
”shuffle的主要机制“ 的搜索结果

本文讲述的shuffle概念范围如下图虚线框所示,从上游算子产出数据到下游算子消费数据的全部流程,基本可以划分成三个子模块: 上游写数据:算子产出的record序列化成buffer数据结构插入到sub partition队列; ...



2.4.1概述 1)mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫...2)shuffle:洗牌、发牌(核心机制:数据分区、排序、缓存); 3)具体来说:就是将ma...
Spark Shuffle
标签: spark
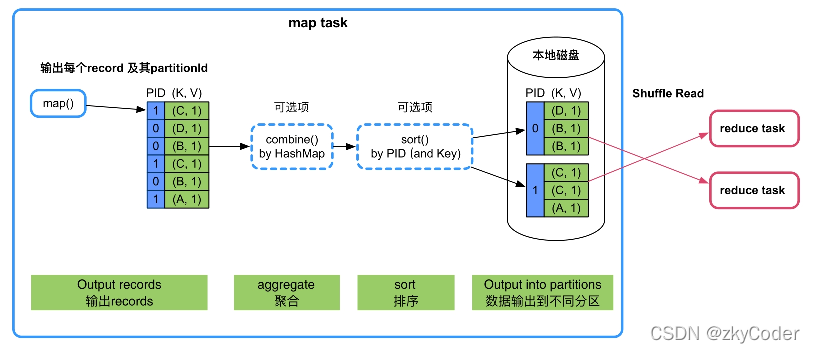
Shuffle机制 Shuffle是在Mapper之后,Reducer之前的操作 分区 默认分区时,若numReduceTask>1,会根据所求key的hashcode值进行分区 设置MAX_VALUES的目的是为了防止hashcode过大 分区时按照条件的不同进行分区,...
一、Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入传给reducer)称为shuffle。 二、Partition分区 (1)问题引出 要求将统计结果按照条件输出到不同文件中...
Shuffle这个词其实可以翻译成『数据重分布』,Shuffle是Spark用于执行数据重分配的机制,以便对数据实现跨分区重新分组操作。这会导致跨执行器和机器的数据复制,因此它是一个复杂且消耗资源的操作。...

SparkShuffle SparkShuffle概念 reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的...

Spark的Shuffle配置调优1、Shuffle优化配置 -spark.shuffle.file.buffer2、Shuffle优化配置 -spark.reducer.maxSizeInFlight3、Shuffle优化配置 -spark.shuffle.io.maxRetries4、Shuffle优化配置 -spark.shuffle.io....
shuffle及Spark shuffle历史简介 shuffle,中文意译“洗牌”,是所有采用map-reduce思想的大数据计算框架的必经阶段,也是最重要的阶段。它处在map与reduce之间,又可以分为两个子阶段: shuffle write:map任务写...

shuffle阶段又可以分为Map端的shuffle和Reduce端的shuffle。 一、Map端的shuffle Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的...
Strom程序的并发机制,配置并行度(代码实现)、动态改变并行度,local or shuffle分组,分组的概念以及分组类型.pdf
找了好多有关的博客和资料,他们都是从很底层的实现过程来讲解shuffle的,对于初学者来讲并不是适合学习的材料,因为那些概念都太抽象,再加上从单机到分布式的思维模式的转换,更加增加了学习的难度。所以,我一直...
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以...

shuffle是Spark重新分发数据的机制,以便在分区之间以不同的方式分组。这通常涉及到在执行器和计算机之间复制数据,从而使shuffle成为一项复杂而昂贵的操作。 背景 为了理解shuffle过程中会发生什么,我们可以考虑...
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以...
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以...
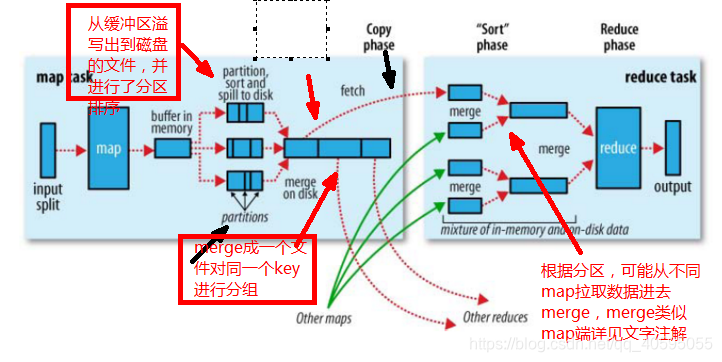
一、MapTask运行机制详解以及Map任务的并行度 整个Map阶段流程大体如上图所示。简单概述:inputFile通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map...


推荐文章
- 『Android 技能篇』优雅的转场动画之 Transition-程序员宅基地
- Webshell绕过技巧分析之-base64编码和压缩编码-程序员宅基地
- 大一计算机思维知识点,大学计算机—基于计算思维知识点详解.docx-程序员宅基地
- 关于敏捷开发的一篇访谈录-程序员宅基地
- 挑战安卓和iOS!刚刚,华为官宣鸿蒙手机版,P40搭载演示曝光!高管现场表态:我们准备好了...-程序员宅基地
- 精选了20个Python实战项目(附源码),拿走就用!-程序员宅基地
- android在线图标生成工具,图标在线生成工具Android Asset Studio的使用-程序员宅基地
- android 无限轮播的广告位_轮播广告位-程序员宅基地
- echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
- Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地