cv::ml::KNearest:K最近邻(K-Nearest Neighbors)是一种基于实例的学习方法,它通过计算输入样本与训练样本之间的距离来...cv::ml::DTrees:决策树(Decision Trees)是一种常见的机器学习算法,用于分类和回归问题。
”无监督学习和监督学习的区别“ 的搜索结果
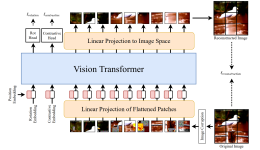
监督学习、无监督学习与强化学习
机器学习可以分为两大类:监督学习和无监督学习。今天介绍机器监督学习和无监督学习。举一个简单的例子:你小时候见到了狗和猫两种动物,有人告诉你这个样子的是狗、那个样子的是猫,你学会了辨别,这是监督学习;你...
在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。这么说可能理解起来不是很清晰,没关系,后面有具体的例子。监督学习可分为“回归”和“分类”...
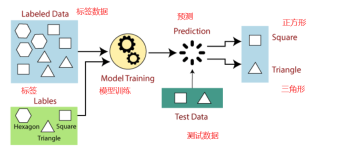
前言 机器学习分为:监督学习,无监督...在这里,主要理解一下监督学习和无监督学习。 监督学习(supervised learning) 从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测...
机器学习是一种人工智能领域的技术,它旨在...机器学习分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)、强化学习(Reinforcement Learning)四种
2] 无监督学习-聚类算法是把 "所有对象" 按照具体特征组织 "拆分到若干个类别" (分类别却不是提取预定义的)[1] 有监督学习-分类算法是把 "某个对象" 划分到某个具体的 "已经定义的类别" (分类的类别是提取预定义的)...
机器学习两种方法——监督学习和无监督学习(通俗理解).pdf机器学习两种方法——监督学习和无监督学习(通俗理解).pdf机器学习两种方法——监督学习和无监督学习(通俗理解).pdf机器学习两种方法——监督学习和无监督...
1、什么是无监督学习? 无监督学习是机器学习技术中的一类,用于发现数据 中的模式。利用 学习数据的分布或...监督学习描述的任务是:当给定输入x,如何通过在有标注输入和输出的数据上训练模型而能够预测输出y ...

和无监督学习不同,自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。 换句话说:自监督学习的...
无监督学习:通过无标签的数据,学习数据的分布或数据与数据之间的关系。 1. 降维算法 1 定义:用低维的概念去类比高维的概念.将高维的图形转化为低维的图形的方法。 1.1. 算法模块 :PCA算法、NMF(非负矩阵分解)...
监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有...
机器学习,监督学习,无监督学习,推荐系统,深度学习,python,代码实战,数据挖掘,sklearn库,
【无监督学习和有监督学习的区别】
标签: 经验分享
1、有监督学习:通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。就如有标准...
本篇文章是用来当做笔记的,如有侵权,联系删除。 ****************************************************************************************************...在机器学习过程中,我们经常听到监督学习和无监督学习,
无监督学习: 所有数据都没有标签,通过Encoder-Decoder结构对输入进行编解码操作,解码输出的结果与原始输入图像对比计算loss函数,进行训练,从而使encoder部分提取出输入数据的特征,实现聚类 特点:提取出来的...

1、Supervised learning监督学习 是有特征(feature)和标签(label)的,即便是没有标签的,机器也是可以通过特征和标签之间的关系,判断出标签。举例子理解:高考试题是在考试前就有标准答案的,在学习和做题的...

注:其实现在很多论文里对自监督和无监督已经不做区分。
有监督学习和无监督学习的区别
无监督学习是机器学习的一个重要分支,其在机器学习、数据挖掘、生物医学大数据分析、数据科学等领域有着重要地位。本书阐述作者近年在无监督学习领域所取得的主要研究成果,包括次胜者受罚竞争学习算法、K-means...
DataVisor作为率先将无监督技术运用在反欺诈行业的娇娇领先者,我们在本文中,将深入浅出的讲解无监督机器学习技术与有监督技术在不同方面的区别,通过对比这两种技术,让大家对无监督反欺诈技术有更好的了解。...
无监督学习 两者的区别主要是是否需要人工参与数据结果的标注 监督学习:教计算机如何去完成预测任务(有反馈),预先给一定数据量的输入和对应的结果即训练集,建模拟合,最后让计算机预测未知数据的结果。 监督...
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地