$dom=newDOMDocument;$dom->...foreach($dom->getElementsByTagName('a')as$node){echo$dom->...}上面将找到并输出字符串中所有元素的“outerHTML”。A$html要获取节点的所有文本值,请执行此操作echo...
”scrapy获取a标签的连接“ 的搜索结果
更新:您可以使用以sel.xpath('.//a[@name="summaries"]')开头的xpath。。。我在这台mac电脑上没什么问题,所以我用的是lxml,事实上,在lxml中,你可以使用getparent(),iterslibings等等。实际上,这里有一个例子...
折腾:期间,对于scrapy的response的xpath得到的Selector,如何获取其中的a中href的值好像就是定位到对应节点,extract即可?通过继续在Scrapy shell中调试,找到了获取a的href值的方式了:>>> response....
C#简单的web网页html抓取并提取指定a标签链接时间:4年前作者:庞顺龙浏览:900[站内原创,转载请注明出处]C#简单的web网页html抓取并提取指定a标签链接string url = "http://xxxxx/";for (int i = 1; i <= 1; i+...
本文实例讲述了C#基于正则表达式抓取a标签链接和innerhtml的方法。分享给大家供大家参考,具体如下://读取网页htmlstring text = File.ReadAllText(Environment.CurrentDirectory + "//test.txt", Encoding....
scrapy只获取到第二页的url,后面所有的网页链接都没输出,且写入数据库或者保存文件,只有第一页的数据。,这个时候,你直接回调 ,并且打印下一页的网址,就会发现只有一个。且数据只有第一页的。概述:要知道...
爬虫能够不断地向各个地方漫游,得益于它有识别道路的能力,这里所谓的道路就是超级连接。虽然从种子的网页出发,它就会根据下载的网页来识别下一个网页,通过这样的方式,就可以遍历整个网站,从而把所有网页分析一...
id=ff808081568e4d50015a2099b09915cf" target="_self">详情 </a> 北京地铁十六号线投资有限责任公司 北京地铁十六号线工程 区间工程 月坛南街站、阜外大街~月坛南街区间 <td>2017规延市政字0004号 ...
一 ,Scrapy-分布式 (1)什么是scrapy_redis scrapy_redis:Redis-based components for scrapy github地址:https://github.com/rmax/scrapy-redis (2)Scrapy和Scrapy-redis 有什么区别? 1.Scrapy是爬虫...

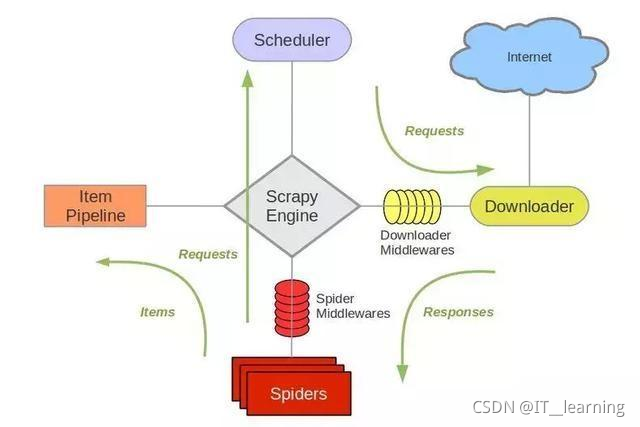
引擎 (engine):Scrapy的核心,所有模块的衔接,数据流程梳理。调度器 (scheduler):本质上这东西可以看成是一个队列,里面存放着一堆我们即将要发送的请求,可以看成是一个URL的容器。它决定了下一步要去爬取哪一个...

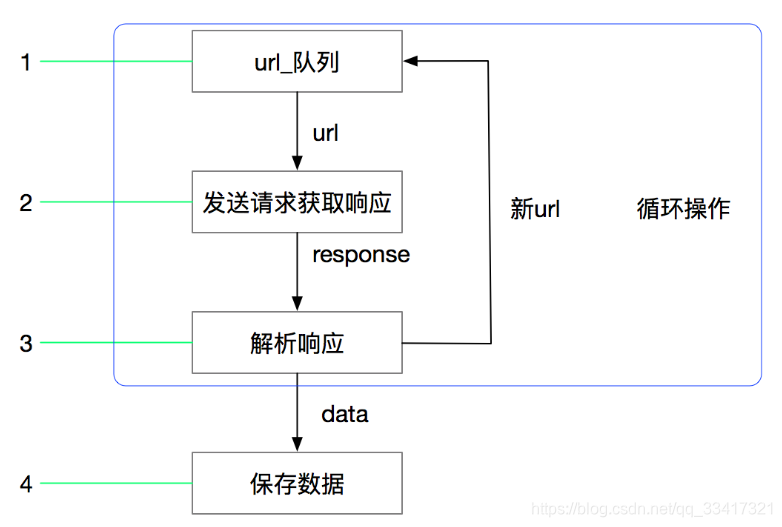
先获取初始网址,获取该网址中的所有链接,爬取所有链接
开启一个有模板的scrapy项目,在这里有scrapy经验的朋友应该都比较熟练了。进入到创建好的虚拟环境当中运行以下shell代码。 scrapy startproject [projectname] cd projectname scrapy genspider -t crawl ...
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。 Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 ...
Scrapy 是一个强大的开源网络爬虫框架,用于从网站上提取数据。它以可扩展性和灵活性为特点,被广泛应用于数据挖掘、信息处理和历史数据抓取等领域。官网链接(外)

xpath是一门在XML文档中查找指定信息的.../选择某个标签下的所有内容 text()选择标签内所包含的文本 @选择标签属性信息 //选择所有标签 [@属性=值]该标签属性满足一定条件 注意上面所有的操作,返回的结果都是Ht...
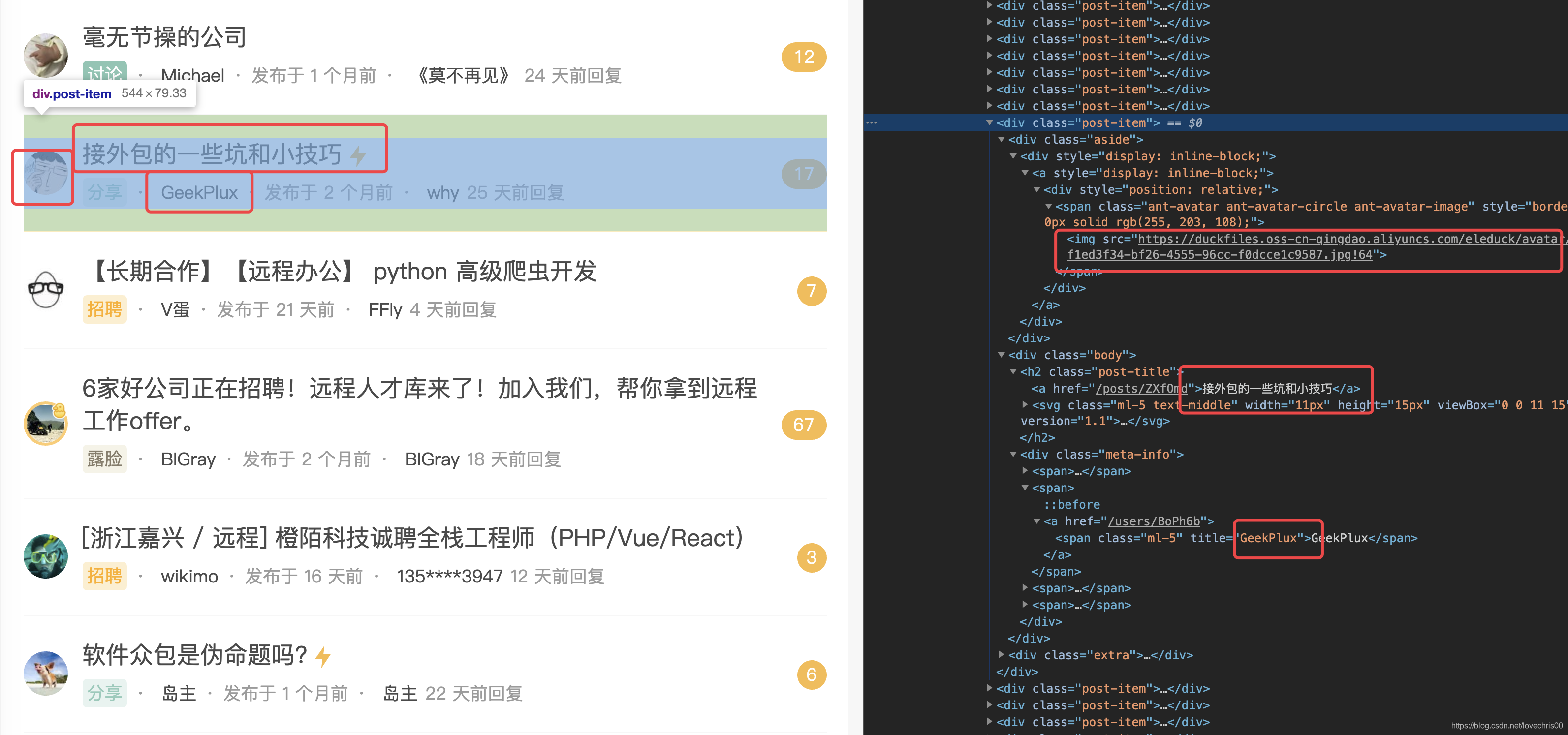
简介:通过BeautifulSoup 的 find_all方法,找出所有a标签中的href属性中包含http的内容,这就是我们要找的网页的一级链接( 这里不做深度遍历链接)并返回符合上述条件的a标签的href属性的内容,这就是我们要找的某个...
推荐文章
- linux c 串口 调用命令,Linux系统C语言串口收发-程序员宅基地
- 八:通过Infura部署到rinkeby测试网_使用infura运行测试网-程序员宅基地
- 『Android 技能篇』优雅的转场动画之 Transition-程序员宅基地
- Webshell绕过技巧分析之-base64编码和压缩编码-程序员宅基地
- 大一计算机思维知识点,大学计算机—基于计算思维知识点详解.docx-程序员宅基地
- 关于敏捷开发的一篇访谈录-程序员宅基地
- 挑战安卓和iOS!刚刚,华为官宣鸿蒙手机版,P40搭载演示曝光!高管现场表态:我们准备好了...-程序员宅基地
- 精选了20个Python实战项目(附源码),拿走就用!-程序员宅基地
- android在线图标生成工具,图标在线生成工具Android Asset Studio的使用-程序员宅基地
- android 无限轮播的广告位_轮播广告位-程序员宅基地