”浅谈EM算法的两个理解角度_Joe?的博客-程序员宅基地“ 的搜索结果
EM算法EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计。每一次迭代由两步组成:E步,求期望(expectation);M步,求极大(maximazation)。不断循环直到算法收敛,最后得出参数的估计。之所以...
初步计划内容如下第一篇:PLSA及EM算法第二篇:LDA及Gibbs Samping第三篇:LDA变形模型-Twitter LDA,TimeUserLDA,ATM,Labeled-LDA,MaxEnt-LDA等第四篇:基于变形LDA的paper分类总结第五篇:LDA Gibbs Sa

EM算法 EM算法 实例讲解 %{ 实现的是一个AB硬币的例子 thetaA和thetaB表示硬币A和B正面向上的概率 A的计算结果是在每一轮投掷时,选择的是硬币A的概率 %} clear clc data = [[5 5];[9 1];[8 2];[4 6];[7 3]...
贝叶斯网与EM算法 一、贝叶斯网 贝叶斯网络亦称为“信念网”,他借助有向无环图来刻画属性之间的依赖关系,并使用条件概率表来描述属性的联合概率分布。 具体来说,一个贝叶斯网B由结构G和参数θθ\theta两部分...
“上帝的算法”——EM写在前面:最近看完了吴军的《数学之美》,大赞!相比《统计学习方法》、《机器学习》来说,《数学之美》没有那么多的公式理论,全是科普性质的(开拓眼界),其中也不乏一些数学原理的解释,...
一、EM算法简介 EM算法是期望极大(Expectation Maximization)算法的简称,是一种解决存在隐含变量优化问题的有效方法。
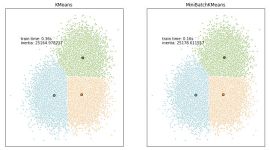
如果使用了CvEM::START_AUTO_STEP,则会调用k-means算法估计最初的参数,K-means会随机地初始化类中心,KMEANS_PP_CENTERS,这会导致EM算法得到不同的结果,如果数据量越大,则这种差异性会变小。 如果指定CvEM::...
EM算法的适用场景与简单例子
EM算法是一种迭代算法,分为E、M两步。他就是含有隐变量的概率模型参数的极大似然估计法,或极大后验概率估计法 (将求已知量P(Y|θ)转换为求隐变量P(Y|Z,θ)P(Z|θ)的过程) E步:利用当前估计的参数值,求出...
EM算法像是k-means的应用场景,比如双峰分布的数据,k-means方法,将其看成2-means聚类的方法处理场景。 k-means算法,也被称为k-平均或k-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础。 假定...
这一份总结的主题是无监督学习的EM算法。...EM算法(Expectation maxmization algorithm,最大期望算法)就是一种无监督学习算法,而它的名字本身就已经包含了这个算法的特点以及做法——“期望”、“最大化
EM算法和高斯混合模型的学习
标签: 统计学
EM算法和高斯混合模型学习一、EM算法的引入EM(expectation maximization)算法在李航的书《统计学习方法》中的定义如下:EM是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计,或者极大后验概率的估计。...


EM算法通俗例子What is the expectation maximization algorithm?
第一次接触EM算法,是在完成半隐马尔科夫算法大作业时。我先在网上下载了两份Baum-Welch算法的代码,通过复制粘贴,修修补补,用java实现了HMM算法(应用是韦小宝掷两种骰子的问题)。然后,参考有关半隐马尔科夫...
之前一直用R,现在开始学python之后就来...有三类比较常见的聚类模型,K-mean聚类、层次(系统)聚类、最大期望EM算法。在聚类模型建立过程中,一个比较关键的问题是如何评价聚类结果如何,会用一些指标来评价。 ....
李航著 清华大学出版社EM算法介绍及总结EM算法是一种迭代的算法,1977年由Dempster等人提出,用于含有隐变量(Hidden Variable)的概率模型参数的极大似然估计(不了解的可以参考我的另一篇博客,极大似然估计),或...
EM算法结构如下所示: SAGE算法结构如下所示: 这里主要以SAGE的基本结构进行算法仿真。整个MATLAB的算法的流程如下所示: 第1步:参数初始化; 第2步:产生发送信号,主要函数是产生论文中的s函数; 第3步...
下面代码为PRML所附的基于混合高斯(MoG)的代码,个人认为编码可读性和风格都值得借鉴。...% Perform EM algorithm for fitting the Gaussian mixture model. % Input: % X: d x n data matrix % ini
以下是本blog内的微软面试100题系列,经典算法研究系列,程序员编程艺术系列,红黑树系列,及数据挖掘十大算法等5大经典原创系列作品与一些重要文章的集锦: 一、微软面试100题系列 横空出世,席卷Csdn--评...
GMM(混合高斯模型)的EM算法1.算法理论p(x)=∑Kk=1πkN(x|μk,εk)p(x)=\sum_{k=1}^{K}{\pi_{k}N(x|\mu _{k},\varepsilon _{k})}N(x|μk,εk)=1(2π)d|εk|√exp(−12(xi−μk)Tε−1k(xi−μk))N(x|\mu _{k},\var...

说明:此篇是作者对“EM”的第二次总结,因此可以算作对上次总结的查漏补缺以及更进一步的理解,所以很多在第一次总结中已经整理过的内容在本篇中将不再重复,如果你看的有些吃力,那建议你看下我的第一次总结: ...

推荐文章
- EVO-CNN-LSTM-multihead-Attention能量谷算法优化模型结合多头注意力机制多维时序预测-程序员宅基地
- Objective-C 中的id到底是什么-程序员宅基地
- 好记性不如烂笔头---Archlinux优化简介-程序员宅基地
- 3DREM16P-7X/250YG24-8K4V比例减压阀放大器-程序员宅基地
- python文件操作(open()、write()、writelines()、read()、readline()、readlines()、seek()、os)_python open writeline-程序员宅基地
- 分布式限流实战--redis实现令牌桶限流_分布式令牌限流-程序员宅基地
- 【Linux】文件系统-程序员宅基地
- python实现ks算法_python, 在信用评级中,计算KS statistic值-程序员宅基地
- 类加载过程 与 代码的执行顺序_类加载后代码的执行顺序-程序员宅基地
- Oracle LiveLabs实验:Introduction to Oracle Spatial Studio_oracle_spatial 可视化-程序员宅基地