
”python古诗代码案例“ 的搜索结果
文章目录一、通用爬虫二、数据解析2.1 正则表达式2.2 bs42.3 一、通用爬虫 二、数据解析 步骤: 定位标签 获取标签内的属性值 2.1 正则表达式 通过正则表达式匹配需要抓取的链接 爬30页糗事百科的video图片: ...

使用Flask写的体育网站 包括(注册 论坛 文章评论 组建战队 后台管理)等功能 示例地址文中有写 萌新 请多指教
全书包含近200个案例和上千段代码,涉及Python基本语法和数据类型,以及GUI、网络应用、数据库、密码学、科学计算与可视化、大数据、图形图像处理等多个领域的开发,书中一些代码进行简单拼凑就可以满足实际工作中...


tensorflow自然语言处理(自动生成古诗) 在我上一篇博客当中,已经写了CNN验证码识别,由此可以看出神经网络的强大之处,所以这篇博客主要是来讲解一下RNN中的LSTM网络处理自然语言,输入一个字就自动生成一篇优美的...

零基础小白三周21天搞定Python分布爬虫课程全套——更多资源,课程更新在 多智时代 duozhishidai.com多智时代资源,简介:零基础小白三周21天搞定Python分布爬虫课程全套适用人群1、有Python基础,想学习爬虫的。...
Python Web开发记录 Day7:Django(Web框架) part 1
python(列表,字典,元组,集合) 列表——创建、增、删、改、差、效率 字典——创建、增、删、改、查 元组——创建、删、查 集合——创建、增、删、(并、交、差、反差、子、超)集 python文件操作 文件...
价值699元知了课堂零基础学Python 21天搞定Python分布爬虫课程目录├─章节1-爬虫前奏(官网免费)│ 001.爬虫前奏_什么是网络爬虫.mp4│ 002.爬虫前奏_HTTP协议介绍.mp4│ 003.爬虫前奏_抓包工具的使用网络请求.mp4│...
学习主题:Python爬虫和数据可视化 学习内容: (1)Python语言的基础知识 (2)网络爬虫的技术实现 (3)数据可视化的技术应用(框架、组件等) 学习目标: 了解网络爬虫和数据可视化的技术原理与流程 Python基础知识 认识...
Scrapy入门:爬取古诗文
标签: python
从入门到放弃,,,太难了吧
本文章是我跟着尚硅谷爬虫教学视频一边学一边做的学习笔记,仅供学习交流~
http://cn.python‐requests.org/zh_CN/latest/ 快速上手 http://cn.python‐requests.org/zh_CN/latest/user/quickstart.html 2.安装 pip install requests 3.response的属性以及类型 类型 :models.Response ...
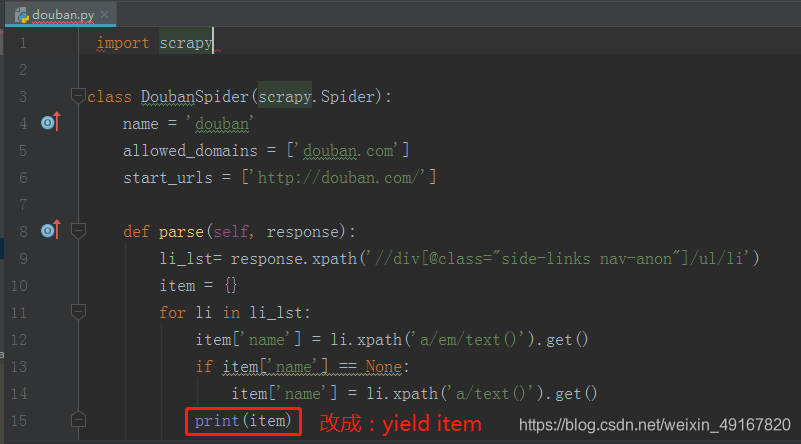
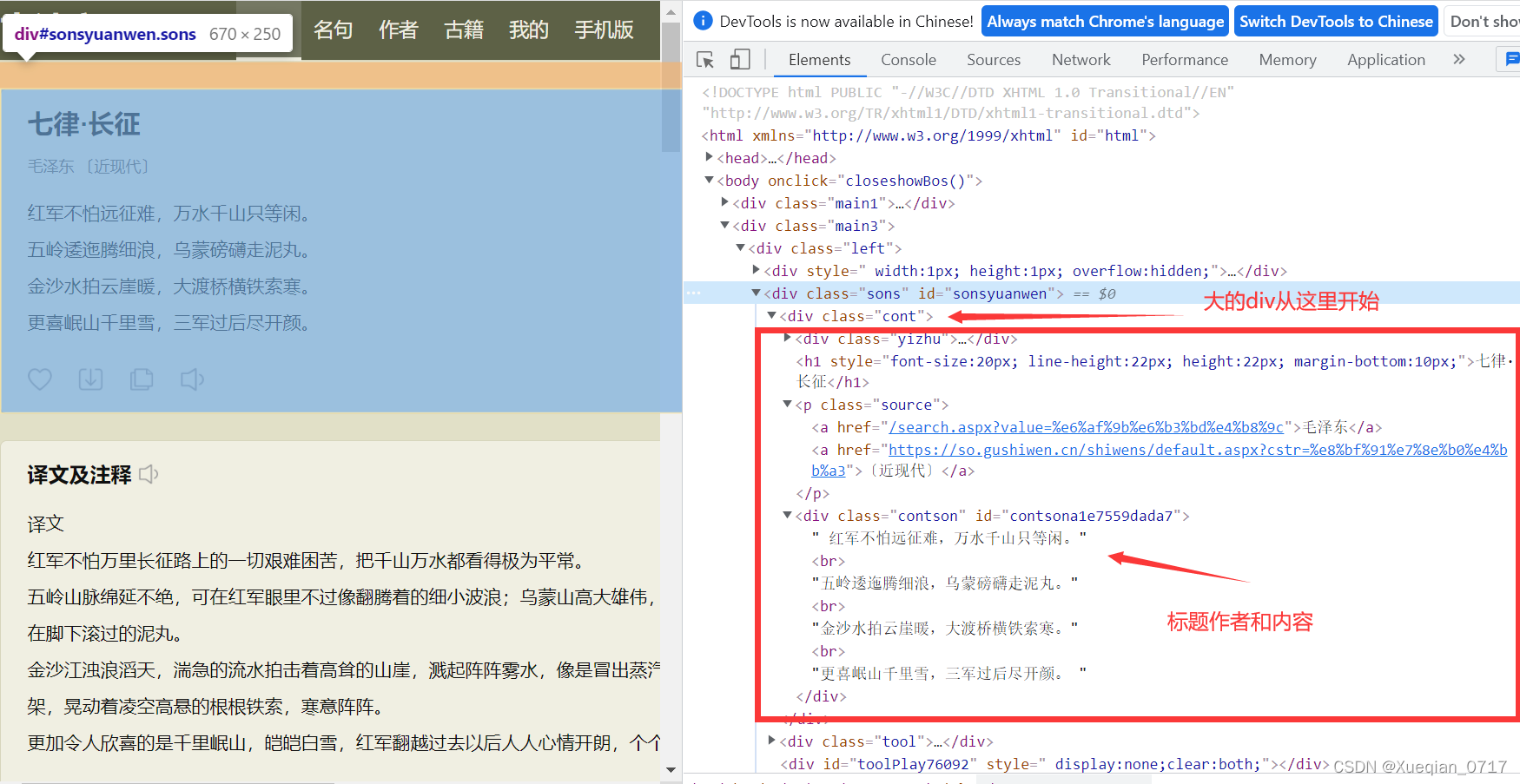
爬取古诗文网首页的所有诗文的名称 ... 上面就是网页源码经过浏览器渲染之后的样子 ...我们就是要提取上面网页源码中的所有诗词的名称,下面看下面代码,有详细的代码解释 用正则表达式提取文字 from ur...
简单的Python入门爬虫案例,爬取100首诗,视频介绍:http://www.zhishiml.com/pythondetails.html # coding=utf-8 # www.zhishiml.com #导入用到的包 import urllib.request,urllib.error #发起请求 from bs4 ...

爬虫简介 什么是爬虫: 通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。 爬虫的价值: 实际应用 就业 爬虫究竟是合法还是违法的? 在法律中是不被禁止 ...爬虫带来的风险可以体现在如下2方面: ...
反爬机制:验证码。... 识别验证码的操作 人工肉眼识别(不推荐) 第三方自动识别(推荐) ...需要收费,识别率高 ...验证码识别封装在VerificationCode.py文件里,具体代码如下: import re # 用于正则 f
全网最全 python 学习笔记
目录一、序言二、代码三、总结反思 一、序言 学完正则表达式,今天做了一个实战项目,来爬取某个古诗词网站的诗词信息。 二、代码 # 00 导入所需的包 import requests import re # 03 页面解析 def parse_page(url)...

Python Web开发记录 Day6:MySQL(关系型数据库)。
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地