有时需要根据项目的实际需求向...scrapy crawl myspider -a category=electronics 然后在spider里这样写: import scrapy class MySpider(scrapy.Spider): name = 'myspider' def __init__(self, category=None,
”scrapy“ 的搜索结果
创建项目 : scrapy startproject tencent 创建爬虫:scrapy genspider tc careers.tencent.com tc.py # -*- coding: utf-8 -*- import scrapy import json class TcSpider(scrapy.Spider): name = 'tc' allowed_...
今天小编就为大家分享一篇关于使用Scrapy爬取动态数据的文章,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
毕业设计+Python基于Scrapy+Redis分布式爬虫设计+源码案例+Python + Scrapy + redis 毕业设计+Python基于Scrapy+Redis分布式爬虫设计+源码案例+Python + Scrapy + redis 毕业设计+Python基于Scrapy+Redis分布式爬虫...
Scrapy框架爬虫小程序Demo,安装好环境后可直接运行
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
基于python scrapy框架抓取豆瓣影视资料
Python_Scrapy_Distributed_Crawler Python基于Scrapy-Redis分布式爬虫设计毕业源码案例设计 开发环境:Python + Scrapy框架 + redis数据库 程序开发工具: PyCharm 程序采用 python 开发的 Scrapy 框架来开发,...
基于基于Python基于Scrapy+Gerapy+NLP+Django搭建的新闻整套系统框架结构,都是使用现成的框架及算法等内容进行组合构建的整套系统。 项目展示网址 二、 其中主要流程包括 Scrapy爬虫框架、整体框架设置 Gerapy...
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
基于Scrapy的考研院校报名数据分析系统论文
基于python和scrapy的电影数据爬虫,爬取电影评分以及简介名称数据,将其储存在csv当中,适用于课程设计、爬虫作业。
python爬虫学习笔记 4.2 (Scrapy入门案例(创建项目)) 入门案例 学习目标 创建一个Scrapy项目 定义提取的结构化数据(Item) 编写爬取网站的 Spider 并提取出结构化数据(Item) 编写 Item Pipelines 来存储提取到的...
运用scrapy框架编写腾讯招聘信息,招聘位置,招聘地区,招聘链接,人数,等等信息,完整程序,直接运行即可完整打印招聘信息.
scrapy基于python,scrapy,redis实现主从式master-slave爬虫
主要介绍了Docker 部署Scrapy的详解,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
Scrapy+Python 抓取花瓣网不同主题的图片,仅用于个人练习,不作于商业用途

Scrapy网站爬虫源码
Scrapy-Redis-BloomFilter 这是一个支持Scrapy-Redis的BloomFilter的软件包。 安装 您可以使用pip轻松安装此软件包: pip install scrapy-redis-bloomfilter 依赖关系: Scrapy-Redis> = 0.6.8 用法 将此设置...
用scrapy框架爬取拉钩职位信息,保存为csv文件,并上传到mysql数据库当中。此案例仅用于学习爬虫技术,不作商业用途。若侵权,请联系删除。
本博客介绍使用Scrapy爬取博客数据(标题,时间,链接,内容简介)。首先简要介绍Scrapy使用,scrapy安装自行百度安装。 创建爬虫项目 安装好scrapy之后,首先新建项目文件:scrapy startproject csdnSpider 创建...
该案例相对完整,欢饮下载交流。有疑问,可以留言,一起交流探讨并发掘爬虫世界的美!该案例结构清晰,注释明了,可以使大家很好地理解scrapy爬虫框架。
scrapy_multiple_spiders Websit中不同渠道的结构相似,有时我们想重用源代码,而不是每个渠道都创建项目。 这是一个教程,如何在Scrapy项目中使用多个蜘蛛。
简书简介小甲鱼B站教学视频
刮的 修补 Scrapy Python 库以进行网页抓取 有关详细信息,请参阅 nyvendors/readme
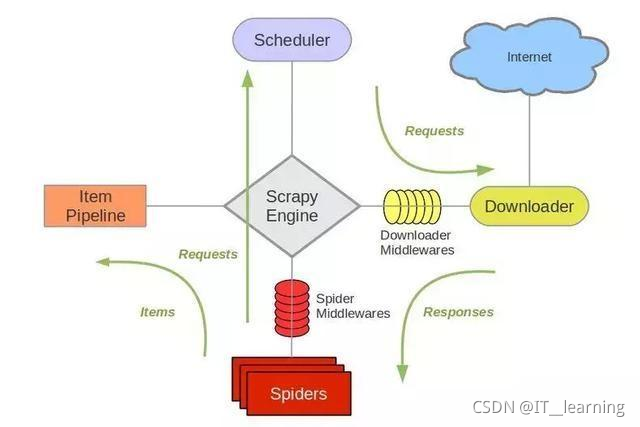
下面小编就为大家带来一篇python安装Scrapy图文教程。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
本文实例讲述了Scrapy框架实现的登录网站操作。分享给大家供大家参考,具体如下: 一、使用cookies登录网站 import scrapy class LoginSpider(scrapy.Spider): name = 'login' allowed_domains = ['xxx.com'] ...

推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地