1、广义上的 font-size 用于设置 字体大小,辅以单位控制,实质上是控制 字符框 的高度。 2、狭义上的 font-size 2.1、字体的基线 line-height : 意为 行高 ,content-area ...em box : 意为 字体框 ,仅被 fon...
”浅谈EM算法的两个理解角度_Joe?的博客-程序员宅基地“ 的搜索结果
有时候论文里面需要写算法伪代码,所以这里记录下用LaTeX写一个算法的操作。如果想直接看效果,请直接翻到`3)输出算法效果`这一小节。
要找到撒列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。在机器学习中,...
在正文开始之前需要先搞明白以下几个问题: 1. 什么是DMA? DMA的中文名称叫做 直接内存访问,是一种不需要CPU参与,就能实现数据搬移的技术(从一个地址空间到另一个地址空间)。 2. DMA有什么用? 一定程度上...
本讲我们将为大家介绍贝叶斯学习的内容,着重分析最大似然估计以及贝叶斯估计这两种方法在参数估计问题上的差异。虽然这两种方法得到的结果通常是很接近的,但是其本质却有很大的差别。 最大似然估计将待估计的...
OTSU算法是由日本学者OTSU于1979年提出的一种对图像进行二值化的高效算法。(大津算法) Otsu原理 对于图像 t (x,y),前景(即目标)和背景的分割阈值记作 T,属于前景的像素点数占整幅图像的比例记为 ω0,平均灰度为...
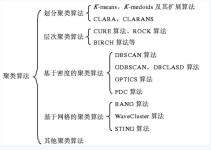
给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法,...

我们先假设它是由两个高斯分布混合叠加而成的,那么我们该怎么去得到这两个高斯分布的参数呢? EM算法!! 1. 高斯混合模型 假设观测数据 y1,y2,...,yN 是由高斯混合模型生成的。 P(y|θ)=∑k=1Kαkθ...

生成对抗网络

***题记:*我一直在路上,害怕停下 在我的另一篇博客里《读sklearn源码学机器学习——kmeans...主要是弥补我上篇博客中没有说明白的两个函数(elativeDist,squaredNorna)和一个初始化。 1、kmeans++算法 kmeans++是D
EM算法(Expectation Maximization Algorithm)详解主要内容 EM算法简介预备知识 极大似然估计Jensen不等式EM算法详解 问题描述EM算法推导EM算法流程EM算法优缺点以及应用1、EM算法简介 EM算法是一种迭代优化...
下面是它的一些常用参数介绍参数作用linesnumbered显示行号ruled标题显示在上方,不加就默认显示在下方vlined代码段中用线连接boxed将算法插入在一个盒子里基本语法代码作用\;行末添加行号并自动换行\caption{算法...

定义 JPA 即Java Persistence API。 JPA 是一个基于O/R映射的标准规范(目前最新版本是JPA 2.1 )。...JPA的出现有两个原因: 简化现有Java EE和Java SE应用的对象持久化的开发工作; Sun希......

(1).LR (Logistic Regression,逻辑回归又叫逻辑分类)(2).SVM (Support Vector Machine,支持向量机)(1).LR (Linear Regression,线性回归)(3). RR (Ridge Regression,岭回归)(3).NB (Naive Bayes,朴素贝叶斯)(4)....
朴素贝叶斯则是“属性条件独立性假设”下的特例,它避免了假设属性联合分布过于经验性和训练集不足引起参数估计较大偏差两个大问题,最后介绍的拉普拉斯修正将概率值进行平滑处理。本篇将介绍另一个当选为数据挖掘...
写成一般的形式:对于一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况下不做任何主观的假设,在这种情况下,概率分布是最均匀的,预测的风险性最小,因此得到的概率分布的熵最大。...
EM算法学习(Expectation Maximization Algorithm) 一、前言 ... 这是本人写的第一篇博客,是学习李航老师的《统计学习方法》书以及斯坦福机器学习课Andrew Ng的EM算法课后,对EM算法
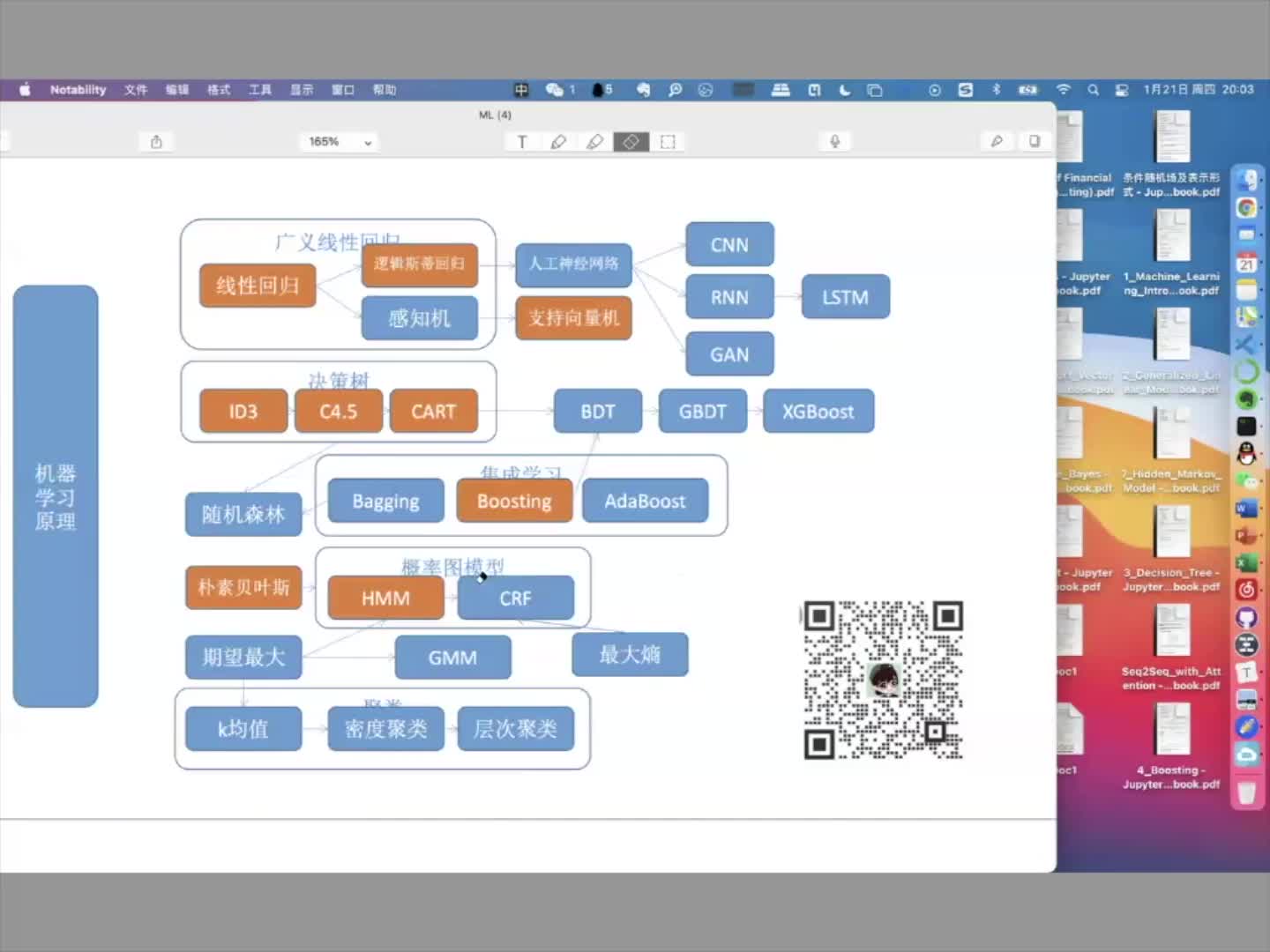
在公众号看到来一篇不错的文章,讲解机器学习算法的,感觉挺好的,所以这里对常用的机器学习算法做一个小的总结, 然后根据学习李航老师的《统计学习方法》做得笔记,对这些算法进行补充。 简介 关于机器学习...
有时候需要琢磨算法为什么奏效?背后到底有什么原因?什么时候算法会失效?...K均值聚类算法迈出了非常精彩的第一步,基本思路是寻找两个类别的聚点中心。K均值聚类的特点 首先随机给出两个聚点中心的
GMM-HMM 详解
标签: GMM-HMM
这篇blog只回答三个问题: 1.什么是Hidden Markov Model? HMM要解决的三个问题: 1) Likelihood 2) Decoding 3) Training 2. GMM是神马?怎样用GMM求某一音素(phoneme)的概率? 3. GMM+HMM大法解决语音...
在现实生活中,由于被试者的能力不能通过可观测的数据进行描述,所以IRT模型用一个潜变量θθ来表示,并考虑与项目相关的一组参数来分析正确回答测试项目的概率。目前常见的IRT模型有2-PL模型和3-PL模型。其具体...
这个问题的求解需要用到鲍姆-韦尔奇算法,我会在隐马尔可夫模型系列的第三篇博客中讲解,这个问题是HMM模型三个问题中最复杂的。 鲍姆-韦尔奇算法本质上就是EM算法,只不过它比EM算法出来的早,所以这里继续称它为...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地