R语言︱异常值检验、离群点分析、异常值处理_r语言异常值处理-程序员宅基地
技术标签: R 插补法 R的数据操作与清洗 异常值 r语言 R︱数据操作与清洗 离群点
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
笔者寄语:异常值处理一般分为以下几个步骤:异常值检测、异常值筛选、异常值处理。
其中异常值检测的方法主要有:箱型图、简单统计量(比如观察极值)
异常值处理方法主要有:删除法、插补法、替换法。
提到异常值不得不说一个词:鲁棒性。就是不受异常值影响,一般是鲁棒性高的数据,比较优质。
一、异常值检验
异常值大概包括缺失值、离群值、重复值,数据不一致。
1、基本函数
summary可以显示每个变量的缺失值数量.
2、缺失值检验
关于缺失值的检测应该包括:缺失值数量、缺失值比例、缺失值与完整值数据筛选。
#缺失值解决方案
sum(complete.cases(saledata)) #is.na(saledata)
sum(!complete.cases(saledata))
mean(!complete.cases(saledata)) #1/201数字,缺失值比例
saledata[!complete.cases(saledata),] #筛选出缺失值的数值
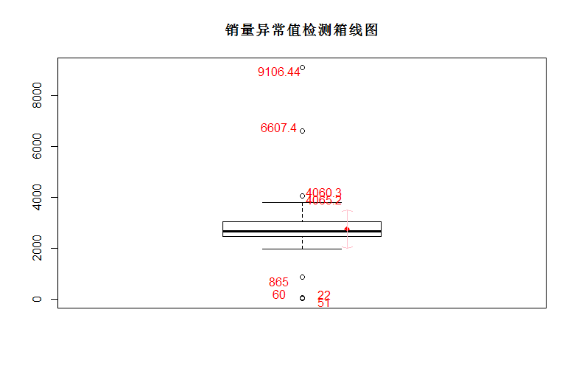
3、箱型图检验离群值
箱型图的检测包括:四分位数检测(箱型图自带)+1δ标准差上下+异常值数据点。
箱型图有一个非常好的地方是,boxplot之后,结果中会自带异常值,就是下面代码中的sp$out,这个是做箱型图,按照上下边界之外为异常值进行判定的。
上下边界,分别是Q3+(Q3-Q1)、Q1-(Q3-Q1)。
sp=boxplot(saledata$"销量",boxwex=0.7)
title("销量异常值检测箱线图")
xi=1.1
sd.s=sd(saledata[complete.cases(saledata),]$"销量")
mn.s=mean(saledata[complete.cases(saledata),]$"销量")
points(xi,mn.s,col="red",pch=18)
arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)
text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)],
sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red")代码中text函数的格式为text(x,label,y,col);points加入均值点;arrows加入均值上下1δ标准差范围箭头。
箱型图还有等宽与等深分箱法,可见另外一个博客:R语言︱噪声数据处理、数据分组——分箱法(离散化、等级化)
4、数据去重
数据去重与数据分组合并存在一定区别,去重是纯粹的所有变量都是重复的,而数据分组合并可能是因为一些主键的重复。
数据去重包括重复检测(table、unique函数)以及重复数据处理(unique/duplicated)。
常见的有unique、数据框中duplicated函数,duplicated返回的是逻辑值。
二、异常值处理
常见的异常值处理办法是删除法、替代法(连续变量均值替代、离散变量用众数以及中位数替代)、插补法(回归插补、多重插补)
除了直接删除,可以先把异常值变成缺失值、然后进行后续缺失值补齐。
实践中,异常值处理,一般划分为NA缺失值或者返回公司进行数据修整(数据返修为主要方法)
1、异常值识别
利用图形——箱型图进行异常值检测。
#异常值识别
par(mfrow=c(1,2))#将绘图窗口划为1行两列,同时显示两图
dotchart(inputfile$sales)#绘制单变量散点图,多兰图
pc=boxplot(inputfile$sales,horizontal=T)#绘制水平箱形图2、盖帽法
整行替换数据框里99%以上和1%以下的点,将99%以上的点值=99%的点值;小于1%的点值=1%的点值。
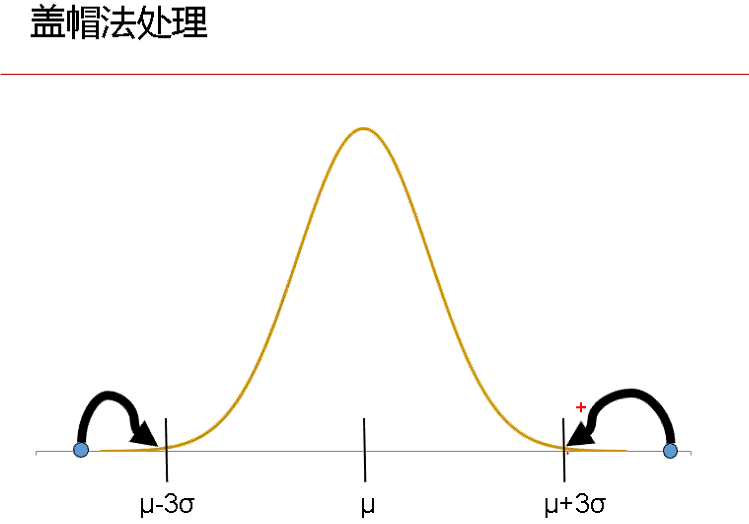
(本图来自CDA DSC,L2-R语言课程,常老师所述)
#异常数据处理
q1<-quantile(result$tot_derog, 0.001) #取得时1%时的变量值
q99<-quantile(result$tot_derog, 0.999) #replacement has 1 row, data has 0 说明一个没换
result[result$tot_derog<q1,]$tot_derog<-q1
result[result$tot_derog>q99,]$tot_derog<-q99
summary(result$tot_derog) #盖帽法之后,查看数据情况
fix(inputfile)#表格形式呈现数据
which(inputfile$sales==6607.4)#可以找到极值点序号是啥把缺失值数据集、非缺失值数据集分开。
#缺失值的处理
inputfile$date=as.numeric(inputfile$date)#将日期转换成数值型变量
sub=which(is.na(inputfile$sales))#识别缺失值所在行数
inputfile1=inputfile[-sub,]#将数据集分成完整数据和缺失数据两部分
inputfile2=inputfile[sub,]3、噪声数据处理——分箱法
将连续变量等级化之后,不同的分位数的数据就会变成不同的等级数据,连续变量离散化了,消除了极值的影响。
4、异常值处理——均值替换
数据集分为缺失值、非缺失值两块内容。缺失值处理如果是连续变量,可以选择均值;离散变量,可以选择众数或者中位数。
计算非缺失值数据的均值,
然后赋值给缺失值数据。
#均值替换法处理缺失,结果转存
#思路:拆成两份,把缺失值一份用均值赋值,然后重新合起来
avg_sales=mean(inputfile1$sales)#求变量未缺失部分的均值
inputfile2$sales=rep(avg_sales,n)#用均值替换缺失
result2=rbind(inputfile1,inputfile2)#并入完成插补的数据5、异常值处理——回归插补法
#回归插补法处理缺失,结果转存
model=lm(sales~date,data=inputfile1)#回归模型拟合
inputfile2$sales=predict(model,inputfile2)#模型预测
result3=rbind(inputfile1,inputfile2)6、异常值处理——多重插补——mice包
注意:多重插补的处理有两个要点:先删除Y变量的缺失值然后插补
1、被解释变量有缺失值的观测不能填补,只能删除,不能自己乱补;
2、只对放入模型的解释变量进行插补。
比较详细的来介绍一下这个多重插补法。笔者整理了大致的步骤简介如下:
缺失数据集——MCMC估计插补成几个数据集——每个数据集进行插补建模(glm、lm模型)——将这些模型整合到一起(pool)——评价插补模型优劣(模型系数的t统计量)——输出完整数据集(compute)
步骤详细介绍:
函数mice()首先从一个包含缺失数据的数据框开始,然后返回一个包含多个(默认为5个)完整数据集的对象。
每个完整数据集都是通过对原始数据框中的缺失数据进行插补而生成的。 由于插补有随机的成分,因此每个完整数据集都略有不同。
其中,mice中使用决策树cart有以下几个要注意的地方:该方法只对数值变量进行插补,分类变量的缺失值保留,cart插补法一般不超过5k数据集。
然后, with()函数可依次对每个完整数据集应用统计模型(如线性模型或广义线性模型) ,
最后, pool()函数将这些单独的分析结果整合为一组结果。最终模型的标准误和p值都将准确地反映出由于缺失值和多重插补而产生的不确定性。
#多重插补法处理缺失,结果转存
library(lattice) #调入函数包
library(MASS)
library(nnet)
library(mice) #前三个包是mice的基础
imp=mice(inputfile,m=4) #4重插补,即生成4个无缺失数据集
fit=with(imp,lm(sales~date,data=inputfile))#选择插补模型
pooled=pool(fit)
summary(pooled)
result4=complete(imp,action=3)#选择第三个插补数据集作为结果结果解读:
(1)imp对象中,包含了:每个变量缺失值个数信息、每个变量插补方式(PMM,预测均值法常见)、插补的变量有哪些、预测变量矩阵(在矩阵中,行代表插补变量,列代表为插补提供信息的变量, 1和0分别表示使用和未使用);
同时 利用这个代码imp$imp$sales 可以找到,每个插补数据集缺失值位置的数据补齐具体数值是啥。
> imp$imp$sales
1 2 3 4
9 3614.7 3393.1 4060.3 3393.1
15 2332.1 3614.7 3295.5 3614.7(2)with对象。插补模型可以多样化,比如lm,glm都是可以直接应用进去,详情可见《R语言实战》第十五章;
(3)pool对象。summary之后,会出现lm模型系数,可以如果出现系数不显著,那么则需要考虑换插补模型;
(4)complete对象。m个完整插补数据集,同时可以利用此函数输出。
其他:
mice包提供了一个很好的函数md.pattern(),用它可以对缺失数据的模式有个更好的理解。还有一些可视化的界面,通过VIM、箱型图、lattice来展示缺失值情况。可见博客:在R中填充缺失数据—mice包
三、离群点检测
离群点检测与第二节异常值主要的区别在于,异常值针对单一变量,而离群值指的是很多变量综合考虑之后的异常值。下面介绍一种基于聚类+欧氏距离的离群点检测方法。
基于聚类的离群点检测的步骤如下:数据标准化——聚类——求每一类每一指标的均值点——每一类每一指标生成一个矩阵——计算欧式距离——画图判断。
Data=read.csv(".data.csv",header=T)[,2:4]
Data=scale(Data)
set.seed(12)
km=kmeans(Data,center=3)
print(km)
km$centers #每一类的均值点
#各样本欧氏距离,每一行
x1=matrix(km$centers[1,], nrow = 940, ncol =3 , byrow = T)
juli1=sqrt(rowSums((Data-x1)^2))
x2=matrix(km$centers[2,], nrow = 940, ncol =3 , byrow = T)
juli2=sqrt(rowSums((Data-x2)^2))
x3=matrix(km$centers[3,], nrow = 940, ncol =3 , byrow = T)
juli3=sqrt(rowSums((Data-x3)^2))
dist=data.frame(juli1,juli2,juli3)
##欧氏距离最小值
y=apply(dist, 1, min)
plot(1:940,y,xlim=c(0,940),xlab="样本点",ylab="欧氏距离")
points(which(y>2.5),y[which(y>2.5)],pch=19,col="red")
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
智能推荐
webSocket入门小案例(搭建实时交互的群聊+点对点的交流)_websocket入门案例-程序员宅基地
文章浏览阅读2.9k次。WebSocket是一种在单个TCP连接上进行全双工通信的协议。WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。_websocket入门案例
【HDU - 3308】 LCIS 【线段树+单点更新+区间合并】_given n integers. you have two operations: u a b: -程序员宅基地
文章浏览阅读304次。Given n integers. You have two operations: U A B: replace the Ath number by B. (index counting from 0) Q A B: output the length of the longest consecutive increasing subsequence (LCIS) in [a, b]._given n integers. you have two operations: u a b: replace the ath number by
WPF-设置窗体显示在右下角_wpf 窗口显示在右下角-程序员宅基地
文章浏览阅读2.8k次。 private void Button_Click(object sender, RoutedEventArgs e) { Win_Display_Position win = new Win_Display_Position(); //显示在右下角 double xpos = this.Left+this..._wpf 窗口显示在右下角
Mybatis分页查询案例_mybatis 分页查询-程序员宅基地
文章浏览阅读4.9k次,点赞2次,收藏6次。Mybatis分页查询案例_mybatis 分页查询
解决MAC系统升级导致COCOAPODS失效问题-程序员宅基地
文章浏览阅读76次。解决MAC系统升级导致COCOAPODS失效问题使用pod install出现如下错误-bash: /usr/local/bin/pod: /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/ruby: bad interpreter: No such file or directory这是Mac升级系统导致,当你的M..._mac升级10.15系统后cocoapod不能用
网址.txt-程序员宅基地
文章浏览阅读1.7k次。 世界上最好的帖子, 经典网址合并于此世界上最好的帖子, 经典网址合并于此1、搜索网站: http://www.google.com 全球最强大的搜索网站。在语言学习中,它的功能至少包括: 搜索新词可用之语境、确认某种搭配或用法是否准确、通过同时输入中文及"English"寻找可能存在的双语介绍、查询文学作品译本、了解某一类事物的相关知识等。 http://www.yahoo.com 雅
随便推点
Import语句基础_import aie 语句-程序员宅基地
文章浏览阅读1.5k次,点赞4次,收藏7次。1 问题在 Java 中,如果给出一个完整的限定名,包括包名、类名,那么 Java 编译器就可以很容易地定位到源代码或者类。import 语句就是用来提供一个合理的路径,使得编译器可以找到某个类。2 方法1.import导入声明可分为两种:1) 单类型导入(single-type-import)例: 2) 按需类型导入(type-import-on-demand)例:2. 举例java.util..._import aie 语句
Java线程池核心线程数与最大线程数的区别_核心线程数和最大线程数-程序员宅基地
文章浏览阅读2.9w次,点赞37次,收藏100次。核心线程corePoolSize:核心线程数;maximunPoolSize:最大线程数每当有新的任务到线程池时,第一步: 先判断线程池中当前线程数量是否达到了corePoolSize,若未达到,则新建线程运行此任务,且任务结束后将该线程保留在线程池中,不做销毁处理,若当前线程数量已达到corePoolSize,则进入下一步;第二步: 判断工作队列(workQueue)是否已满,未满则将新的任务提交到工作队列中,满了则进入下一步;第三步: 判断线程池中的线程数量是否达到了maxumunPoolSi_核心线程数和最大线程数
HTML5表单美化_html datalist 美化-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏7次。[转载]利用 HTML5 美化表单对表单感兴趣的人并不多,但 HTML5 引入的一些重大改进却同时方便了创建表单的开发人员和填写表单的用户。全新的表单元素、属性、输入类型、基于浏览器的验证、CSS3 样式技术以及 FormData 对象让创建表单变得更轻松,甚至可能更富有趣味性。There is even more up to date forms guidance on our _html datalist 美化
Church's Coupon Performance Test Script_api.nnys868.work-程序员宅基地
文章浏览阅读7w次。 2015年6月针对church's coupon app做了并发压力测试,HP LR在11.5版本第一次支持在移动设备的录制对Server压力测试。也是本人第一次在移动设备上压力测试实践。工具使用的是 HP LoadRunner 12.02 Community Edition。(社区版可以免费支持50个虚拟用户并发,此版本工具当时是最新版,尚没有任何破解的license)LoadRunne..._api.nnys868.work
AtCoder题解——Beginner Contest 178——F - Contrast_given are two sequences a and b, both of lengt-程序员宅基地
文章浏览阅读582次。题目相关题目链接AtCoder Beginner Contest 178 F 题,https://atcoder.jp/contests/abc178/tasks/abc178_f。Problem StatementGiven are two sequences A and B, both of length N. A and B are each sorted in the ascending order. Check if it is possible to reorder the te_given are two sequences a and b, both of length n. a and
总结:IP地址、网络地址与子网掩码的理解-程序员宅基地
文章浏览阅读3w次,点赞47次,收藏303次。一、IP地址电脑之间要实现网络通信,就必须要有一个合法的ip地址。IP地址=网络地址+主机地址,(又称:主机号和网络号组成)ip地址的结构使我们可以在Internet上很方便的寻址。ip地址通常用更直观的,以点分十进制表示,每个数字从0到255,如某一台主机的ip地址为:128.20.4.1。在局域网里,同样也需要ip地址,一般内网的ip地址是以192.168开头的,这样很容易区分公网和内网的ip地址。【注】网络地址也叫做网络位置、网络号、网段、子网IP,都是描述属于哪个子网的同义词。【_网络地址