Python 接口并发测试详解
标签: 压力测试
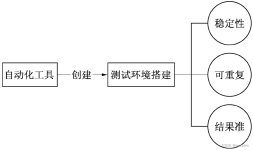
标签: 压力测试
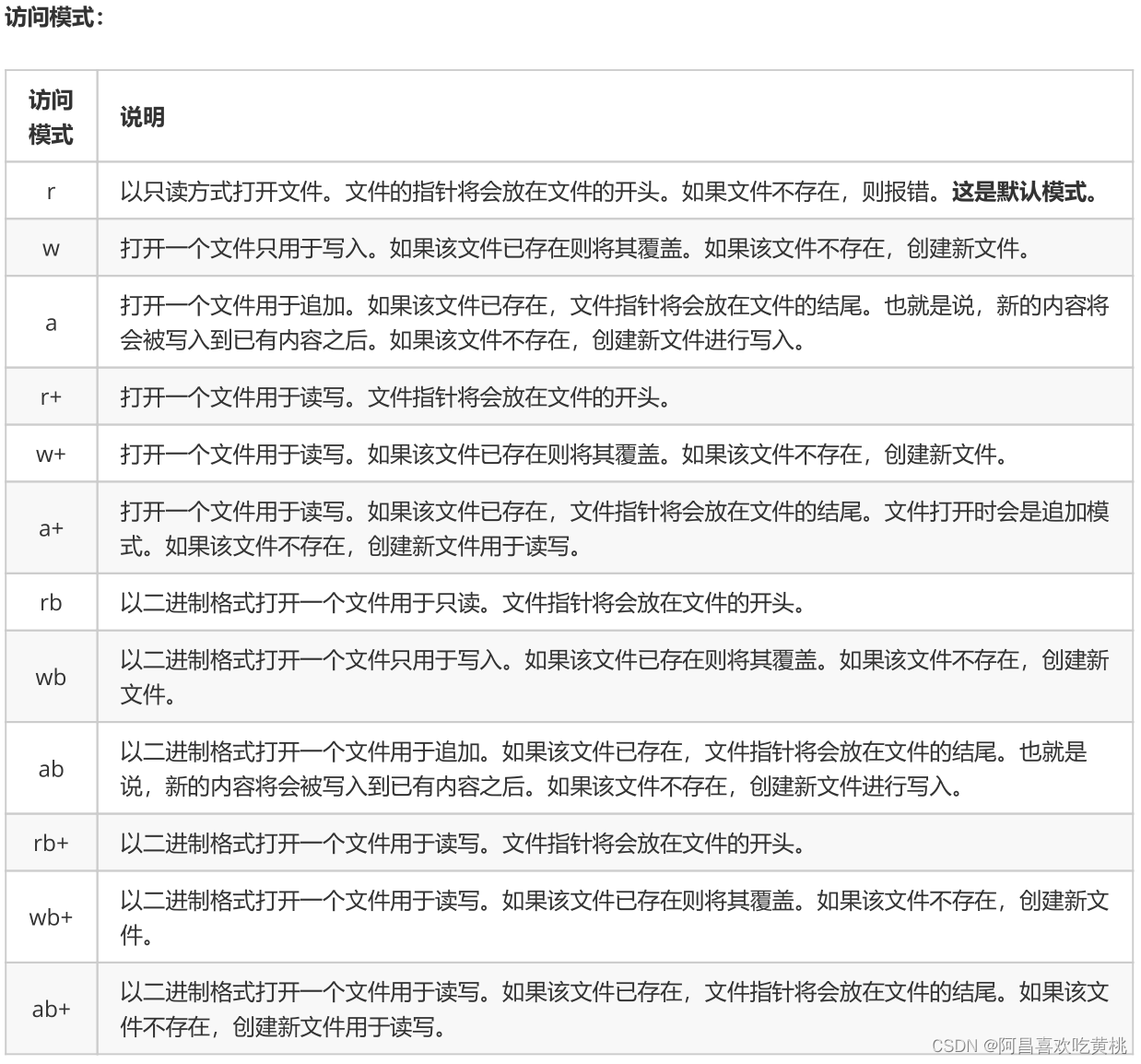
JSONPath是一种用于从JSON数据中提取或查询数据的表达式语言。它最初由史蒂芬·摩根(Stephen Morgan)在2007年创建,并在2014年成为了IETF(互联网工程任务组)的标准。JSONPath 是一种查询语言用于在 JSON 数据中...

首先要解释一下 Headless Chrome,通俗的讲就是运行一个没有GUI的Chrome,在 Headless Chrome 出现以前有 PhantomJS ,但是自从 Headless Chrome 出现之后 PhantomJS 活跃度下降,所以维护者就宣布 了停止继续开发。...

BeautifulSoup的使用我们学习了正则表达式的相关用法,但是一旦正则写的有问题,可能得到的就不是我们想要的结果了,而且对于一个网页来说,都有一定的特殊的结构和层级关系,而且很多标签都有id或class来对作区分,...
在线社交网站为人们提供了一...通过抓取并分析在线社交网站的数据,研究者可以迅速地把握人类社交网络行为背后所隐藏的规律、机制乃至一般性的法则。然而在线社交网络数据的获取方法有别于线下社会数据的获取(如普...
答案是一共有三种: 1正则表达式解析 2Xpath解析 3BeautifulSoup 一,正则表达式解析 在爬虫中,下面两种方式用的多一些~ 大致用法: pattern = re.compile('<dd>.*?board-index.*?>...rel
|- 已开同步更新群A673006 - 文件夹|- 62第三十七回 方法多态.mp4 - 43.30 MB|- 61第三十六回 pygame.mp4 - 46.60 MB|- 60第三十五回 面向对象.mp4 - 44.20 MB|- 59第三十四回 构造方法统一属性定义,封装对象不惧...


有的错误是程序编写有问题造成的,比如本来应该输出整数结果输出了字符串,这种错误我们通常称之为bug,bug是必须修复的。有的错误是用户输入造成的,比如让用户输入email地址,结果得到一个空字符串,这种错误可以...
介绍.png; a3 a* k# G% s' |" k% y: u' e& x' l5 N笔记及课后习题.rar+ F2 ~6 ... M) J* r01第零回(免费预览)莫叹琐事催白发,且学Python省年华.mp4. X. o8 |7 m0 _, Z6 u/ w& l+ k1 g& Q+ j& F02第...

01第零回:莫叹琐事催白发,且学Python省年华.mp402第一回:梧桐长成鸾凤至,环境搭好代码来.mp403第二回:算术符号遵循惯例,版本差异务必当心.mp404第三回:单条语句独占单行代码,多种函数分属多个模块.mp405第四...
大数据和云计算是两个不同但密切相关的概念。大数据是指大量非结构化或结构化数据集合,无法通过传统的数据处理方式进行管理和分析。大数据的特点包括数据量大、数据类型多样、数据速度快、数据价值高等。...
原博文2017-06-10 13:47 −今天做爬虫时。发现结果中好多多余的空格。然后有强迫症的我当然不会放过...相关推荐2019-12-25 10:36 −这一次呢,让我们来试一下“CSDN热门文章的抓取”。 话不多说,让我们直接进入[CSN...
标签: python
Python网络爬虫—给????爪巴????1.网络爬虫的安全性2.网络爬虫的工作原理3.requests库1.requests库的常用函数2.request操作步骤3.response返回响应4.beautifulsoup4库1.常用的解析技术2.beautifulsoup4的操作步骤 ...
前面讲解的爬虫案例都是单级页面数据抓取,但有些时候,只抓取一个单级页面是无法完成数据提取的。本节讲解如何使用爬虫抓取多级页面的数据。在爬虫的过程中,多级页面抓取是经常遇见的。下面以抓取二级页面为例,对...
标签: 1024程序员节
Python 模块使用
1、Beautiful Soup就是Python的一个HTML或XML的解析库,它借助网页的结构和属性等特性来解析网页。 2、有了它,我们不用再去写一些复杂的正则表达式,只需要简单的几条语句,就可以完成网页中某个元素的提取。 3、...
Web请求流程 常⻅的⻚⾯渲染过程: 1.服务器渲染 这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候, 服务器直接把数据全部写⼊到html中, 我们浏览器就能直接拿到...这种就稍显麻烦了....# 安装r...

HTTP(Hyper超文本传输协议,是应用层协议,是一种客户端和服务器之间的请求-响应协议,用于从万维网服务器传输超文本到本地浏览器的传送协议。1、写爬虫首先要锁定你所要爬取的数据;2、其次要对比数据之间的差别...
▶“全民一玩Python”系列由杨洋博士精心制作,面向所有希望学习Python编程、进而能够在学习和工作中编写办公自动化、网页信息提取、数据分析处理、人工智能应用、娱乐游戏应用等实用程序的各行业人士。▶与杨洋博士...
全民一玩Python系列由杨洋博士精心制作,面向所有希望学习Python编程、进而能够在学习和工作中编写办公自动化、网页信息提取、数据分析处理、人工智能应用、娱乐游戏应用等实用程序的各行业人士。制作精细、自带吐槽...

项目准备Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。使用之前有一个类似django的创建项目以及目录结构的过程。Scrapy 安装使用pip安装(windows会有问题):pip3 install scrapy装不上主要是...