
”无监督学习“ 的搜索结果
导读:学习究竟是什么?简单来说,学习是在外部刺激下记住大部分以往的经验,从而能够实现改变的能力。因此,机器学习是一种工程方法,对于增加或提高自适应变化的各项技术都十分重要...

监督学习、无监督学习、半监督学习和强化学习是机器学习中常见的学习方式。监督学习是利用标记数据进行训练,可以用于分类、回归等任务。无监督学习则是利用未标记数据进行训练,可以用于聚类、异常检测等任务。半...
无监督学习是机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。无监督学习的主要运用包含:聚类分析、关系规则、维度缩减。它是监督式学习和强化学习等策略之外的一种选择。 一...
监督学习(Supervised learning): 监督学习即具有特征(feature)和标签(label)的,即使数据是没有标签的,也可以通过学习特征和标签之间的关系,判断出标签——分类。 简言之:提供数据,预测标签。比如对...
聚类算法(无监督学习)
标签: 机器学习

机器学习之应用无监督学习 什么情况下考虑无监督学习: 无监督学习适用的场景是,您想要探查数据,但还没有特定目标或不确定数据包含什么信息。这也是减少数据维度的好方法。 无监督学习技术: 绝大多数无监督...

分类回归问题分类问题无监督学习算法1.定义2.分类聚类 机器学习算法中,可以分为: 监督学习算法 无监督学习算法 监督学习算法 1.定义 监督学习是指,我们给算法一个数据集,其中包含了正确的答案,比如我们给...
三维点云去噪无监督学习:ICCV2019论文分析 Total Denoising: Unsupervised Learning of 3D Point Cloud Cleaning 论文链接: ...
有时神经网络需要接收大量输入信息,比如输入高清图片时,神经网络从上千万个信息源中学习是个非常吃力的工作,所以需要从原图像中提取出最具代表性的信息,再把缩减过后的信息放进神经网络中学习。将源数据 白色X,...
自编码器是深度学习中的一种非常重要的无监督学习方法,能够从大量无标签的数据中自动学习,得到蕴含在数据中的有效特征.因此,自编码方法近年来受到了广泛的关注,已成功应用于很多领域,例如数据分类、模式识别、异常...

监督学习:根据已有的数据集,我们知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。监督学习主要分为分类问题和回归问题。 分类问题:输出结果是有限个结果,比如结果集为T={A,B,C...
事先先说明一下:标签就是指的分好的类别,指明标签就是告诉...输入数据有标签,则为有监督学习,没标签则为无监督学习。首先看什么是学习(learning)?一个成语就可概括:举一反三。此处以高考为例,高考的题目在上
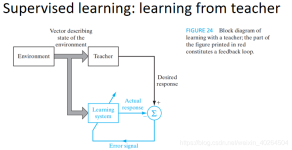
有监督学习及无监督学习的区别
标签: 机器学习
无监督没有训练过程,直接拿数据进行建模分析。 有监督的核心是分类,无监督的核心是聚类。有监督的工作是选择分类器和确定权值,无监督的工作是密度估计,即只要知道如何计算相似度就行了。 有监督不具备降维的能力...
何用无监督学习技术来识别数据集中的模式和结构。 无监督学习是用于探索性分析的一系列很有价值的技术。它们能够挖掘出隐藏在数据集中的模式和结构,获取有用的信息或为进一步分析提供指导。拥有一套可靠的无监督...

0. 写在前面的话 1. 无监督学习基本原理 2. 基本问题 2.1 聚类 2.2 降维 2.3 概率生成模型 3. 无监督学习三要素 4. 无监督学习方法 4.1 聚类 4.2 降维 4.3 话题分析 4.4 图分析
无监督学习:如何应用生成式模型进行文本分类 生成式模型是一种强大的工具,可以帮助我们对大量的文本数据进行分类和建模。然而,无监督学习技术在文本分类领域中却显得有些过时和低调。本文旨在探讨如何将无监督...

无监督学习 定义:只从无标签的数据中学习出一些有用的模式 典型的无监督学习:深度学习中只考虑前两个问题即可 无监督特征学习: 主成分分析(Principal Component Analysis PCA) 一种最常用的数据降维...

无监督学习的目标是通过学习数据的结构和模式,对数据进行整理和组织,而不需要预先指定的标签信息。监督学习的目标是使模型能够对新的、未标记的数据进行正确的分类或预测。强化学习是一种机器学习的方法,旨在让...
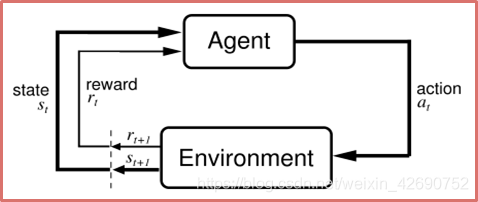
一、基本概念1 特征(feature) 数据的特征。举例:书的内容2 标签(label) 数据的标签。举例:书属于的类别,例如“计算机”“图形学”“英文书”...这样当有特征而无标签的未知数据输入时,我们就可以通过已有的
监督学习与无监督学习
标签: 深度学习

推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地