
”shuffle的主要机制“ 的搜索结果
Shuffle简介 Shuffle描述着数据从map task输出到reduce task输入的这段过程。shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的性能和...
Shuffle工作机制 Shuffle过程:数据从MapTask拷贝到ReduceTask的过程 Shuffle基本要求: (1)完整地将数据从MapTask端拷贝到ReduceTask端 (2)在拷贝过程中,应尽量减少网络资源的消耗 (3) 尽可能地减少磁盘IO对...
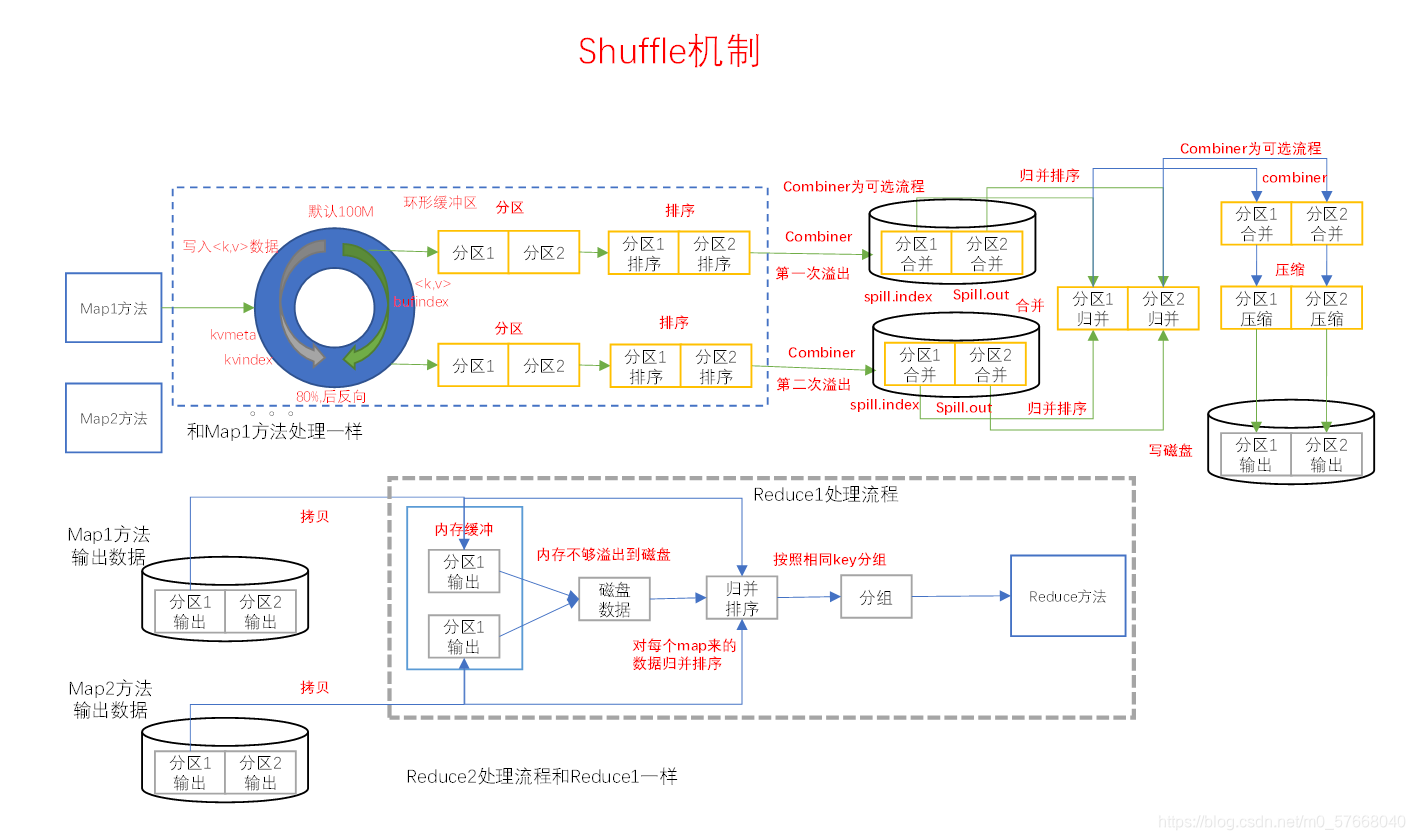
Shuffle机制 1)Map方法之后Reduce方法之前这段处理过程叫Shuffle 2)Map方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢...
2.4.1 概述 1)mapreduce中,map阶段处理的数据如何传递给...洗牌、发牌(核心机制:数据分区、排序、缓存); 3)具体来说:就是将maptask输出的处理结果数据,分发给reducetas...
一 Shuffle机制 运行在不同stage、不同节点上的task如何进行数据传递?这个数据传递过程通常被称为Shuffle机制。 该机制除了数据传递,还负进行各种类型的计算(如聚合、排序等),并且数据量一般会很大。 二 ...


Shuffle机制详解 什么是Shuffle? shuffle中文翻译为洗牌,需要shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算。 发生在map方法之后,reduce方法之前。 Shuffle一般包含两...
Spark Shuffle机制的主要接口是ShuffleManager,而Spark从2.0版本之后,其默认实现为SortShuffleManager。ShuffleManager接口提供了Shuffle过程中的各种方法,包括ShuffleReader、ShuffleWriter、ShuffleHandle等。...
Shuffle机制详解
标签: hadoop
Shuffle机制 Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图: 具体Shuffle过程详解,如下: 1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中 2)从内存缓冲区不断溢出本地磁盘文件,...
1.什么是Shuffle机制 1.1)在Hadoop中数据从Map阶段传递给Reduce阶段的过程就叫Shuffle,Shuffle机制是整个MapReduce框架中最核心的部分。 1.2)Shuffle翻译成中文的意思为:洗牌、发牌(核心机制:数据分区、排序...
1.1、概述1、MapReduce 中...2、Shuffle: 数据混洗 ——(核心机制:数据分区partitioner,排序soft,合并combiner,缓存);3、具体来说:就是将 maptask 输出的处理结果数据,分发给 reducetask,并在分发的过程中...
在Hadoop中,Shuffle机制是指在MapReduce计算框架中,将Map阶段的输出结果按照key进行排序,然后将相同key的value聚合在一起,最终输出给Reduce阶段进行处理的过程。具体来说,Shuffle过程包括三个主要的步骤: 1. ...
系统执行排序的过程(即将map输出作为输入传给reducer)称为shuffle。 shuffle阶段是从map方法输出数据以后开始到reduce方法输入数据之前结束。 分区的数量 = ReduceTask数量 = 结果文件的数量 ...
Shuffle过程指的是MapTask的map方法之后,ReduceTask的reduce方法之前的数据处理过程,Shuffle过程是MR中最关键的一个流程; Shuffle过程包括Collect阶段,Spill阶段,两次Merge阶段,Copy阶段,Merge阶段以及Sort...
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
大多数spark作业的性能主要就是消耗了shuffle过程,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优。但是也必须提醒大家的是,...
MapReduce中Shuffle机制详解——Reduce端Shuffle链接 Shuffle阶段是指从Map的输出开始,包括系统执行排序以及传送Map输出到Reduce作为输入的过程。Sort阶段是指对Map端输出的Key进行排序的过程。不同的Map可能...

说明:Spark是目前大数据中非常流行的运算框架,Spark的Shuffle机制是完成运算最重要的一环,面试时经常会被问到. 在Spark中,Shuffle分为map阶段和reduce阶段,也可称之为shuffle write和shuffle read阶段,Spark在...

我们都知道,训练网络的时候一般需要随机打乱训练样本数据,因为我们是采用min-batch SGD 方法进行优化的,随机打乱一定...而caffe读取数据时是一个batch一个batch顺序读取的,那它到底是用怎样的机制实现shuffle的...

推荐文章
- Windows系统鼠标右键菜单添加打开cmd终端_we右键进入cmd-程序员宅基地
- python汇编语言还是机器语言_深入理解计算机系统(3.1)------汇编语言和机器语言...-程序员宅基地
- android毕设各种app项目,安卓毕设,android毕设_app毕业设计-程序员宅基地
- Keil侧边工具栏(项目窗口)打开方式_keil侧边栏-程序员宅基地
- 算法学习,转载记录(持续记录)-程序员宅基地
- 局域网探测器_局域网检测-程序员宅基地
- 【C语言基础系列,阿里java面试流程_c语言java面试-程序员宅基地
- Linux技术简历项目经验示例(二)_linux简历工作经验怎么写-程序员宅基地
- 安卓手机软键盘弹出后不响应onKeyDown、onBackPressed方法解决方案-程序员宅基地
- 使用二维数组实现存储学生成绩_c#创建控制台应用程序studentscore,生成学生成绩单——二维数组的使用。-程序员宅基地