
”数据分析——pandas(三)_LateNight_LL的博客-程序员宅基地“ 的搜索结果
Pandas read_excel()参数使用详解 read_excel函数原型 def read_excel(io, sheet_name=0, header=0, names=None, index_col=None, parse_cols=None, usecols=None, squeez
Python pandas sort_values()方法的使用
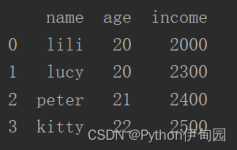
Python基础学习—Pandas数据分析实战剖析 我们选用的数据集是关于电商销售的记录,包含了商品、销售额、日期等信息。数据集的目标是通过分析这些数据,洞察销售趋势、热门商品以及销售额的波动。
sort_values()是pandas中比较常用的排序方法,其主要涉及以下三个参数: by : str or list of str(字符或者字符列表) Name or list of names to sort by. 当需要按照多个列排序时,可使用列表 ascending : bool ...

在用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”,我对两个函数是这样理解和区分的。 常见的数据的层次化结构有两种,一种是“花括号”(下图左),...
pandas.read_sql 可以在数据库中执行指定的SQL语句查询,以DataFrame 的类型返回查询结果。 import sqlalchemy import pandas as pd # 创建数据库连接,这里使用的是pymysql engine = sqlalchemy.create_engine(...
问题记录 return self._engine.get_loc(key... File "pandas/_libs/index.pyx", line 107, in pandas._libs.index.IndexEngine.get_loc File "pandas/_libs/index.pyx", line 131, in pandas._libs.index.IndexEng...
B business day frequency 工作日频率 C custom business day frequency 自定义工作日频率 D calendar day frequency 日历日频率 W weekly frequency 每周频率 M month end frequency 月末频率 ...
pandas to_csv()写入函数参数详解 DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=...
File “pandas/_libs/hashtable_class_helper.pxi”, line 1218, in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas/_libs/hashtable.c:20477) 原因: 百度了很久,后来查看...
pandas.date_range命令查看date_range函数帮助文档 语法:pandas.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs) 该函数主要用于生成一...
既然找到解决乱码的方法,那么想要将pandas中的数据类型存储到json中就只需要先将其转换为python自带的数据类型,再利用 json 类库其转换为json格式并存储就可以了,因为我自己是为了将python处理好的数据转换为json...
Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持。 Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) 。panel data是经济学中关于多维数据...

C extension: No module named pandas._libs.tslibs.base No module named ‘pandas._libs.tslibs.base’ 使用pyinstaller打包pandas程序的时候遇到了这个问题。打包过程没有问题,运行打包好的程序就抛出这个关键...
使用pandas的read_table方法读取本地文件时,爆出这个错误: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xce in position 52: invalid continuation byte 错误原因是‘utf-8’不能解码位置52的...
Python语言中,Pandas中的get_dummy()函数是将拥有不同值的变量转换为0/1数值。 举例说明:一群样本的年龄分别为19,32,56,94岁,19岁用1表示,32岁用2表示,56岁用3表示,94岁用4表示。1,2,3,4这些数值的大小本身...

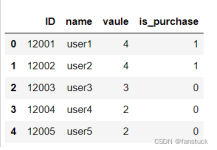
参数 drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False inplace: 是否在原DataFrame上改动,默认为False ...import pandas as pd import numpy as np df = pd.DataFrame([('bird', 3

成功解决pyinstaller打包AttributeError:type object pandas._TSObject has no attribute _reduce_cython_ 目录 解决问题 解决方法 解决问题 pyinstaller打包出现AttributeError:type object ...


推荐文章
- Java---简单易懂的KNN算法_jf.knn-%; 9 &-程序员宅基地
- 最新版ffmpeg 提取视频关键帧_从视频中获取flag-程序员宅基地
- 【ARM Cache 系列文章 11 -- ARM Cache 直接映射 详细介绍】
- Objective-C学习计划
- 【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码
- python访问组策略_python 模块 wmi 远程连接 windows 获取配置信息-程序员宅基地
- html把div做成透明背景,DIV半透明层 CSS来实现网页背景半透明-程序员宅基地
- 关机恶搞小程序
- mnist手写数字分类的python实现_TensorFlow的MNIST手写数字分类问题 基础篇-程序员宅基地
- wxpython窗口跳转_WxPython-用按钮打开一个新窗口-程序员宅基地