学习了Scrapy,那就先爬点图片看看。 首先明确目标,要爬取什么? 我们爬取“孔夫子旧书网”所有书籍的图片及信息 上面标注的就是我们要爬取的信息,确定了目标,就可以编写items.py import scrapy ...
”scrapy爬取图片“ 的搜索结果
其实关于scrapy的很多用法都没有使用过,需要多多巩固和学习 1.首先新建scrapy项目 scrapy startproject 项目名称 ...3.编写Item,确定你要爬取的目标 import scrapy class CosplayItem(scrapy.Item): """ 标题 co
用scrapy爬取下载某图片网站的全部图片。代码中已经去除了具体网站的信息,代码只供学习用。
替换your_project_name为您的项目名称,YourImagesPipeline为自定义的Item Pipeline(用于保存图片),path_to_download_...将"your_spider_name"替换为您喜欢的名称,"example.com"替换为您要爬取图片的网站域名。
使用scrapy爬取图片,采用管道方法进行下载。
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于...
我们知道使用requests与selenium下载图片都是非常简单的,那么scrapy是怎么下载图片的呢?1.保存图片需要导入ImagesPipeline类2.需要配置settings.py 开启管道 并设置保存路径。
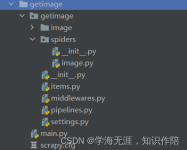
这里我们以美食杰为例,爬取它的图片,作为演示,这里只爬取一页。美食杰网址 1 首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject meishi, 接着根据提示cd meishi, 再cd meishi, , 下来写 ...
python爬虫使用Scrapy 爬取当当网图片信息
使用Scrapy爬取当当网的图片信息

存中…(img-kAHOCEfr-1713757074370)]
可以用于毕业设计(项目源码+项目说明)目前在window10/11测试环境一切正常,用于演示的图片和部署教程说明都在压缩包里
命令:scrapy genspiders 爬虫文件名 www.xxx.com(允许爬取的域名) 3、进行setting文件的配置,将ROBOTSTXT协议设置为False,并设置日志输出权限已经UA伪装 4、开始编写spiders下爬虫文件的内容 import scrapy #...
一、使用爬虫框架scrapy爬取图片 上次我们爬取过文本、文字、的一些普通数据,现在我们就可以学习爬图片了,一些段友就可以爬自己想要的图片了,哈哈哈哈。 首先我们先大概总结一下scrapy爬虫的原理流程,先看图:...
可以用于毕业设计(项目源码+项目说明)目前在window10/11测试环境一切正常,用于演示的图片和部署教程说明都在压缩包里
Item 是保存爬取数据的容器,使用的方法和字典差不多。我们计划提取的信息包括:area(区域)、sight(景点)、level(等级)、price(价格),在 items.py 定义信息,源码如下:pass。
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片。 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存储起来。也是就是我们项目...
**[外链图片转存中…(img-2yW8lotM-1713681057647)][外链图片转存中…(img-v1RGrPhA-1713681057648)][外链图片转存中…(img-rn5aAFaQ-1713681057648)][外链图片转存中…(img-COGu4g6f-1713681057649)]
启动框架后会自动调用parse方法。response对象中常用的属性。
使用scrapy里自带的Image功能下载,下面贴代码,解释在代码的注释里。 items.py 1 import scrapy 2 3 class ImageItem(scrapy.Item): 4 #注意这里的item是ImageItem5 image_urls = scrapy.Field() 6 ...
下面是使用Scrapy爬取图片的步骤: 1. 首先,安装Scrapy库,可以使用pip命令进行安装:pip install scrapy 2. 创建一个新的Scrapy项目,可以使用命令:scrapy startproject project_name 3. 进入项目目录,创建一...
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实现下效果 ...
scrapy 爬取图片 保存失败
标签: 其他
如题 文件创建了 但是图片没有保存
这次爬虫使用scrapy,所以用到的工具必然是python3.7,scrapy,pycharm这些东西, 目标网站:http://pic.netbian.com 彼岸图网,个人非常喜欢的图片网站,完全公开免费,几乎没有防爬措施,对于爬虫新手来说是费非常...
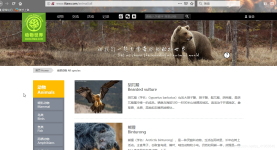
文章目录Scrapy爬取图片并重命名总结项目分析:开始项目:启动项目:总结 Scrapy爬取图片并重命名总结 项目分析: 1、现在很多网页都是动态加载资源,数据都不在静态html模板上,都是通过重定向从json文件中加载而来...
推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地