无
”数据挖掘与机器学习-聚类算法“ 的搜索结果
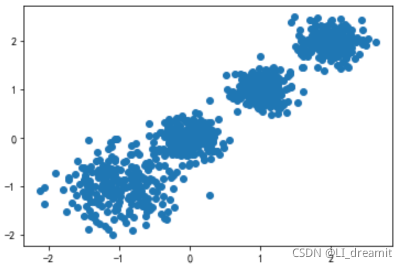
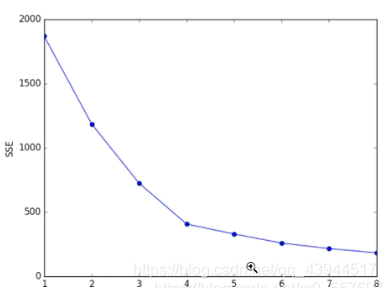
分类算法必须需要训练数据,训练数据包含物品的特征和类别(label,也可以被称作标签),这相当于对这些数据建立了映射规则,这种映射规则可以通过机器学习相应的算法来建立,当需要对新的数据进行分类时,就可以直接...

聚类分析所涉及到的所有方面 和 经典划分聚类:K-means算法及其在python中的运用实例;补充介绍的内容包括:sklearn.datasets numpy.ndarray sklearn.cluster matplotlib.pyplot.scatter


广州大学机器学习与数据挖掘实验代码 实验1 组员信息 1.梁兆豪(组长): TXT数据源读入与数据处理 2.林嘉伟: 数据库数据源读入与数据处理 3.叶建忠: 完成数据计算 作业题目和内容 广州大学某班有同学100人,现要从两个...
本次实验是一场聚类算法的深度探索之旅,涵盖了K-means、K-medoids、DBSCAN和凝聚聚类等引人注目的算法。K-means通过巧妙的迭代将样本点划分到K个簇,并通过聚类中心的不断更新优化结果。尽管简单高效,但对初始...
可以看出训练样本是有明确的标签的,数据点是有已知结果的,而聚类不同,聚类算法本身训练的样本就是无标签的,你不知道它属于哪一类,而把具有空间相近性、性质相似性的数据点归为一类,这就是聚类算法要做的事情。...
聚类技术属于机器学习中的无监督学习,与监督学习不同,聚类中没有数据类别的分类或者分组信息。聚类并不关心某一类别的信息,其目标是将相似的样本聚在一起。因此,聚类算法只需要知道如何计算样本之间的相似性,就...
一 算法概述 1 算法概念 高斯混合模型(GMM)是指由多个高斯模型线性叠加,描述了数据本身的一种分布情况,其中每个高斯模型称为一个component

机器学习算法的分类 一、什么是聚类分析 物以类聚,人以群分 二、相似度与距离度量
探索DBSCAN算法的内涵与应用,本文详述其理论基础、关键参数、实战案例及最佳实践,揭示如何有效利用DBSCAN处理复杂数据集,突破传统聚类限制。

机器学习-KMeans聚类 K值以及初始类簇中心点的选取2.K-Means算法的研究分析及改进一、K-means算法原理K-means算法是最常用的一种聚类算法。算法的输入为一个样本集(或者称为点集),通过该算法可以将样本进行聚类,...
但在有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法,最为典型的当属聚类算法。 K-Means聚类算法利用距离远近的思想将目标数据聚为指定的k个簇,进而使样本呈现簇内差异小,簇间...
一 聚类算法概述 1 聚类的概念 给定数据集(仅有特征属性,无目标属性),依据样本之间的特征属性,将样本聚类为不同聚簇(簇),从而实现簇内样本相异度低,簇间样本相异度高 2 聚类算法的评价指标 1)轮廓系数...

聚类算法属于无监督学习范畴,为了便于记忆,简单的将韩家炜《数据挖掘:概念与技术》简单的总结为四种:基于距离,基于密度,基于层次,基于网格。 1. 基于距离 2. 基于密度 3. 基于层次 4. 基于网格 ...

引言: 数据挖掘的本质是“计算机根据已有的数据做出决策”,其对社会的价值... 算法是数据挖掘最核心的部分,作为一名学习新人,在参考《数据挖掘导论》、《Python数据分析与挖掘实战》、《Python数据挖掘入门与实战

聚类算法:(无监督的分类算法,核心是要确定类别(簇或组的个数)和相似性度量方法 聚类分析的作用: 作为一个独立的工具来获取数据集中数据的分布情况 首先对数据集进行聚类从而获取所有簇; 然后每个...
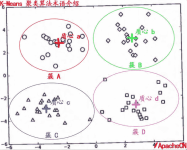
聚类算法是一种无监督学习 一、无监督学习 在无监督学习(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。...
用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。 设 ...
推荐文章
- javafx预览PDF_javafx pdf-程序员宅基地
- ipv4与ipv6访问_纯ipv4访问纯ipv6-程序员宅基地
- css强制换行-程序员宅基地
- 链霉亲和素修饰的CdSe–ZnS量子点-程序员宅基地
- 饿了么4年 + 阿里2年:研发路上的一些总结与思考-程序员宅基地
- vue的sync语法糖的使用(组件父子传值)_sync传值-程序员宅基地
- 最大流最小割_网络最大流量与割的容量的关系-程序员宅基地
- queryString模块_querystring模块安装-程序员宅基地
- 安卓电量检测工具Battery Historian的使用记录_battery-historian 电量测试-程序员宅基地
- 基于QPSK的载波同步和定时同步性能仿真,包括Costas环的gardner环_qpsk符号同步-程序员宅基地