该函数将输入数据视为模型输出的概率分布,将目标标签视为类别索引,并计算这些概率与实际标签之间的交叉熵损失。其中,xi表示真实标签的第i个元素,yi表示模型预测x属于第i个类别的概率。清空梯度,计算模型...
”交叉熵损失函数“ 的搜索结果
交叉熵损失函数原理详解 之前在代码中经常看见交叉熵损失函数(CrossEntropy Loss),只知道它是分类问题中经常使用的一种损失函数,对于其内部的原理总是模模糊糊,而且一般使用交叉熵作为损失函数时,在模型的输出层...
论文中"Holistically-Nested Edge Detection"使用的加权损失函数,具体用法见博客http://blog.csdn.net/majinlei121/article/details/78884531

理解交叉熵损失函数 在机器学习领域,交叉熵损失函数是一种常用于分类问题的损失函数。它衡量的是模型输出的概率分布与实际标签的差异。通过最小化交叉熵损失,我们可以提高模型的分类准确度,使其更好地符合实际...
1. 背景介绍 机器学习和深度学习的浪潮席卷全球,分类任务作为其中最为基础且应用广泛的任务类型,扮演着不可或缺的角色。从图像识别到自然语言处理,从垃圾邮件过滤...交叉熵损失函数(Cross-Entropy Loss Function)

目标几乎总是最小化损失函数。损失越低,模型越好。交叉熵损失是最重要的成本函数。它用于优化分类模型。对交叉熵的理解取决于对 Softmax 激活函数的理解。我在下面写了另一篇文章来涵盖这个先决条件考虑一个4类分类...

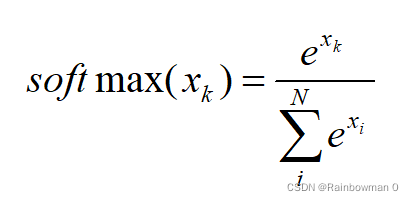
该标准计算输入 logits 和目标之间的交叉熵损失。
torch.nn.CrossEntropyLoss(weight, reduction=“mean”)的计算方式和一般做法不一样,进行加权计算后,不是直接loss除以batch数量,而是batch中每个数据的标签对应的类别权重 把batch个权重加起来作为除数,被除数...
交叉熵损失函数--轻松了解
标签: 机器学习
假设第一个输出神经元是猫,第二个是小狗,第三个是小鸟如果传入猫照片,猫的神经元输出数值相比其他越大,计算的损失值会越小,也表明越靠近真实结果。如果训练时,类别分错了,则会出现大的。
交叉熵损失函数 说到交叉熵损失函数(Cross Entropy Loss),就想到公式:L=−[ylogy^+(1−y)log(1−y^)]L=-[ylog \hat y + (1-y)log(1- \hat y)]L=−[ylogy^+(1−y)log(1−y^)] 大多数情况下,这个交叉熵函数...
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,...
PyTorch、人工智能、损失函数、交叉熵、Softmax
交叉熵是信息论中的一个重要概念,它的大小表示两个概率分布之间的差异,可以通过最小化交叉熵来得到目标概率分布的近似分布。为了理解交叉熵,首先要了解下面这几个概念。信息论的基本想法是,一个不太可能的事件...
损失函数——交叉熵损失函数(CrossEntropy Loss) 交叉熵函数为在处理分类问题中常用的一种损失函数,其具体公式为: 1.交叉熵损失函数由来 交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的...
一直以来看到还以为是很复杂的东西,原来其实是,也就是二元交叉熵损失函数其实就是交叉熵损失函数。
P(x)代表真实分布的概率,Q(x)代表在预测分布中的概率,log代表...交叉熵损失函数还具有平滑性和凸性质,能够保证优化过程的稳定性和收敛性。在机器学习中用于损失函数。在信息论中,用于衡量两个概率分布之间的差异。
手撕算法笔记--手撕交叉熵损失函数
标签: 算法
其中,y_pred表示模型预测的概率值,y_true表示真实的类别标签。其中,N表示batchsize的大小,M表示类别的个数。1-1--二元交叉熵。1-2--多元交叉熵。

在训练分类器时,通常将标签视为单热向量,即只有正确的类别概率为1,其余...是一个长度为类别数的向量,每个元素表示对应类别的权重,当一个类别的权重被设置为大于1的值时,该类别对损失函数的贡献将会变得更加重要。
Python、PyTorch、人工智能、损失函数
本篇文章会更细地讲一下tensorflow中交叉熵损失函数的应用,以及在优化过程中可能用到加权交叉熵损失函数的使用方式。 一、基础计算 当存在多个类别时,通常使用交叉熵损失函数来衡量模型的效果,也是对模型调参的...
一文读懂交叉熵损失函数
标签: 机器学习

快速入门交叉熵损失函数的原理和代码。
一个使用 Tensorflow 库在 Python 中实现交叉熵损失函数的示例,在实际中,您需要使用更高级的技巧,如对不平衡类别进行损失权重,并使用不同的参数和技术来调整模型以获得更好的性能。
前面小编给大家简单介绍过损失函数,今天给大家继续分享交叉熵损失函数,直接来看干货吧。一、交叉熵损失函数概念交叉熵损失函数CrossEntropy Loss,是分类问题中经常使用的一种损失函数。公式为:接下来了解一下...
理解交叉熵关于样本集的两个概率分布p和q,设p为真实的分布,比如[1, 0, 0]表示当前样本属于第一类,q为拟合的分布,比如[0.7, 0.2, 0.1]。按照真实分布p来衡量识别一个样本所需的编码长度的期望,即平均编码长度...
推荐文章
- Windows系统鼠标右键菜单添加打开cmd终端_we右键进入cmd-程序员宅基地
- python汇编语言还是机器语言_深入理解计算机系统(3.1)------汇编语言和机器语言...-程序员宅基地
- android毕设各种app项目,安卓毕设,android毕设_app毕业设计-程序员宅基地
- Keil侧边工具栏(项目窗口)打开方式_keil侧边栏-程序员宅基地
- 算法学习,转载记录(持续记录)-程序员宅基地
- 局域网探测器_局域网检测-程序员宅基地
- 【C语言基础系列,阿里java面试流程_c语言java面试-程序员宅基地
- Linux技术简历项目经验示例(二)_linux简历工作经验怎么写-程序员宅基地
- 安卓手机软键盘弹出后不响应onKeyDown、onBackPressed方法解决方案-程序员宅基地
- 使用二维数组实现存储学生成绩_c#创建控制台应用程序studentscore,生成学生成绩单——二维数组的使用。-程序员宅基地