链表基础知识详解(非常详细简单易懂)-程序员宅基地
技术标签: c++ 笔记 STM32 FreeRTOS 数据结构
概述:
链表作为 C 语言中一种基础的数据结构,在平时写程序的时候用的并不多,但在操作系统里面使用的非常多。不管是RTOS还是Linux等使用非常广泛,所以必须要搞懂链表,链表分为单向链表和双向链表,单向链表很少用,使用最多的还是双向链表。单向链表懂了双向链表自然就会了。
文章目录
一、链表的概念
定义:
链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构。
特点:
链表由一系列节点(链表中每一个元素称为节点)组成,节点在运行时动态生成 (malloc),每个节点包括两个部分:
一个是存储数据元素的数据域
另一个是存储下一个节点地址的指针域

图1 单向链表
链表的构成:
链表由一个个节点构成,每个节点一般采用结构体的形式组织,例如:
typedef struct student{
int num;
char name[20];
struct student *next;
}STU;链表节点分为两个域
数据域:存放各种实际的数据,如:num、score等
指针域:存放下一节点的首地址,如:next等.

图2 节点内嵌在一个数据结构中
链表的操作:
链表最大的作用是通过节点把离散的数据链接在一起,组成一个表,这大概就是链表 的字面解释了吧。 链表常规的操作就是节点的插入和删除,为了顺利的插入,通常一条链 表我们会人为地规定一个根节点,这个根节点称为生产者。通常根节点还会有一个节点计 数器,用于统计整条链表的节点个数,具体见图3中的 root_node。

图3带根节点的链表
双向链表
双向链表与单向链表的区别就是节点中有两个节点指针,分别指向前后两个节点,其 它完全一样。有关双向链表的文字描述参考单向链表小节即可,有关双向链表的示意图具体见图4

图4双向链表
链表与数组的对比
在很多公司的嵌入式面试中,通常会问到链表和数组的区别。在 C 语言中,链表与数 组确实很像,两者的示意图具体见图5,这里以双向链表为例。
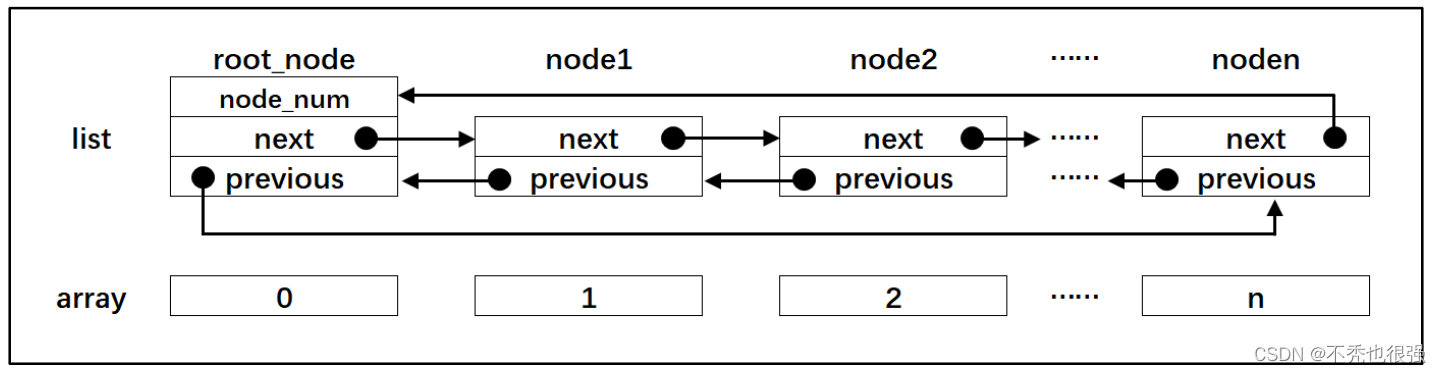 图5 链表与数组的对比
图5 链表与数组的对比
链表是通过节点把离散的数据链接成一个表,通过对节点的插入和删除操作从而实现 对数据的存取。而数组是通过开辟一段连续的内存来存储数据,这是数组和链表最大的区 别。数组的每个成员对应链表的节点,成员和节点的数据类型可以是标准的 C 类型或者是 用户自定义的结构体。数组有起始地址和结束地址,而链表是一个圈,没有头和尾之分, 但是为了方便节点的插入和删除操作会人为的规定一个根节点。
二、链表的创建
第一步:创建一个节点
![]()
第二步:创建第二个节点,将其放在第一个节点的后面(第一的节点的指针域保存第二个节点的地址)
![]()
第三步:再次创建节点,找到原本链表中的最后一个节点,接着讲最后一个节点的指针域保存新节点的地址,以此内推。
![]()
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *next;
}STU;
void link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov = *p_head;
if(*p_head == NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->next=NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->next = NULL;
}
}
int main()
{
STU *head = NULL,*p_new = NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i = 0; i < num;i++)
{
p_new = (STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
link_creat_head(&head,p_new); //将新节点加入链表
}
}
三、链表的遍历
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
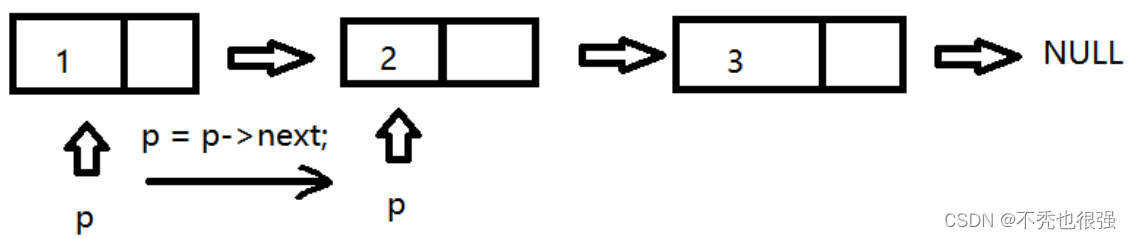
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移
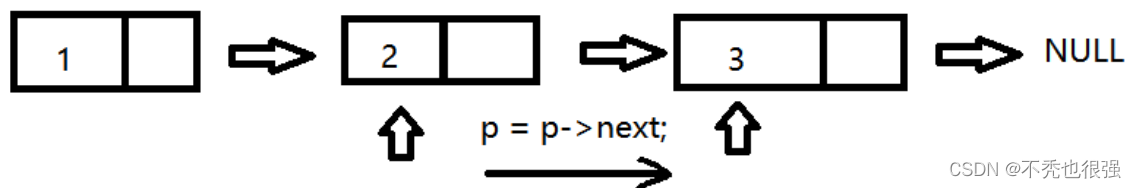
第三步:以此类推,直到节点的指针域为NULL
//链表的遍历
void link_print(STU *head)
{
STU *p_mov;
//定义新的指针保存链表的首地址,防止使用head改变原本链表
p_mov = head;
//当指针保存最后一个结点的指针域为NULL时,循环结束
while(p_mov!=NULL)
{
//先打印当前指针保存结点的指针域
printf("num=%d score=%d name:%s\n",p_mov->num,\
p_mov->score,p_mov->name);
//指针后移,保存下一个结点的地址
p_mov = p_mov->next;
}
}四、链表的释放
重新定义一个指针q,保存p指向节点的地址,然后p后移保存下一个节点的地址,然后释放q对应的节点,以此类推,直到p为NULL为止

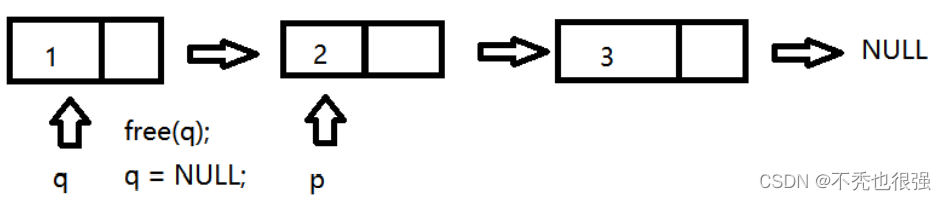
//链表的释放
void link_free(STU **p_head)
{
//定义一个指针变量保存头结点的地址
STU *pb=*p_head;
while(*p_head!=NULL)
{
//先保存p_head指向的结点的地址
pb=*p_head;
//p_head保存下一个结点地址
*p_head=(*p_head)‐>next;
//释放结点并防止野指针
free(pb);
pb = NULL;
}
}五、链表节点的查找
先对比第一个结点的数据域是否是想要的数据,如果是就直接返回,如果不是则继续查找下 一个结点,如果到达最后一个结点的时候都没有匹配的数据,说明要查找数据不存在
//链表的查找
//按照学号查找
STU * link_search_num(STU *head,int num)
{
STU *p_mov;
//定义的指针变量保存第一个结点的地址
p_mov=head;
//当没有到达最后一个结点的指针域时循环继续
while(p_mov!=NULL)
{
//如果找到是当前结点的数据,则返回当前结点的地址
if(p_mov->num == num)//找到了
{
return p_mov;
}
//如果没有找到,则继续对比下一个结点的指针域
p_mov=p_mov->next;
}
//当循环结束的时候还没有找到,说明要查找的数据不存在,返回NULL进行标识
return NULL;//没有找到
}
//按照姓名查找
STU * link_search_name(STU *head,char *name)
{
STU *p_mov;
p_mov=head;
while(p_mov!=NULL)
{
if(strcmp(p_mov->name,name)==0)//找到了
{
return p_mov;
}
p_mov=p_mov->next;
}
return NULL;//没有找到
}六、链表节点的删除
如果链表为空,不需要删除 如果删除的是第一个结点,则需要将保存链表首地址的指针保存第一个结点的下一个结点的 地址 如果删除的是中间结点,则找到中间结点的前一个结点,让前一个结点的指针域保存这个结 点的后一个结点的地址即可
//链表结点的删除
void link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head == NULL)//链表为空,不用删
{
printf("链表为空,没有您要删的节点");\
return ;
}
while(pb->num != num && pb->next !=NULL)//循环找,要删除的节点
{
pf=pb;
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同
{
if(pb == *p_head)//要删除的节点是头节点
{
//让保存头结点的指针保存后一个结点的地址
*p_head = pb->next;
}
else
{
//前一个结点的指针域保存要删除的后一个结点的地址
pf->next = pb->next;
}
//释放空间
free(pb);
pb = NULL;
}
else//没有找到
{
printf("没有您要删除的节点\n");
}
}七、链表中插入一个节点
链表中插入一个结点,按照原本链表的顺序插入,找到合适的位置
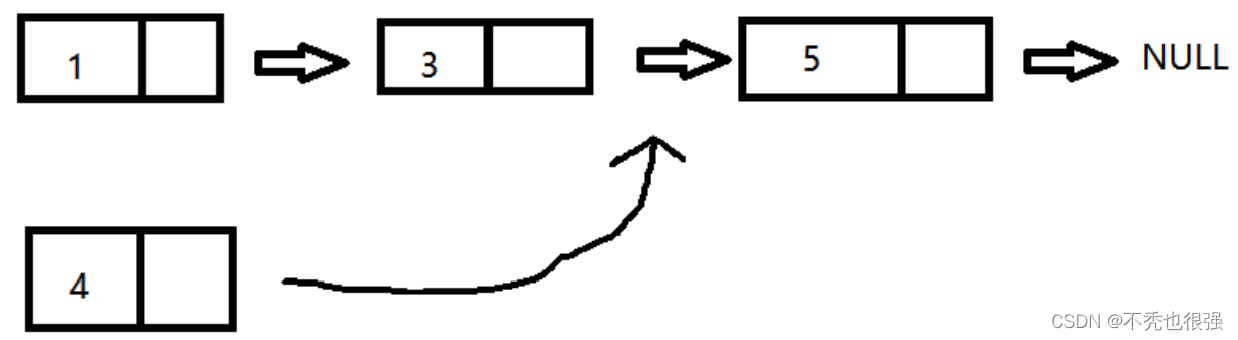
情况(按照从小到大):
如果链表没有结点,则新插入的就是第一个结点。
如果新插入的结点的数值最小,则作为头结点。
如果新插入的结点的数值在中间位置,则找到前一个,然后插入到他们中间。
如果新插入的结点的数值最大,则插入到最后。
//链表的插入:按照学号的顺序插入
void link_insert_num(STU **p_head,STU *p_new)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head ==NULL)// 链表为空链表
{
*p_head = p_new;
p_new->next=NULL;
return ;
}
while((p_new->num >= pb->num) && (pb->next !=NULL) )
{
pf=pb;
pb=pb->next;
}
if(p_new->num < pb->num)//找到一个节点的num比新来的节点num大,插在pb的前面
{
if(pb== *p_head)//找到的节点是头节点,插在最前面
{
p_new->next= *p_head;
*p_head =p_new;
}
else
{
pf->next=p_new;
p_new->next = pb;
}
}
else//没有找到pb的num比p_new->num大的节点,插在最后
{
pb->next =p_new;
p_new->next =NULL;
}
}八、链表排序
如果链表为空,不需要排序。
如果链表只有一个结点,不需要排序。
先将第一个结点与后面所有的结点依次对比数据域,只要有比第一个结点数据域小的,则交 换位置。
交换之后,拿新的第一个结点的数据域与下一个结点再次对比,如果比他小,再次交换,依 次类推。
第一个结点确定完毕之后,接下来再将第二个结点与后面所有的结点对比,直到最后一个结 点也对比完毕为止。
//链表的排序
void link_order(STU *head)
{
STU *pb,*pf,temp;
pf=head;
if(head==NULL)
{
printf("链表为空,不用排序\n");
return ;
}
if(head->next ==NULL)
{
printf("只有一个节点,不用排序\n");
return ;
}
while(pf->next !=NULL)//以pf指向的节点为基准节点,
{
pb=pf->next;//pb从基准元素的下个元素开始
while(pb!=NULL)
{
if(pf->num > pb->num)
{
temp=*pb;
*pb=*pf;
*pf=temp;
temp.next=pb->next;
pb->next=pf->next;
pf->next=temp.next;
}
pb=pb->next;
}
pf=pf->next;
}
}九、双向链表的创建和遍历
第一步:创建一个节点作为头节点,将两个指针域都保存NULL
第二步:先找到链表中的最后一个节点,然后让最后一个节点的指针域保存新插入节点的地址,新插入节点的两个指针域,一个保存上一个节点的地址,一个保存NULL
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
}
十、双向链表插入节点
按照顺序插入结点
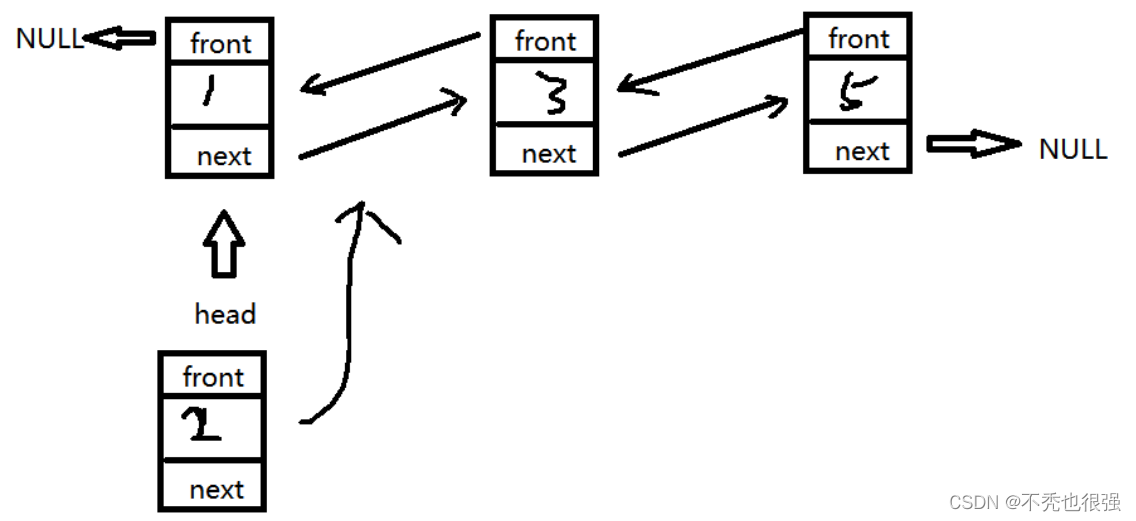
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
//双向链表的删除
void double_link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=*p_head;
if(*p_head==NULL)//链表为空,不需要删除
{
printf("链表为空,没有您要删除的节点\n");
return ;
}
while((pb->num != num) && (pb->next != NULL) )
{
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同,删除pb指向的节点
{
if(pb == *p_head)//找到的节点是头节点
{
if((*p_head)->next==NULL)//只有一个节点的情况
{
*p_head=pb->next;
}
else//有多个节点的情况
{
*p_head = pb->next;//main函数中的head指向下个节点
(*p_head)->front=NULL;
}
}
else//要删的节点是其他节点
{
if(pb->next!=NULL)//删除中间节点
{
pf=pb->front;//让pf指向找到的节点的前一个节点
pf->next=pb->next; //前一个结点的next保存后一个结点的地址
(pb->next)->front=pf; //后一个结点的front保存前一个结点的地址
}
else//删除尾节点
{
pf=pb->front;
pf->next=NULL;
}
}
free(pb);//释放找到的节点
}
else//没找到
{
printf("没有您要删除的节点\n");
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
printf("请输入您要删除的节点的num\n");
scanf("%d",&num);
double_link_delete_num(&head,num);
double_link_print(head);
}
智能推荐
Java必须掌握的全局变量和局部变量(含面试大厂题和源码)-程序员宅基地
文章浏览阅读884次,点赞25次,收藏20次。在Java中,全局变量和局部变量的概念通常与类变量(有时被认为是全局变量)和方法内的变量(局部变量)相关联。虽然Java本身没有全局变量的概念,但类的静态变量经常被用作全局变量。
Android系统新产品定制_export build_target 還原-程序员宅基地
文章浏览阅读1.1k次。配置过程分析:1: . ./build/envsetup.shincluding device/samsung/smdkv210/vendorsetup.sh------------------------------------------------------------------build/envsetup.sh末尾有:# Execute the contents o_export build_target 還原
SQLCookBook第四章学习日记11_insert into default-程序员宅基地
文章浏览阅读450次。第四章 插入、更新与删除 4.1插入新纪录4.2插入默认值_insert into default
ESD保护二极管ESD9B3.3ST5G 以更小的空间实现强大的保护 车规级TVS二极管更给力-程序员宅基地
文章浏览阅读594次。ESD9B3.3ST5G是一款 双向ESD保护 TVS二极管,设计用于保护电压敏感型来自ESD的组件。良好的夹紧能力,低泄漏,而且,快速响应时间可为设计提供一流的保护:暴露在静电放电下。反应速度快,电容值低,体积小,集成度高,封装多样化,漏电流低,电压值低有助于保护敏感的电子电路。ESD9B3.3ST5G ESD静电保护二极管应用于手机和配件、便携式电子产品、工业控制设备、机顶盒、电子仪器仪表、服务器,笔记本电脑和台式机、显示端口等。
宁波中软国际实习日记(一):SSM框架开发环境搭建-程序员宅基地
文章浏览阅读807次,点赞2次,收藏2次。宁波中软国际实习日记第一天:搭建开发环境1.0 JDK安装2.0 IDEA安装3.0 Tomcat安装、部署4.0 Maven安装、部署5.0 MySQL安装6.0 Notepad++安装1.0 JDK安装实习所用JDK版本是JDK8,在官网的下载页面找到Java SE 8u151/ 8u152的JDK download 按钮。点进去。双击安装程序后,一直点next就行。接下来是环境变..._中软国际实习日记
django数据存入mysql数据库_Django学习系列15:把POST请求中的数据存入数据库-程序员宅基地
文章浏览阅读231次。要修改针对首页中的POST请求的测试。希望视图把新添加的待办事项存入数据库,而不是直接传给响应。为了测试这个操作,要在现有的测试方法test_can_save_a_post_request中添加3行新代码# lists/tests.pydeftest_can_save_a_post_request(self):response= self.client.post(‘/‘, data={‘item_..._django http post mysql
随便推点
CSS三角、界面样式(cursor、input输入边框不改变颜色、textarea拖拽不改变大小)、vertical-align、溢出文字省略号显示、CSS初始化_html css input::cue-程序员宅基地
文章浏览阅读1.5k次,点赞2次,收藏7次。vertical-align的可选值为:1. bottom: 图片的底线和文字的底线对齐,2. baseline:默认,图片的底线和文字的基线对齐,3. middle: 图片的中线和文字的中线对齐,4. top:图片的顶线和文字的顶线对齐。不同浏览器对有些标签的默认值是不同的,为了消除不同浏览器对HTML文本呈现的差异,所以需要进行CSS初始化。当我们选择input输入框,进行文字输入的时候,边框会改变颜色。textarea默认可以在右下角进行拖拽,改变输入框的大小。CSS初始化参考如下。_html css input::cue
【CS231N】5、神经网络静态部分:数据预处理等-程序员宅基地
文章浏览阅读84次。一、疑问二、知识点1. 白化 白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵。该操作的代码如下:# 对数据进行白化操作:# 除以特征值 Xwhite = Xrot / np.sqrt(S + 1e-5) 警告:夸大的噪声。注意分母..._人工神经网络系统中的静态数据
MyEclipse开发教程:使用REST Web Services管理JPA实体(四)-程序员宅基地
文章浏览阅读81次。MyEclipse 在线订购年终抄底促销!火爆开抢>>MyEclipse最新版下载使用REST Web Services来管理JPA实体。在逆向工程数据库表后生成REST Web服务,下面的示例创建用于管理博客条目的简单Web服务。你将学会:利用数据库逆向工程开发REST Web服务部署到Tomcat服务器使用REST Web服务资源管理器进行测试没有MyEcli..._myeclipse项目中不能选add rest web service compatibility
后端面试每日一题 垃圾回收算法,面试资料分享-程序员宅基地
文章浏览阅读854次,点赞10次,收藏17次。校验的内容就是此对象是否重写了 finalize() 方法,如果该对象重写了 finalize() 方法,那么这个对象将会被存入到 F-Queue 队列中,等待 JVM 的 Finalizer 线程去执行重写的 finalize() 方法,在这个方法中如果此对象将自己赋值给某个类变量时,则表示此对象已经被引用了。它是指将内存分为大小相同的两块区域,每次只使用其中的一块区域,这样在进行垃圾回收时就可以直接将存活的东西复制到新的内存上,然后再把另一块内存全部清理掉。// 等待 finalize() 执行。
LeetCode 1427. 字符串的左右移_leetcode 1427 python-程序员宅基地
文章浏览阅读246次。LeetCode 1427. 字符串的左右移文章目录LeetCode 1427. 字符串的左右移题目描述一、解题关键词二、解题报告1.思路分析2.时间复杂度3.代码示例2.知识点总结相同题目题目描述给定一个包含小写英文字母的字符串 s 以及一个矩阵 shift,其中 shift[i] = [direction, amount]: direction 可以为 0 (表示左移)或 1 (表示右移)。 amount 表示 s 左右移的位数。 左移 1 位表示移除 s 的第一个字符,并_leetcode 1427 python
好用的不行不行!超级炫酷的键盘最应该留给最般配的猿们!-程序员宅基地
文章浏览阅读2k次。在北半球,3月是春季的第一个月,春天象征着希望和美好。关注我的读者大多数都是(程序)猿,所以好用的键盘必不可少!今天为了感谢大家对本公众号的大力支持我联合了10个号主送11个炫酷键盘,不..._cole mak键盘