无
”python爬虫库的常见用法“ 的搜索结果

本实战案例涉及使用Python编写一个爬虫程序,用于批量爬取B站(哔哩哔哩)上的小视频。这个案例将使用到requests库来发送HTTP请求,以及BeautifulSoup库来解析网页内容。 适用人群 Python开发者:希望提高网络爬虫...
Requests 是一个为人类设计的简单而优雅的 HTTP 库。requests 库是一个原生的 HTTP 库,比 urllib3 库更为容易使用。requests 库发送原生的 HTTP 1.1 请求,无需手动为 URL 添加查询串,...requests 库包含的特性如下。
这些示例代码只是为了帮助你快速了解每个库的基本用法。在实际应用中,你需要根据具体的爬取需求和网站结构,使用官方文档和其他资源,进一步了解和掌握每个库的更多功能和高级用法。
文章目录一、导入re库二、使用正则表达式步骤三、正则表达式中常见的基本符号四、常见的正则表达式举例五、re库的核心函数六、匹配对象的方法(提取)七、re模块的属性(flag)7.1 re模块的常用属性有以下几个:八、...
Urllib库是Python中的一个功能强大、用于操作URL,并在做爬虫的时候经常要...下面这篇文章主要给大家介绍了关于Python2/3中urllib库的一些常见用法的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下。

在现代的Web开发中,与服务器进行...Python的Requests库是一个简单而强大的第三方库,它提供了简洁的API,使得发送HTTP请求变得非常容易。本教程将介绍如何使用Python Requests库发送各种类型的HTTP请求,并处理响应。
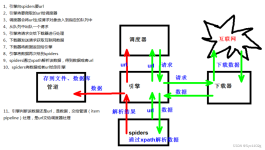


python爬虫总结
标签: python爬虫
python爬取网络资源整理,总计了一些常见用法及错误方式解析
1,Requests是一个Python中的HTTP库,用于向Web服务器发送HTTP请求并获取响应。Requests库的使用方式与urllib库类似,但更加简单和灵活。Requests库支持HTTPS请求,并且可以自动处理cookies和会话,使得操作更加方便...
Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解,因此可以快速地学习并掌握 BS4 的...

常见的路径表达式有以下几种形式:表达式意义表示从根节点开始选择。//表示在整个文档中选择节点。。(点)表示当前节点。。。(两个点)表示当前节点的父节点。nodeName表示选择指定名称的节点。谓语。

前言python爬虫系列文章的第3篇介绍了网络请求库神器 Requests ,请求把数据返回来之后就要提取目标数据,不同的网站返回的内容通常有多种不同的格式,一种是 json 格式,这类数据对开发者来说最友好。另一种 XML ...
简介:Requests是一个优雅而简单的Python HTTP库,与之前的urllibPython的标准库相比,Requests的使用方式非常的简单、直观、人性化,Requests的官方文档非常的完善详尽,文档地址查看:中文官方文档&...
广告关闭腾讯云11.11云上盛惠 ,精选热门产品助力上云,云服务器首年88元起,买的越多返的越多,最高返5000元!location.href = localstorage.getitem(url) || :toast(e.msg || 登录出错) }) }) : toast(e.msg) }) }...
文章详细讲解了利用requests库实现文件上传、cookies处理、状态码处理、异常处理等功能,既有理论又有代码和配图,快来看看吧!
课程简介:从零起步 系统入门Python爬虫工程师大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造,课程有四个阶段,爬虫0基础入门->项目实战->爬虫难点突破->scrapy框架快速抓取,带你系统...
Python爬虫面试题及答案


接下来记录下Python爬虫定时任务的几种解决方法。1.方法一、while True首先最容易的是while true死循环挂起,不废话,直接上代码:importosimporttimeimportsysfromdatetimeimportdatetime,timedeltadefO...
Python爬虫是一种使用Python编程语言开发的自动化网页抓取工具。它们主要用于从互联网上获取数据,通常用于收集公开信息,如新闻文章、社交媒体帖子、价格信息等。
原博文2019-07-09 09:46 −有些数据是没有专门的数据集的,为了找到神经网络训练的数据,自然而然的想到了用爬虫的方法开始采集数据。一开始采用了网上的一个动态爬虫的代码,发现爬取的图片大多是重复的,有效图片...
推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地