2. 执行以下命令,解压Hadoop安装包至/opt/hadoop。3. 启动成功后,执行以下命令,查看已成功启动的进程。5. 执行以下命令,测试Hadoop是否安装成功。3. 执行以下命令,配置Hadoop环境变量。1. 执行以下命令,下载...
”什么是Hadoop“ 的搜索结果
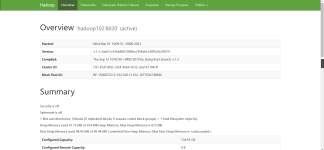
启动Hadoop 进入HADOOP_HOME目录。 执行sh bin/start-all.sh 关闭Hadoop 进入HADOOP_HOME目录。 执行sh bin/stop-all.sh 1、查看指定目录下内容 Hadoopdfs –ls [文件目录] eg: hadoop dfs –ls /user/wangkai....
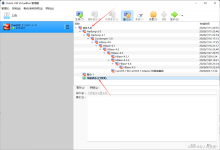

1 使用CentOS7安装hadoop模板机 1.1 CentOS7安装配置流程 1.1.1 创建VMware虚拟机,使用CentOS7系统,命名为hadoop100 补充说明:我这里VMware的虚拟网络设置 VMware子网IP:192.168.10.0, 网关:192.168.10.2 ...


Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据的丢失。 2. 高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。 3. 高效性: 在MapReduce的思想下,...
有些同学在Windows下解压安装好Hadoop后执行。
如何配置HADOOP_CLASSPATH
Hadoop中的dr.who是什么? 1.问题 今天在查看自己的hadoop web ui的时候,发现了如下的界面: 仔细看右上角,发现这里登陆的用户名是:dr.who,这个dr.who是谁呢?难道是别黑客入侵了?【一般不可能是黑客入侵,...
今天突然想到这个问题 但网上都是些复制粘贴的内容 不能很好地解答 经过查找资料 我在这里给出我的说明 仅供参考: 尽管Spark相对于Hadoop而言具有较大优势(速度快),但Spark并不能完全替代Hadoop,主要用于...
hadoop中分区详解
标签: hadoop
1.hadoop 的默认分区原则: mapTask 之后的数据进入哪个reduceTask的规则 默认规则是: 按照keyd的hashCode % reduceTask 数量 = 分区号 默认reduceTask 数量为1 可以在driver 端进行设置 2. hadoop 的分区作用在...
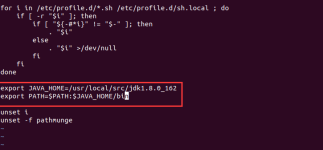
hadoop安装后运行hadoop version 报找不到命令 [root@localhost devlops]# hadoop version ERROR: JAVA_HOME is not set and could not be found. 原因:需要配置环境变量,并且设置java_home的路径: 1、编辑/etc/...
Hadoop 中文教程 。包括快速入门,集群搭建,分布式文件系统,命令手册等文件。



6.三个节点设置静态ip(之前博客有发这里不再进行演示)。同样的方式创建bigdata03节点这里不再进行演示。

Hadoop之web查看HADOOP以及文件的上传和下载


删除文件 hdfs fs –rm [文件地址] 例如: hdfs dfs –rm /user/spark/applicationHistory/local-1564737954168 删除文件后文件会存放至 /user/hdfs/.Trash中,hdfs的回收站,可设置回收站清理时间 ...
Hadoop单机版安装
标签: hadoop

Hadoop自从出现到现在被广泛应用,经理了很多个版本的衍化,甚至各个公司都在原生apache hadoop的基础上进行了一些改造以及特性优化,有些是完善了一整套的集群部署工具,在这衍化的过程中出现了Apache hadoop官方...
本人搭建的伪分布式集群,Hadoop集群启动没有Datanode,一开始以为是配置问题,检查了发现没什么问题,后来发现是Datanode与Namenode之间的ClusterID不一致导致的。 可能造成的原因:频繁的格式化namenode 环境:...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地