FFM代码详解及python复现_挂载点名 ffmj2-程序员宅基地
摘要
原论文中FFM模型是使用C++实现的,在网上找了很多python版本的都有点乱,而且缺少注释。
这是一篇我看过的比较详细的用tensorflow实现的FFM模型
https://www.cnblogs.com/wkang/p/9788012.html
但是里面的代码部分都是截图,而且因为使用的是tensorflow,虽然代码编写便捷了很多,但是增加了阅读难度。
本文就用常用的库来实现一下FFM模型
一、FFM模型
1、导入库
import numpy as np
np.random.seed(0)
import math
from logistic import Logistic
这里的logistics是存储着一些运算函数的python文件,其实自己写也可以。
2、节点类
因为用list实现,所以要有节点类
class FFM_Node(object):
'''
通常x是高维稀疏向量,所以用链表来表示一个x,链表上的每个节点是个3元组(j,f,v)
'''
# 稀疏矩阵用元组存储节省存储空间
__slots__ = ['j', 'f', 'v'] # 按元组(而不是字典)的方式来存储类的成员属性
# 使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用, 对继承的子类是不起作用的:
def __init__(self, j, f, v):
'''
:param j: Feature index (0 to n-1)
:param f: Field index (0 to m-1)
:param v: value
'''
self.j = j
self.f = f
self.v = v
3、FFM模型构建
1、初始化
def __init__(self, m, n, k, eta, lambd):
'''
:param n: Number of features
:param m: Number of fields
:param k: Number of latent factors
:param eta: learning rate
:param lambd: regularization coefficient
'''
self.m = m
self.n = n
self.k = k
# 超参数
self.eta = eta
self.lambd = lambd
# 初始化三维权重矩阵w~U(0,1/sqrt(k))
self.w = np.random.rand(n, m, k) / math.sqrt(k)
# 初始化累积梯度平方和为,AdaGrad时要用到,防止除0异常
self.G = np.ones(shape=(n, m, k), dtype=np.float64)
self.log = Logistic()
logistic
import numpy as np
import math
from singleton import Singleton
class Logistic(object):
__metaclass__ = Singleton # 单例
def __init__(self):
exp_max = 10.0
self.exp_scale = 0.001
self.exp_intv = int(exp_max / self.exp_scale)
self.exp_table = [0.0] * self.exp_intv
for i in range(self.exp_intv):
x = self.exp_scale * i
exp = math.exp(x)
self.exp_table[i] = exp / (1.0 + exp)
def decide_by_table(self, x):
'''查表获得logistic的函数值'''
if x == 0:
return 0.5
i = int(np.nan_to_num(abs(x) / self.exp_scale))
y = self.exp_table[min(i, self.exp_intv - 1)]
if x > 0:
return y
else:
return 1.0 - y
def decide_by_tanh(self, x):
'''直接使用1.0 / (1.0 + np.exp(-x))容易发警告“RuntimeWarning: overflowencountered in exp”,
转换成如下等价形式后算法会更稳定
'''
return 0.5 * (1 + np.tanh(0.5 * x))
def decide(self, x):
'''原始的sigmoid函数'''
return 1.0 / (1.0 + np.exp(-x))
if __name__ == '__main__':
log = Logistic()
for x in np.arange(-20, 20, 1): # xrange()中的step不能是小数,所以只好手numpy.arange()
y = log.decide(x)
print(x, y, log.decide_by_tanh(x) - y, log.decide_by_table(x) - y)
2、参数计算
def phi(self, node_list):
'''
特征组合式的线性加权求和
:param node_list: 用链表存储x中的非0值
:return:
'''
z = 0.0
for a in range(len(node_list)):
node1 = node_list[a]
j1 = node1.j
f1 = node1.f
v1 = node1.v
for b in range(a + 1, len(node_list)):
node2 = node_list[b]
j2 = node2.j
f2 = node2.f
v2 = node2.v
w1 = self.w[j1, f2]
w2 = self.w[j2, f1]
z += np.dot(w1, w2) * v1 * v2 # dot是进行矩阵运算
return z
这里的z就是FFM中的非线性部分

关于vi,fj、vj,fi的构造
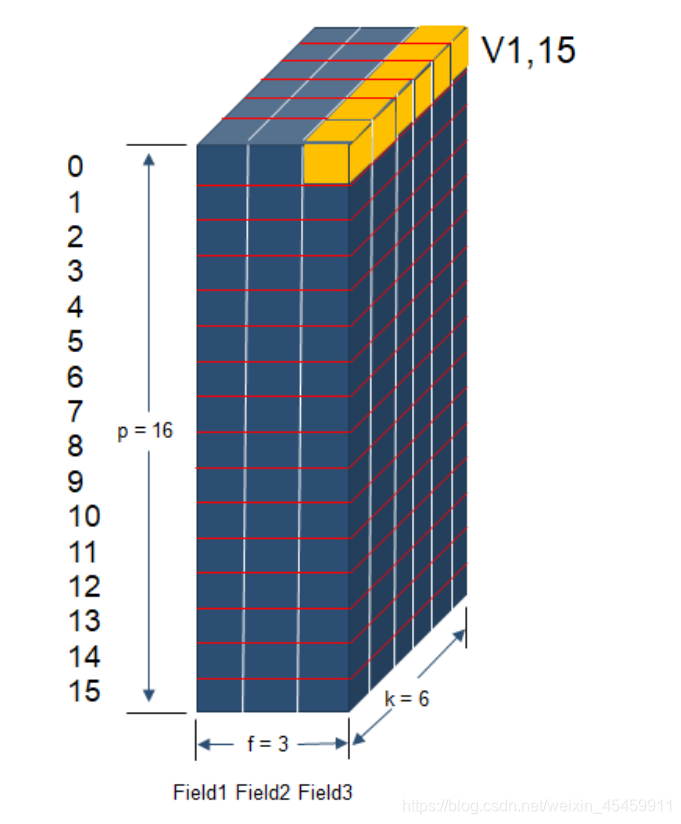
因为v 有p行,代表共有p个特征值,所以vifj = v[i, feature2field[j]],说人话就是第i个特征值在第j个特征值对应的field上的隐向量。
vjfi 的构造方法类似,所以vivj就可以求出来.然后就是把交叉项累加,然后 reshape 成(batch_size,1)的形状,以便与线性模型进行矩阵加法计算。
举个例子:
v1,15代表着第1个特征值在第15个特征值对应的field(field=2)上的隐向量。即v1,15 = v[1, feature2field[15]] = Vffm[1,2] ,其中v1,15的shape = (1,6)。
3、预测值
def predict(self, node_list):
'''
输入x,预测y的值
:param node_list: 用链表存储x中的非0值
:return:
'''
z = self.phi(node_list)
y = self.log.decide_by_tanh(z)
return y
4、更新参数
def sgd(self, node_list, y):
'''
根据一个样本来更新模型参数
:param node_list: 用链表存储x中的非0值
:param y: 正样本1,负样本-1
:return:
'''
kappa = -y / (1 + math.exp(y * self.phi(node_list)))
for a in range(len(node_list)):
node1 = node_list[a]
j1 = node1.j
f1 = node1.f
v1 = node1.v
for b in range(a + 1, len(node_list)):
node2 = node_list[b]
j2 = node2.j
f2 = node2.f
v2 = node2.v
c = kappa * v1 * v2
# self.w[j1,f2]和self.w[j2,f1]是向量,导致g_j1_f2和g_j2_f1也是向量
g_j1_f2 = self.lambd * self.w[j1, f2] + c * self.w[j2, f1]
g_j2_f1 = self.lambd * self.w[j2, f1] + c * self.w[j1, f2]
# 计算各个维度上的梯度累积平方和
self.G[j1, f2] += g_j1_f2 ** 2 # 所有G肯定是大于0的正数,因为初始化时G都为1
self.G[j2, f1] += g_j2_f1 ** 2
# AdaGrad
self.w[j1, f2] -= self.eta / np.sqrt(self.G[j1, f2]) * g_j1_f2 # sqrt(G)作为分母,所以G必须是大于0的正数
self.w[j2, f1] -= self.eta / np.sqrt(
self.G[j2, f1]) * g_j2_f1 # math.sqrt()只能接收一个数字作为参数,而numpy.sqrt()可以接收一个array作为参数,表示对array中的每个元素分别开方
5、训练
def train(self, sample_generator, max_echo, max_r2):
'''
根据一堆样本训练模型
:param sample_generator: 样本生成器,每次yield (node_list, y),node_list中存储的是x的非0值。通常x要事先做好归一化,即模长为1,这样精度会略微高一点
:param max_echo: 最大迭代次数
:param max_r2: 拟合系数r2达到阈值时即可终止学习
:return:
'''
for itr in range(max_echo):
print("echo", itr)
y_sum = 0.0
y_square_sum = 0.0
err_square_sum = 0.0 # 误差平方和
population = 0 # 样本总数
for node_list, y in sample_generator:
y = 0.0 if y == -1 else y # 真实的y取值为{-1,1},而预测的y位于(0,1),计算拟合效果时需要进行统一
self.sgd(node_list, y)
y_hat = self.predict(node_list)
y_sum += y
y_square_sum += y ** 2
err_square_sum += (y - y_hat) ** 2
population += 1
var_y = y_square_sum - y_sum * y_sum / population # y的方差
r2 = 1 - err_square_sum / var_y
print
"r2=", r2
if r2 > max_r2: # r2值越大说明拟合得越好
print
'r2 have reach', r2
break
6、序列化模型
def save_model(self, outfile):
'''
序列化模型
:param outfile:
:return:
'''
np.save(outfile, self.w)
7、加载模型
def load_model(self, infile):
'''
加载模型
:param infile:
:return:
'''
self.w = np.load(infile)
二、运行部分
import math
from ffm import FFM_Node, FFM
import re
class Sample(object):
def __init__(self, infile):
self.infile = infile
self.regex = re.compile("\\s+")
def __iter__(self):
with open(self.infile, 'r') as f_in:
for line in f_in:
arr = self.regex.split(line.strip())
if len(arr) >= 2:
y = float(arr[0])
assert math.fabs(y) == 1
node_list = []
square_sum = 0.0
for i in range(1, len(arr)):
brr = arr[i].split(",")
if len(brr) == 3:
j = int(brr[0])
f = int(brr[1])
v = float(brr[2])
square_sum += v * v
node_list.append(FFM_Node(j, f, v))
if square_sum > 0:
norm = math.sqrt(square_sum)
# 把模长缩放到1
normed_node_list = [FFM_Node(ele.j, ele.f, ele.v / norm) for ele in node_list]
yield (normed_node_list, y)
if __name__ == '__main__':
n = 5
m = 2
k = 2
train_file = "train.txt"
valid_file = "valid.txt"
model_file = "ffm.npy"
# 超参数
eta = 0.01
lambd = 1e-2
max_echo = 30
max_r2 = 0.9
# 训练模型,并保存模型参数
sample_generator = Sample(train_file)
ffm = FFM(m, n, k, eta, lambd)
ffm.train(sample_generator, max_echo, max_r2)
ffm.save_model(model_file)
# 加载模型,并计算在验证集上的拟合效果
ffm.load_model(model_file)
valid_generator = Sample(valid_file)
y_sum = 0.0
y_square_sum = 0.0
err_square_sum = 0.0 # 误差平方和
population = 0 # 样本总数
for node_list, y in valid_generator:
y = 0.0 if y == -1 else y # 真实的y取值为{-1,1},而预测的y位于(0,1),计算拟合效果时需要进行统一
y_hat = ffm.predict(node_list)
y_sum += y
y_square_sum += y ** 2
err_square_sum += (y - y_hat) ** 2
population += 1
var_y = y_square_sum - y_sum * y_sum / population # y的方差
r2 = 1 - err_square_sum / var_y
print("r2 on validation set is", r2)
完整代码请查看
https://github.com/testinWang/FFM/blob/master
智能推荐
SpringBoot项目引入外部jar包_springboot引入外部jar包-程序员宅基地
文章浏览阅读695次。SpringBoot项目引入外部jar包_springboot引入外部jar包
Java系列(面试必备):HashMap和Hashtable的区别!_java hashtable的优缺点-程序员宅基地
文章浏览阅读3.1k次,点赞19次,收藏84次。Java系列(面试必备):HashMap 和 Hashtable 的 6 个区别!前言今天博主将为大家分享:Java系列(面试必备):HashMap 和 Hashtable 的 6 个区别!不喜勿喷,如有异议欢迎讨论!首先推荐结合博主的这篇文章进行阅读===>Java系列(面试必备):简单的hashCode和equals面试题,有好多坑!HashMap 和 Hashtable 是 J..._java hashtable的优缺点
elasticSearch - es报错:exception [type=search_phase_execution_exception, reason=all shards failed]_elasticsearch exception [type=search_phase_executi-程序员宅基地
文章浏览阅读5.7k次。查询语句中,字段类型使用错误,在es中查询字段类型为int,而查询语句中错误地用成了string。_elasticsearch exception [type=search_phase_execution_exception, reason=all s
WIZnet W5300-TOE MQTT 发布和订阅 (micropython)_w5500 mqtt onenet-程序员宅基地
文章浏览阅读113次。这些部分将指导您完成一系列步骤,从配置开发环境到使用 STM32f429zi (nuleo-f429zi) 和 W5300-TOE 运行以太网示例 基本设置请参阅“入门”指南。_w5500 mqtt onenet
day24.|回溯法01-程序员宅基地
文章浏览阅读381次,点赞5次,收藏7次。1.也可以叫做,它是一种搜索的方式。2.回溯是递归的副产品,只要有递归就会有回溯。回溯与递归相辅相成,只要有递归就有回溯。通常递归函数的下面就是回溯的逻辑。3.,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。(暴力查找)5.回溯法解决的问题:(1)组合问题:N个数里面按一定规则找出k个数的集合;(2)切割问题:一个字符串按一定规则有几种切割方式;(3)子集问题:一个N个数的集合里有多少符合条件的子集;(4)排列问题:N个数按一定规则全排列,有几种排列方式;
Esp32-CAM(ESP32带camera)使用说明_esp32 cam说明书-程序员宅基地
文章浏览阅读6.7k次,点赞2次,收藏28次。1、如下图,只需在丝印 VCC GND 处供 3.3V 电源即可启动开发板2、上电后开发板会释放热点。其中SSID: wireless-tagPwd: wireless-tag3、电脑或手机连接此热点后,登录网页 http://192.168.4.1 进入 WEBSERVER 界面。如下图:4、上图中有两个红色框 Get Still 和 Start Stream(Stop Stream)。点击 Get Still,摄像头抓取一张图片,并显示在黑色区域;点击 Start Stream_esp32 cam说明书
随便推点
BZOJ 4034 HAOI2015 T2 DFS序+线段树_haoi2015 t2-bzoj4034-程序员宅基地
文章浏览阅读2.4k次。题目大意:给定一棵树,每个点有点权,支持下列操作: 1.某个点的点权+a 2.某棵子树所有点权+a 3.查询某个点到根路径上的点权和 这个用入栈出栈序就可以了 入栈为正,出栈为负,那么一个点到根路径上的权值和就是入栈出栈序中[1,入栈位置]的和 而子树在入栈出栈序中是连续的,因此用线段树维护一下就可以了 (似乎只要无脑链剖就可以了?#include #include_haoi2015 t2-bzoj4034
3D数学基础(一)——左手坐标系和右手坐标系_3d左手坐标系-程序员宅基地
文章浏览阅读3.7k次。3D数学基础(一)——左手坐标系和右手坐标系1、左手坐标系左手坐标系的定义伸出左手,让拇指和是指成L型,大拇指向右,食指向前,中指指向前方,这样便定义好了一个左手坐标系,其中拇指为x轴,食指为Y轴,中指为Z轴。图示2、右手坐标系右手坐标系的定义右手坐标系与左手坐标系相反图示3、意义左手坐标系和右手坐标系虽然定义简单,并且可以相互转换,但是在一个场景中定义好坐标系是左手坐标..._3d左手坐标系
Java NIO之Selector_java nio selecter-程序员宅基地
文章浏览阅读278次。一、Java NIO 的核心组件Java NIO的核心组件包括:Channel(通道),Buffer(缓冲区),Selector(选择器),其中Channel和Buffer比较好理解 简单来说 NIO是面向通道和缓冲区的,意思就是:数据总是从通道中读到buffer缓冲区内,或者从buffer写入到通道中。二、Java NIO Selector1. Selector简介选择器..._java nio selecter
1. 一键安装oracle11g数据库_linux安装oracle11g数据库-程序员宅基地
文章浏览阅读2.3k次,点赞4次,收藏20次。Oracle数据库在Linux系统上安装步骤比较多,为了方便Oracle数据库的安装,编写了以下脚本,简化了Oracle数据库的安装。_linux安装oracle11g数据库
TCP/IP协议详解-程序员宅基地
文章浏览阅读60次。1、TCP/IP协议栈四层模型 TCP/IP这个协议遵守一个四层的模型概念:应用层、传输层、互联层和网络接口层。 网络接口层 模型的基层是网络接口层。负责数据帧的发送和接收,帧是独立的网络信息传输单元。网络接口层将帧放在网上,或从网上把帧取下来。 互联层 互联协议将数据包封装成internet数据报,并运行必要的路由算法。 这里有四个互联协议: 网际协议IP...
网络安全的隐形守护者——白帽黑客-程序员宅基地
文章浏览阅读2.3k次。提起黑客我们的脑海中总是会浮现那些“啪啪啪”敲键盘,进入别人电脑或是企业服务器的“神秘人”,他们来无影去无踪,但是每次造访总会将所到之处破坏个淋漓尽致,直到拿到自己想要的..._白帽黑客小青