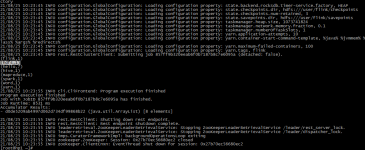
1. 启动hadoop和spark cd /usr/local/Cellar/hadoop/3.2.1/sbin ./start-all.sh cd /usr/local/Cellar/spark-3.0.0-preview2/sbin /start-all.sh 2. 引入依赖 依赖的版本号要与安装程序的版本号保持一致。...
”wordcount“ 的搜索结果
FLlink 流批处理WordCount案例实现 Flink 从文件读取数据实现WordCount Flink 从Socket读取数据WordCount
wordcount.jar
WordCount的实现1.项目分析:本词频统计器包括行数统计、字符数统计、单词数统计、词频统计功能,本词频系统由Java完成。1.运用到了对字符串的截取split方法,以及IO流对文件读取读写的操作。2.对Java项目的jre打包...

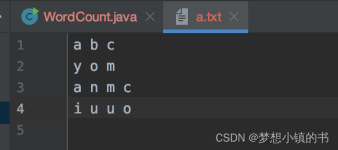
WordCount.java
Spark基本的概念以及wordcount的例子
201631103228,2016311012271.项目需求对程序设计语言源文件统计字符数、单词数、行数,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。wc.exe -c //返回文件的字符数wc.exe -w /...

Demo1WordCount.java
hadoop入门例子wordcount
介绍如何在Intellij Idea中通过创建maven工程配置MapReduce的编程环境,WordCount代码。
wordcount, mapreduce经典,文字计数
这里我们就以LICENSE.txt文件作为输入源文件,可以查看下license内容:$ cat LICENSE.txt ,我们统计下里面各个单词出现的次数,是不是有点小激动。这是小编自学hadoop的第一个示例程序,虽然简单,但是通过自己对...
javawordcount

wordcount的jar包
标签: java
wordcount的jar包
作为Hadoop的入门程序,我相信大家对wordCount一定不陌生。但是对于刚刚接触Hadoop的人来说,可能很难理解程序运行过程中具体流程是怎么样的。这篇博客我讲讲我对其流程的理解,有错误的地方尽情拍砖。
• 应用 map-reduce 思想解决 wordCount 问题; • 可选)掌握并应用 combine 与 shuffle 过程。 1.2 实验内容 --- 提供 9 个预处理过的源文件(source01-09)模拟 9 个分布式节点,每个源文件中包含一百万个由英文...
wordcount
手写MR程序之wordcount案例(三种提交方式) 一、WordCount案例实操 1)MR原理解析 从不同角度理解MR程序的运行: 1.流的角度: Input --->InputFormat ----> Mapper---> Shuffle ---->Reducer ---&...
学习任何一门语言,都是从helloword开始,对于大数据框架来说,则是从wordcount开始,Spark也不例外,作为一门大数据处理框架,在系统的学习spark之后,wordcount可以有11种方式实现,你知道的有哪些呢?还等啥,不...


wordcount写法2
标签: spark
wordcount写法2

hadoop-wordcount-eg Hadoop WordCount 示例 - Maven 项目Hadoop 以文件系统作为输入和输出使用“现有 Maven 项目”在 Eclipse 中导入项目定位类 WordCountFileSystem 将 inputPath 更改为包含要分析的文件的目录...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地