1 爬虫的分类根据被爬网站的数量的不同,我们把爬虫分为:通用爬虫 :通常指搜索引擎的爬虫(https://www.baidu.com)聚焦爬虫 :针对特定网站的爬虫2 爬虫的流程爬虫的工作流程:向起始url发送请求,并获取响应对...
”爬虫的基本分类和爬虫的流程“ 的搜索结果
基本概念及常用基本方法一、爬虫基本概念定义使用爬虫的目的企业获取数据的方式使用Python做爬虫的优势爬虫分类通用爬取步骤(语义层面概括)二、爬虫请求模块模块及导入常用方法详解urllib.request.urlopenurllib....
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,...如果形象地理解,爬虫就如同一只机器蜘蛛,它的基本操作就是模拟人的行为去各个网站抓取数据或返回数据。
目录一、前言二、爬虫简介2.1 什么是爬虫2.2 基本的爬虫流程2.3 爬虫的分类2.4 robots协议三、网站基础3.1 HTTP和HTTPS3.2 URL3.3 请求和响应3.4 网页基础 一、前言 首先,我也是个爬虫小白,也在努力的学习中,当然...
爬虫的概念和基本流程
网络爬虫原理与流程详解
标签: 爬虫
这样,当你重新启动爬虫时,可以加载之前保存的URL列表,继续爬取未完成的任务。它们根据不同的数据模型进行存储和检索,如文档数据库、键值数据库、列族数据库和图数据库,适用于大规模、分布式和快速读写的场景。...

原标题:python爬虫系列(1)- 概述事由之前间断地写过一些python爬虫的一些文章,如:工具分享 | 在线小说一键下载Python帮你定制批量获取智联招聘的信息Python帮你定制批量获取你想要的信息用python定制网页跟踪...
1. 为什么要爬虫?"大数据时代”,数据获取的方式:大型企业公司有海量用户,需要收集数据来提升产品体验【百度指数(搜索),阿里指数(网购),腾讯数据(社交)】数据管理咨询公司: 通过数据团队专门提供...
多年爬虫领域老工程师深度总结反爬虫技术原理与场景,带你快速了解并掌握反爬虫技术栈知识
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。...



一文了解爬虫的最基本常识,让小白轻松入门,直接实践

文章主要介绍了爬虫原理之定义、分类、流程与编码格式。
2、爬虫有哪些分类? 3、爬中流程与搜索引擎工作流程 4、http/https协议与状态码 5、robots协议 要想看图片,在公众号白杨SEO上看。 爬虫是什么?反爬虫又是什么? 这里的爬虫不是我们生活中的爬虫,如蜘蛛。这里的...
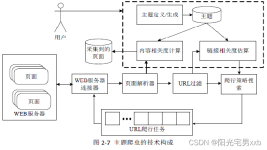
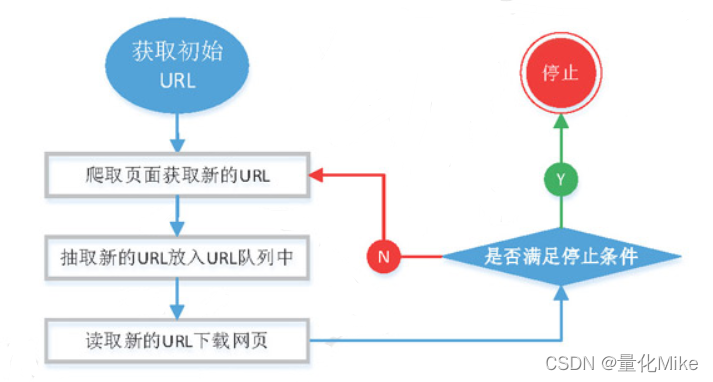
一、网络爬虫的基本结构及工作流程一个通用的网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下:1.首先选取一部分精心挑选的种子URL;2.将这些URL放入待抓取URL队列;3.从待抓取URL队列中取出待抓取在URL,解析...
爬虫要做的是什么? 我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。 用户获取网络数据的方式是: 浏览器提交请求->下载网页代码->解析/渲染成页面。 而爬虫...
目录Python爬虫——requests库、动态爬取html网页一、爬虫基础知识二、爬虫的分类三、HTTP和HTTPS四、url的形式五、字符串六、request发送请求和获取页面字符串reponse.text和response.content的区别七、requests...
python爬虫基本概述 一、爬虫是什么 二、爬虫可以做什么 三、爬虫的分类 四、爬虫的基本流程 一、爬虫是什么 网络爬虫(Crawler)又称网络蜘蛛,或者网络机器人(Robots). 它是一种按照一定的规则, 自动...
爬虫基础 1. 爬虫的概念 模拟浏览器,发送请求,获取响应 浏览器相当于客户端 网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(如网易云音乐)(主要指浏览器)发送网络请求,接收请求响应,一种按照...

第一章 爬虫(认识网络爬虫)
标签: 爬虫
爬虫笔记(不断更新)
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。请求体一般承载的内容是 POST 请求中的表单数据,而对于 GET 请求,请求体...
爬虫基本原理
硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新...
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地