句,因此用select语句可更清楚看清前后的对比
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S3sN8FtY-1657162534814)(C:\Users\22450\Desktop\生产实习截图\day5\image-20220625182333560.png)]](https://img-blog.csdnimg.cn/6265e267470348de8926bf709ccbcab7.png)
2.创建索引后
#创建索引
create index emp2_empno_ind on emp2 (empno);
#让计算机为表产生索引(采用估算的方法)
analyze table emp2 estimate statistics;
#格式化大小 正确显示
set linesize 120
#再次查看执行计划
select * from emp2 where empno=7788;

查看查询代价
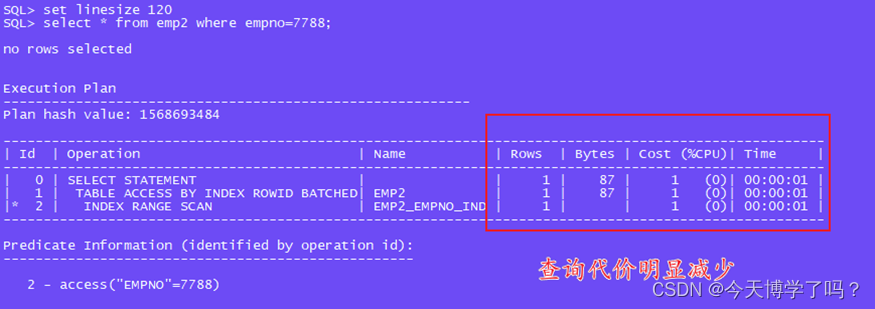
可以看出,索引创建前后,select查询的花销是有大小之分的
补:若数据量足够多的时候,select查询的代价在建立索引前后区别更加明显
智能推荐
python3 os.system 异步执行_Python执行系统命令的方法 os.system(),os.popen(),commands-程序员宅基地
文章浏览阅读3.8k次。最近在做那个测试框架的时候发现 Python 的另一个获得系统执行命令的返回值和输出的类。1.最开始的时候用 Python 学会了 os.system() 。这个方法是拥塞的。os.system('ping www.baidu.com')2.通过 os.popen() 返回的是 file read 的对象,对其进行读取 read() 的操作可以看到执行的输出。这个方法是后台执行,不影响后续脚本运行..._os.system异步执行
CM+CDH安装搭建全过程(总结版)_cloudera manager server gc cpu usage is at 10% or -程序员宅基地
文章浏览阅读2.9k次。目录第一次搭建CM、CDH第二次搭建CM、CDH搭建环境:搭建过程:报错过程:总结复盘:第三次搭建CM、CDH搭建环境:搭建过程:报错过程:总结复盘:第四次搭建CM、CDH搭建环境:搭建过程:报错过程:总结复盘:第一次搭建CM、CD..._cloudera manager server gc cpu usage is at 10% or more of total process time
内核开发调试printk_printk 头文件-程序员宅基地
文章浏览阅读706次。进行内核开发调试在进行驱动开发的过程中往往要打印一些信息来查看是否正确类似于printf,以下将介绍在内核开发常用的调试方法。.(第一次写文章,内容可能不咋样勿喷呀)内容一、printk介绍二、如何查看并修改消息级别在应用程序采用printf打印调试、内核驱动采用printk打印调试。printk函数打印数据到console缓冲区,打印的格式方类似printf。printk函数说明头文件:<linux/kernel.h>int printk(KERN_XXX const_printk 头文件
Kafka原理、部署与实践——深入理解Kafka的工作原理和使用场景,全面介绍Kafka在实际生产环境中的部署_kafka如何负载使用一台对外的机器-程序员宅基地
文章浏览阅读2.5k次。随着互联网的发展,网站的流量呈爆炸性增长,传统的基于关系型数据库的数据处理无法快速响应。而NoSQL技术如HBase、MongoDB等被广泛应用于分布式数据存储与处理,却没有提供像关系型数据库一样的ACID特性、JOIN操作及完整性约束。因此,很多公司或组织开始转向Apache Spark、Flink、Beam等新一代大数据处理框架来处理海量数据。然而,由于新一代大数据处理框架依赖于HDFS等文件系统,导致集群规模扩容困难、成本高昂。另一方面,云计算平台的出现让用户可以快速部署、扩展大数据处理集群。_kafka如何负载使用一台对外的机器
麒麟KYLINOS桌面操作系统2303上安装tigervnc_麒麟系统电脑安装vncserver-程序员宅基地
文章浏览阅读1.4k次。hello,大家好啊,今天给大家带来在麒麟桌面操作系统2303上安装tigervnc的文章,本篇文章给大家讲述如何安装并且远程连接使用,后面会给大家更新如何将tigervnc做成桌面图标点击即可开启及关闭,欢迎大家浏览分享转发。_麒麟系统电脑安装vncserver
EPS方圆预发机说明书-程序员宅基地
文章浏览阅读324次。预发机说明书_eps方圆预发机说明书
随便推点
Node.js_node可以使用什么命令 ,它会自动找到该文件下的start指令,执行入口文件。-程序员宅基地
文章浏览阅读280次。nodejs。_node可以使用什么命令 ,它会自动找到该文件下的start指令,执行入口文件。
linux图片相似度检测软件下载,移动端图像相似度算法选型-程序员宅基地
文章浏览阅读293次。概述电商场景中,卖家为获取流量,常常出现重复铺货现象,当用户发布上传图像或视频时,在客户端进行图像特征提取和指纹生成,再将其上传至云端指纹库对比后,找出相似图片,杜绝重复铺货造成的计算及存储资源浪费。该方法基于图像相似度计算,可广泛应用于安全、版权保护、电商等领域。摘要端上的图像相似度计算与传统图像相似度计算相比,对计算复杂度及检索效率有更高的要求。本文通过设计实验,对比三类图像相似度计算方法:感..._linux 图片相似度对比
java isprime函数_判断质数(isPrime)的方法——Java代码实现-程序员宅基地
文章浏览阅读3.8k次。判断质数(isPrime)的方法——Java代码实现/** 质数又称素数。一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数* 100以内质数表2 3 5 7 11 13 17 19 23 29 31 37 41 43 4753 59 61 67 71 73 79 83 89 97质数具有许多独特的性质:(1)质数p的约数只有两个:1和p。(2)初等数学基本定理:..._java isprime
2.小白学uvm验证 - uvm_objection 和 uvm_component_uvm_object accessor 参数的意义-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏41次。1. uvm_objection 和 uvm_component 基础 uvm_objection 和 uvm_component 是 uvm 中两大基础类,刚开始学习的时候,对两个东西认识不深,以为它们俩差不多,谁知道它两是一个是“爷爷”,一个是孙子的关系,两者贯穿整个 uvm 验证方法学。至于为什么要划分 uvm_object 和 uvm_component 呢,是因为前任在验证的过程中发..._uvm_object accessor 参数的意义
Url 访问大小写敏感问题解决-程序员宅基地
文章浏览阅读2.7k次。2019独角兽企业重金招聘Python工程师标准>>> ..._yii2 url 大小写
gin 渲染不同目录下的模板(支持多层目录)_gin 加载多层模板-程序员宅基地
文章浏览阅读6k次,点赞3次,收藏3次。一直在学着使用gin,今天试了下gin的模板渲染,一路比较坑。真要吐槽下某度,啥都没有。参考资料:https://www.bookstack.cn/read/gin-doc/response.mdhttps://juejin.im/post/5b026a4c6fb9a07aac24c122https://blog.csdn.net/moxiaomomo/article/details/..._gin 加载多层模板