wechat_spider 使用“代理”的方式来抓取微信公众账号文章,使用 anyproxy 作为代理
”文章抓取工具“ 的搜索结果

这篇文章的第一个目标是阐明网络抓取工具的运作方式,并解释为什么人们不应该认为网络抓取本质上比人类浏览网页更麻烦或更具侵入性。 本文的第二个目标是更全面地阐明法院如何处理最重要的问题,即网络抓取工具是否...
大数据技术用了多年时间进行演化,才从一种看起来很炫酷的新技术变成了企业在生产经营中实际部署的服务。其中,数据采集产品迎来了广阔的市场...作为采集界的老前辈,我们火车头是一款互联网数据抓取、处理、分析,...
现在有很多自媒体平台,如头条号、搜狐号、大鱼号、百家号等,每个人...如果想把某个作者的文章都下下来,一篇一篇的下载会很麻烦,而用爬虫则会很简单,顺便还能练练手。这里就以抓取规则比较比较简单的搜狐号来开到。
加密狗破解教程-数据抓取工具.mp4 使用方法:第一步:安装好要逆向的软件,确保使用正常;第二步:安装数据抓取工具(看系统类型,64位的安装X64,32位的安装X32)第三步:打开软件,找到正确的加密狗(如...
chrome 抓取图片So you have a website you want to scrape? But don’t necessarily know what package to use or how to go about the process. This is common when first starting out web scraping. ...



seo软件全网站死链接重复文章检查工具足迹 1、主要功能:抓取网站所有链接,并进行测试,找出死链接,循环黑洞链接,会受百度等搜索引擎惩罚的非法页面。 2、支持单个域名下页面千万级别的网站数据抓取和诊断。 3、...
这篇文章主要介绍了基于python3抓取pinpoint应用信息入库,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pinpoint是用Java编写的大型分布式系统的APM(应用...

一种将 NYTimes 文章分类为主观或客观的工具。 波莫纳学院 Kauchak 教授 CS159(自然语言处理)课程的期末项目 项目概况 我们使用纽约时报 API 创建来自一般新闻和专栏文章的语料库。 我们访问article_urls.py中的...

爬取微信小程序源码工具
标签: 微信游戏
之前码云失效的文件,有幸本地保存了一份,发给大家分享,使用办法可见我的博客文章《爬取微信小程序源码》
记录一下今天的成果,确实可以抓取到,配置完成之后1分钟可以抓取100+(后来优化了一下,可以达到300左右)片吧,我没有用多进程... 第二:通过抓包工具截取htts请求的数据包,意思就是使用pc端微信登录,监听公众...
用于新闻文章分析的抓取和情感检测实用程序 目的说明 应处理和分析新闻文章,以便为社交媒体分析提供“比较点”。 在线新闻门户很少在布局上相似,并且经常更改其网站的设计、档案的结构、文章的可用性等。因此,与...
目前中国知网的文献信息都能通过文章的DOI信息提取,通过访问文章对应的属性页面,自动提取相应区段的信息,方便管理文献,内含安装工具,示例数据和安装说明等,均为自主研发的,感兴趣的朋友可以下来玩玩
目前已测试可采集大部分网站上的图文素材,包括百度文库、360图书馆、起点中文等相关站点的文章文字,就算网页不允许复制也能抓取。 网页打开过程视你网速快慢,可能需要几秒钟。这过程中若是弹出“安全警报”的...

需求:抓取人民网微信公众号的文章和评论 使用工具: fiddler python3 微信pc客户端 破解过程: 首先 使用fiddler对微信pc端抓包,需要配置https证书,另外最好加个filter方便抓取 然后操作微信客户端获取公众号...
5线刮板机 Web爬虫教程,使用Python和BeautifulSoup4。 在查看 入门 将此仓库克隆到您的计算机上,然后pip ...网页抓取工具 -简化HTTP请求的库 作者 Kameron羽衣甘蓝-概览- 致谢 特别感谢让我课。 感谢的个人邀请。
PHP有许多开源的爬虫工具,如snoopy,这些开源的爬虫工具,通常能帮我们完成大部分功能,但是在某种情况下,我们需要自己实现一个爬虫,本篇文章对PHP实现爬虫的方式做个总结。 PHP实现爬虫主要方法 1.file()...
本文节选自《Python爬虫技术:深入理解原理、技术与开发》。本文将实现可以抓取博客文章列表的定向爬虫。定向爬虫的基本实现原理与全网爬虫类似,都需要分析HTML代码,只是定向爬虫可能并不会...
在电脑上安装 mitmproxy代理,手机和电脑连同一wifi,手机配置当前电脑为代理服务器,然后手动查看公众号历史文章列表,这样电脑上就可以获得列表,然后再根据列表中的详情url拿到公众号文章详情。 1.1 安装...
用于关键字研究的简单工具。 KeywordCrawler是我开发的一个小型PHP脚本,用于提取前20个关键字,计算每个关键字在页面上的使用次数,然后在逗号分隔的列表中显示较长的关键字列表,以帮助您建立最相关的关键字...
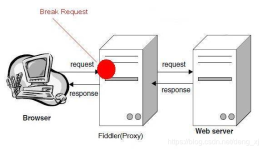
Fiddler是一款免费的Web调试代理工具,也是目前最常用的“HTTP”抓包工具之一,它可以截取HTTP/HTTPS流量并且允许你查看、分析和修改这个流量。Fiddler在Web开发和测试中非常有用,因为它可以帮助你检查Web应用程序...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地