今天为大家推荐的是“详解pandas中的Map、Apply、Groupby函数”。如果本期内容对您有所帮助,记得及时关注。1.Map(1)数据集(2)假设您想要添加一列,指出每种食物来自哪种动物。让我们写下每一种不同的...
”python聚合函数详解“ 的搜索结果
不再单独写了,引用几个小伙伴的内容吧,看完基本就掌握了。 逻辑和表达都很清楚,基本把aggregate的功能都讲到了 ...例子比较多,print了查询结果 ...———————————————— 版权声明:本文为CSDN博主「zw...

我们将从基本的语法和概念开始,逐步深入到高级主题,帮助您建立坚实的Python编程基础,并掌握一系列实用技能。不管您是想成为一名全职的Python开发者,还是在其他领域中应用Python,本专栏都将成为您的最佳学习伙伴...
一、seaborn简介seaborn是Python中基于matplotlib的具有更多可视化功能和更优美绘图风格的绘图模块,当我们想要探索单个或一对数据分布上的特征时,可以使用到seaborn中内置的若干函数对数据的分布进行多种多样的...
Python之数据聚合与分组运算1. 关系型数据库方便对数据进行连接、过滤、转换和聚合。2. Hadley Wickham创建了用于表示分组运算术语“split-apply-combine”(拆分-应用-合并)。3. GroupBy的size方法,它可以返回一...
pandas是一个Python包,提供快速,灵活和富有表现力的数据结构,旨在既简单又直观的处理“关系”或“标记”数据。它旨在成为在Python中进行实际,真实世界数据分析的基本高级构建块。 pandas是一个开源的,BSD许可的...

3.0.0 版本一共包含了 3400 多个补丁,是开源社区有史以来贡献力度较大的一次,新版本加入了 Python 和 SQL 的高级功能,提升了探索和生产应用方面的易用性。今年,Spark 也迎来了开源 10 周年,这 10 年里 Spark ...
本部分定义了特定于物种停滞例程的参数,由DefaultStagnation类实现,包括以下参数:species_fitness_func:用于计算物种适应度(即计算属于特定物种的所有生物的适应度值)的函数的名称。允许的值为max,min和mean...
使用python时,常常会涉及到库的调用,这就需要掌握模块的基本知识。本文分为如下几个部分 概念说明 模块的简单调用 包的导入 特殊的__init__.py文件 导入模块的搜索路径 __all__ 绝对引用与相对引用 import运行...
每个模型都是django.db.models.Model的一个Python 子类。 模型的每个属性都表示为数据库中的一个字段。 Django 提供一套自动生成的用于数据库访问的API。 这极大的减轻了开发人员的工作量 ...
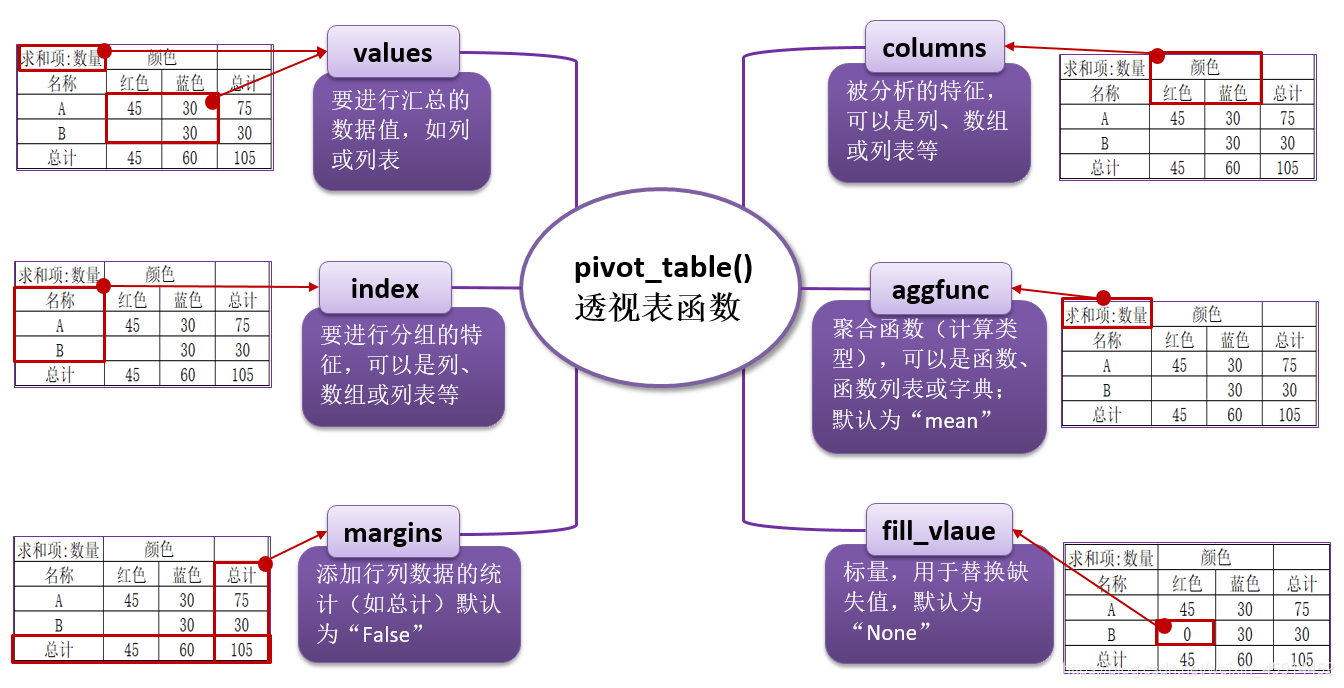
介绍也许大多数人都有在Excel中使用数据透视表的经历...所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析。如果你对这个概念不熟悉,wikipedia上对它做了详细的解释。顺便说一下,...
博文函数顺序以及代码部分参考Spark Python API函数学习:pyspark API系列,并在此基础上结合PySpark官方文档以及参考各位博主的优秀文章对各个函数进行了解释。代码全部手撸过,可以运行。 实验环境可以按照在...

然后,可以计算出每个节假日的平均需求量,将其与普通日的需求量进行比较,从而分析节假日对产品需求量的影响。例如,如果线上订单需求量的中位数明显高于线下订单需求量的中位数,那么我们可以判断线上销售渠道对...
es脚本编程使用详解
本文简单介绍python中的zip()方法的使用,并相应介绍与之相关联的itertools模块中的zip_longest()。简而言之,Python中的zip()方法是用于提高并行迭代(parallel iteration)的效率的。

切片取一个list或tuple的部分元素是非常常见的操作。比如,一个listL=[0,1,2,3,4,5,6,7,8,9]取前3个元素,应该怎么做笨方法,一个个列出来>>> [L[0],L[1],L[2]][0, 1, 2]假如需要列出N个但是N很大循环方法>>> r=[]>>...
【Python数据挖掘课程】六.Numpy、Pandas和Matplotlib包基础知识前面几篇文章采用的案例的方法进行介绍的,这篇文章主要介绍Python常用的扩展包,同时结合数据挖掘相关知识介绍该包具体的用法,主要介绍Numpy、...
映射就是指给一组数据中的每一个元素绑定一个固定的数据。 给Series中的一组数据提供另外一种表现方式,或者说给其绑定一组指定的标签或字符串 透视表是一种可以对数据动态排布并且分类汇总的表格格式。...
PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼容python其他库,这就给了PySpark极大的使用空间,能够结合...
Pandas系列-优雅的applymap和map
在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像(性别、年龄)进行细分,...
本文实例讲述了Python Web框架之Django框架Form组件用法。分享给大家供大家参考,具体如下: ** Form简介 ** 在HTTP中,表单(form标签),是用来提交数据的,其action属性说明了其传输数据的方法:如何传、如何...
在任何编程语言中,函数的...在Python中做函数设计,主要考虑到函数大小、聚合性、耦合性三个方面,这三者应该归结于规划与设计的范畴。高内聚、低耦合则是任何语言函数设计的总体原则。1.如何将任务分解成更有针对性...

qcut函数则是根据数据本身的数量来对数据进行分割:比如要把数据分为四份,则四段分别是数据的0-25%,25%-50%,50%-75%,75%-100%,每个间隔段里的元素个数都是相同的。cut函数是按照数据的值进行分割:例子:按照...
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地