目录 1 运行行为 1.1 动态生成分区 1.2 broadcast join 使用hint强制做broadcastjoin: 1.3 动态资源分配 ...2.3 executor读取hive表时单task处理数据量/无shuffle作业小文件合并 ...2.4 GC优化(使用较少,当尝试...
”spark“ 的搜索结果
spark重要参数配置
一 Spark概述 1 11 什么是Spark 2 Spark特点 3 Spark的用户和用途 二 Spark集群安装 1 集群角色 2 机器准备 3 下载Spark安装包 4 配置SparkStandalone 5 配置Job History ServerStandalone 6 ...
在上一篇文章《Hadoop集群搭建配置教程》中详细介绍了Hadoop集群搭建的全部过程,今天为大家带来分布式计算引擎Spark集群搭建,还是使用三个虚拟机节点上进行安装部署,围绕Standalone模式和Yarn模式的这两种部署...
Spark内存溢出堆内内存溢出堆外内存溢出堆内内存溢出具体说明Heap size JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,Heap size 的大小是Young ...
该文章主要是描述单机版Spark的简单安装,版本为 spark-3.1.3-bin-hadoop3.2.tgz 1、Spark 下载、解压、安装 Spark官方网站: Apache Spark™ - Unified Engine for large-scale data analytics Spark下载地址:...

spark-core_2.11-2.0.0.jar比spark-core_2.11-1.5.2.jar少了org.apache.spark.Logging.class,故此把缺少的class放到spark-core_2.11-1.5.2.logging.jar里面


spark.executor.memory 包含spark.memory.fraction; spark.memory.fraction 包含 spark.memory.storageFraction; spark 2.4.5 Application Properties Property Name Default Meaning spark.app.name ...

Spark是一个通用的并行分布式计算框架,由UCBerkeley的AMP实验室开发。Spark使得程序员更容易地编写分布式应用,并且能够根据自己的喜好使用Scala、Java或者Python作为开发语言。本书系统讲解了Spark的应用方法,...
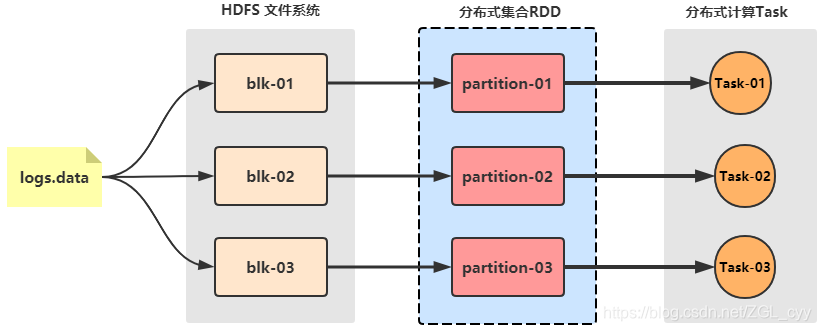
为了避免MapReduce框架中多次读写磁盘带来的消耗,以及更充分地利用内存,加州大学伯克利分校的AMP Lab提出了一种新的、开源的、类Hadoop MapReduce的内存编程模型Spark。一、spark是什么?Spark是一个基于内存的...

工作中spark 的常见问题以及发生的原因和应对策略


Spark最初由美国加州伯克利大学的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。 Spark特点 Spark具有如下几个主要特点: 运行速度快:Spark使用先进...
1.1 将hive-site.xml拷贝到spark/conf目录下: 分析:从错误提示上面就知道,spark无法知道hive的元数据的位置,所以就无法实例化对应的client。 解决的办法就是必须将hive-site.xml拷贝到spark/conf目录下 1.2...
在介绍spark thrift server 需要先介绍一下其与hiverserver2及spark-sql的关系与区别 HiveServer2 Hive提供了一个命令行终端,在安装了Hive的机器上,配置好了元数据信息数据库和指定了Hadoop的配置文件之后输入...
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache的顶级项目,2014年5月发布spark1.0,2016年7月发布spark...
2.4) 修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点 [root@qianfeng01 local]# vi /usr/local/spark-3.1.2/conf/spark-env.sh。2)修改hadoop中的配置文件/usr/local/hadoop-3.3.1/etc/hadoop/...

Spark系列之SparkSubmit提交任务到YARN
推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地