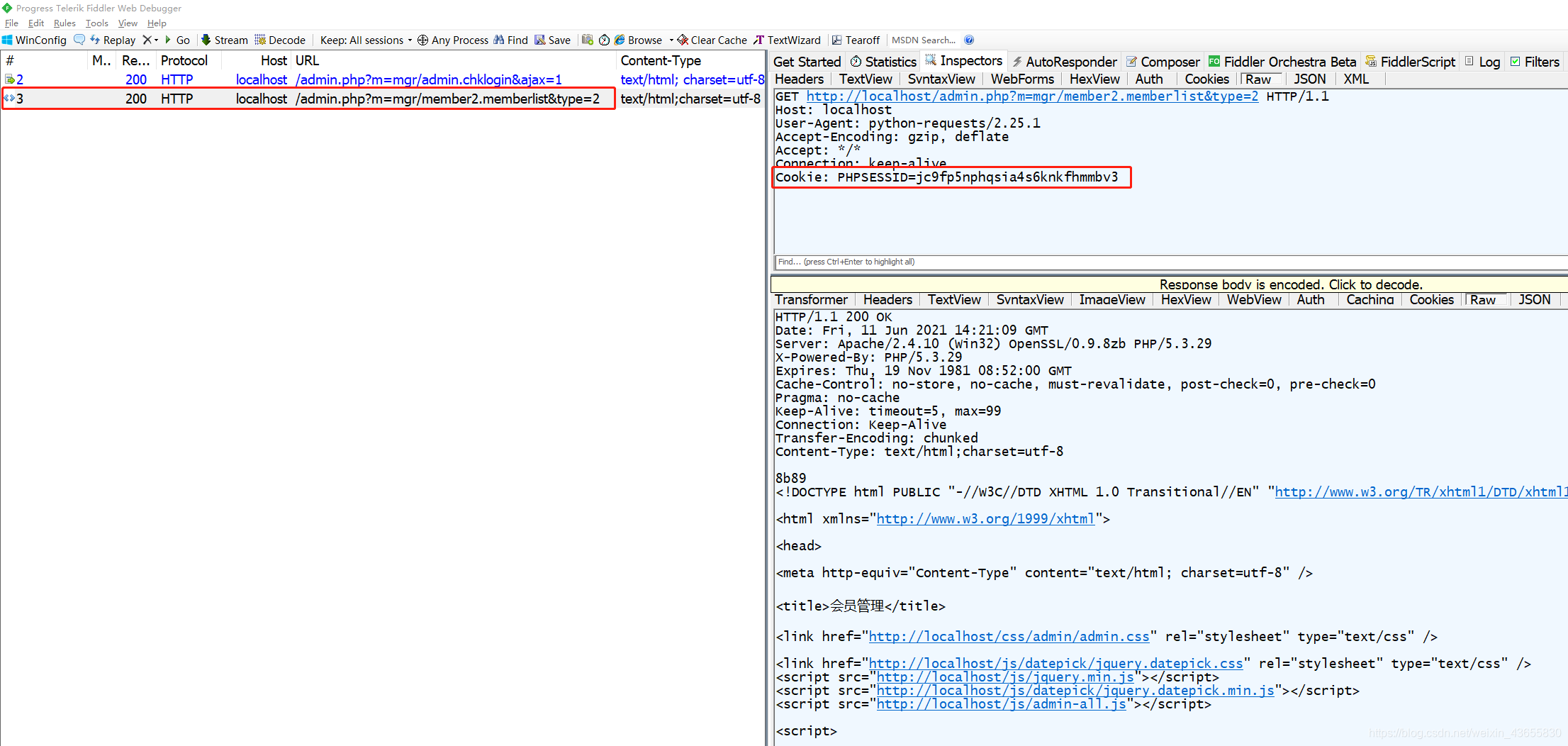
”python获取header头内容“ 的搜索结果


import requests from bs4 import BeautifulSoup import json def download_all_htmls(): """ 下载所有列表页面的HTML,用于后续的分析 """ htmls = [] for idx in range(34): url = f...
request.META.get("xxx ") 用于获取header的信息 注意的是header key必须增加前缀HTTP,同时大写,例如你的key为username,那么应该写成:request.META.get("HTTP_USERNAME") 另外就是当你的header key中带有中...
一、添加邮件头,抄送等信息1.mail["From"]表示发送者信息,包括姓名和邮件2.mail["To"]表示接收者信息,包括姓名和邮件地址3.mail["Subject"]表示摘要或者主题信息from email.mime.text importMIMETextfrom email....

本文介绍了如何使用Python编写一个爬虫程序,通过Selenium和Pandas实现了大乐透开奖信息的自动化获取和存储。通过这个实践项目,我们学习了如何处理网页加载和元素定位的问题,并利用Pandas对数据进行处理和分析。...
request请求头信息的键会加上HTTP_转换成大写存到request.META中 因此你只需要 content_range = request.META['... 这样就可以获取到Content-Range的信息。 ...A standard Python dictionary containing all a
pycharm可以自动生成python的文件头模板,但是vscode目前还不可以(不支持python,c的似乎有插件支持了)。琢磨了一下,可以通过用户代码片段来实现。 1. 什么是用户代码片段 参考文章说的很详细:跟我一起在...
我正在尝试提取XML文件中特定标签的内容.样本XML:crashCrashidCrash InstanceINTkeyaccident_keyCase IdentifierstringCHAR(9)accident_yearCrash YeardimINTvehicleVehicleidVehicle InstanceINTcrash_idCrash ...
首先执行pythonhttp_service.py脚本,然后在执行pythonhttp_client.py脚本。基于flask框架的http服务器,经常需要捕获客户端的请求头中的字段数据,来做校验。
获取数据内容。pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。import pandas as pd# 读取数据df = pd.read_csv("../data/data.csv")print(df)为了解决这个问题,我们添加...

老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 树型部件窗口可以有一个标题头,其中包含部件中每个列的节(即标题)。QTreeWidget的标题属性包括两部分,一部分是标题项,一部分...
python 163邮箱读取
标签: python
参考:https://www.cnblogs.com/testlearn/p/14548396.html
使用这个机制,你可以在消息中添加一些与数据内容无关的附加信息,如消息的来源、类型、版本、生产时间、过期时间、分区数、用户 ID 等等。Kafka header 是由一个或多个键值对组成的列表,每个键值对都称为 header。...
预备知识点 compile 函数 compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。 语法格式为: ...re.compile(pattern[, flags]).compile(pattern[, ...
1、GET请求 # requests GET请求 import requests # 第一种 url = 'https://www.sogou.com/web?query=python' rep = requests.get(url) ...params = {'query': 'python'} rep1 = requests.get(url
在上一篇文章中我们知道,socket.accept()接受的数据是请求头,请求头格式是这样的: POST /login HTTP/1.1 Host: 127.0.0.1:1207 User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 ...
利用python获取网页内容可以说是非常的方便的,本人是小白,在学习过程中,记录一点点心得。获取内容以知乎为例,只供学习使用哦。1、导入库文件import sys #系统库 import urllib2 #常用的URL库 import re #正则库2...
01 Tushare简介 Tushare是一个金融大数据开放社区,它免费提供各类金融数据和区块链数据 , 助力智能投资与创新型投资。在Tushare 旧版 运行了3年后,Tushare Pro终于要跟大家见面了。Pro版数据更稳定质量更好了,但...
获取响应内容 如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型 解析内容 得到的内容可能是HTML,可以用正则表达式...
里面包含了所有重定向后的内容.(一个列表) 如果需要查看location 可以自行查看是第几个的location 直接拿出来就行了 例子 url = ‘text.com’ response = requests.get(url, headers=headers) history_...
文件下载
curl:命令行下的网站访问和验证工具常用参数如下:-c,–cookie-jar:将cookie写入到文件-b,–cookie:从文件中读取cookie-C,–continue-at:断点续传-d,–data:httppost方式传送数据-D,–dump-header:把...
grpc-python08–headers与压缩与传输最大值

推荐文章
- Springboot——mybatis配置_springboot配置mybatis-程序员宅基地
- 计算机网络体系结构-程序员宅基地
- 韶音、南卡、Oladance开放式耳机值得买吗?多维度测评实力最强品牌-程序员宅基地
- bert简介_tensorflow 2.0+ 基于BERT的多标签文本分类-程序员宅基地
- jupyter notebook常用快捷键和语法_jupyter notebook怎么换行-程序员宅基地
- 教材编者,请多点儿“钻研”精神-程序员宅基地
- MySQL如何更改数据库名字_mysql update数据库名称-程序员宅基地
- windows上最好用的文件管理软件 Directory Opus_directory ops-程序员宅基地
- AWT图形界面设计编程——1.AWT容器_awt容器定义-程序员宅基地
- 一文看懂mybatis底层运行原理解析-程序员宅基地