”spark“ 的搜索结果

IDEA 本地运行Spark
标签: spark


spark序列化方式 分布式的程序存在着网络传输,无论是数据还是程序本身的序列化都是必不可少的。spark自身提供两种序列化方式: java序列化:这是spark默认的序列化方式,使用java的ObjectOutputStream框架,只要是...

随着大数据技术的发展,一些更加优秀的组件被提了出来,比如现在最常用的Spark组件,基于RDD原理在大数据处理中占据了越来越重要的作用。在此我们探索了Spark的原理,以及其在大数据开发中的重要作用。...

2018-11-02 Apache Spark 官方发布了 2.4.0版本,以下是 Release Notes,供参考: Sub-task [ SPARK-6236 ] - 支持大于2G的缓存块 [ SPARK-6237 ] - 支持上传块> 2GB作为流 [ SPARK-10884 ] - ...
Hive和Spark
标签: hive
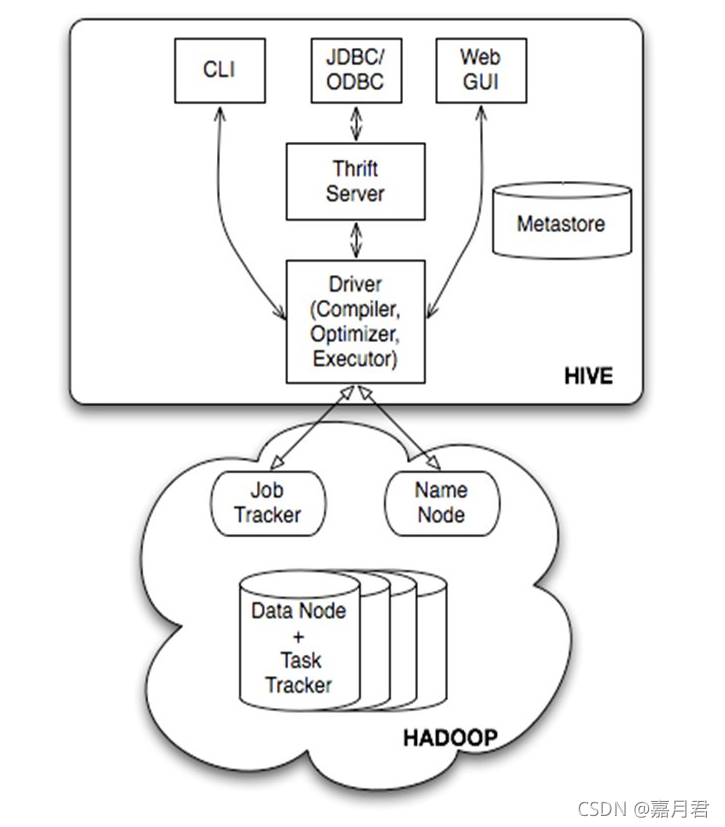
1. Hive简介 hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析...
包括:《Spark大数据处理:技术、应用与性能优 》 《Spark大数据处理技术》 《Spark高级数据分析》 《Spark快速数据处理_中文版》 《大数据Spark企业级实战》 《Spark 编程指南》 方便大家共同学习
我们在之前的文章中 已经了解了 spark支持的模式,其中一种就是 使用k8s进行管理。 hadoop组件—spark----全面了解spark以及与hadoop的区别 是时候考虑让你的 Spark 跑在K8s 上了 spark on k8s的优势–为什么要把...




spark 3.0 终于出了!!! Apache Spark 3.0.0是3.x系列的第一个发行版。投票于2020年6月10日获得通过。此版本基于git标签v3.0.0,其中包括截至6月10日的所有提交。Apache Spark 3.0建立在Spark 2.x的许多创新基础之...
spark-submit 可以提交任务到 spark 集群执行,也可以提交到 hadoop 的 yarn 集群执行。 1. 例子 一个最简单的例子,部署 spark standalone 模式后,提交到本地执行。 ./bin/spark-submit \ --master spark://...

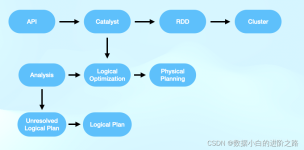
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算...


一、Spark是什么 一、定义 Apache Spark是用于大规模数据处理的统一分析引擎 二、Spark更快的原因 数据结构(编程模型):Spark框架核心 RDD:弹性分布式数据集,认为是列表List Spark 框架将要处理的数据封装...


作者:禅与计算机程序设计艺术。
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地