本篇文章带大家认识一下网络爬虫框架Scrapy。 什么是框架: 在建筑学概念中,框架是一个基本概念上的结构,用于去解决或者处理复杂的问题。通俗来说也就是一个有约束性的架子。 在我们计算机领域中,特指为...
”python—scrapy框架爬虫—链家二手房数据_m0_50360098的博客-程序员宅基地“ 的搜索结果


成都链家的二手房和成交数据。 由于web版看不到最新的成交金额数据,因此需要用手机版的数据。 成交数据应该去重,可以做成每天增量爬取。 需要做成每天爬取一次,定时执行 参考文章技术方案 使用Scrapy框架,实现...
#需求:爬取58二手房中的房源信息 import requests from lxml import etree # 爬取到页面源码数据 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko...
自己笔记本电脑在公司跑爬虫,然后下班了,我把爬虫先暂停,然后把电脑带回家。回家后我再接着跑爬虫,它不香吗


孙建言 马雨欣 武文杰摘要:通过Python和Scrapy框架的使用,实现了一个对电商商品和商品评价信息的爬取系统,文中详细地介绍了该系统的设计过程,能够完成需求中的功能,并且对所有爬取下来的数据进行了分析,对商品...
分享一下,自己从0开始,用python爬取数据的历程。希望可以可以帮到一起从0开始的小伙伴~~加油

按照我的理解,数据分析大概整体分为5大模块——数据收集、数据清洗、数据挖掘、数据建模、数据应用。 今天,我便“开车”进军第一大模块!数据收集!!!! 数据收集,通俗一点即爬虫技术,即利用脚本模拟浏览器...
Scrapy 是一个非常优秀的爬虫框架,通过 Scrapy 框架,可以非常轻松地实现强大的爬虫系统,我们只需要将精力放在抓取规则以及如何处理抓取的数据上即可,本章介绍 Scrapy 的基础架构、安装以及 Scrapy Shell 的使用...
Scrapy是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。 Scrapy安装 安装依赖包 yum install gcc libffi-devel python-devel openssl-devel -y yum install ...
思路: ... 2、以亚马逊AMZN普通股票为例,找到股票历史数据详情页url=...3、网站采用动态加载数据,使用Selenium获取 AMZN 5年股票历史数据 4、xpath解析数据,保存至csv文件。 一、准备工作...
这是一个scrapy + splash 带cookie请求网站的示例,适用于需要登录且是js渲染的网站抓取。 1.首先需要导入这些包: 2.编写起始方法: 在方法里,SplashRequest是启动splash的方法,其他你如果是想完成登录操作的话...
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。提示:Twisted 是一个基于事件驱动的网络引擎框架,同样...
本文出自【我是干勾鱼的博客】 Ingredients: ...Python:Python 3.6.6(Python Downloads) 参考了一下网上的解决办法,是自签名的证书造成的问题。简单的解决办法,取消证书验证即可,记载代码中加入: ss...


scrapy框架之增量式爬虫 一 、增量式爬虫 什么时候使用增量式爬虫: 增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据。如一些电影网站会实时更新最近热门的电影。那么...
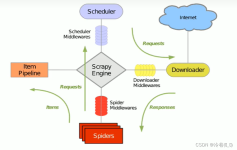
一种有想做个爬虫的想法,正好上个月有足够的时间和精力就学了下scrapy,一个python开源爬虫框架。好多事开始以为很难,但真正下定决心去做的时候,才发现非常简单,scrapy我从0基础到写出第一个可用的爬虫只用了两...

安装Scrapy主要分为一下九个步骤: 1. 安装python。(相信大家都已经安装好了) 2. 配置python环境变量。(怕大家没有配置,所以这里啰嗦一下) 3. 下载安装pywin32。 4. 下载安装pip和setuptools。(为方便后续
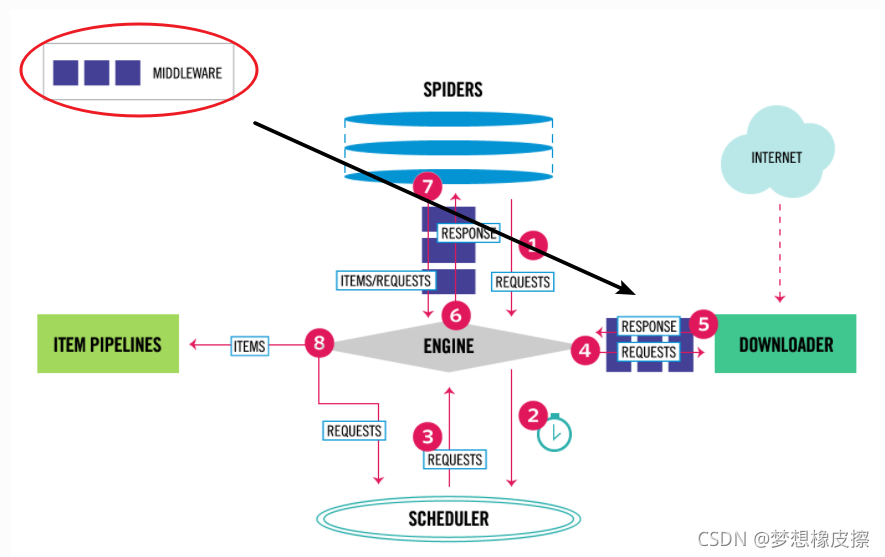
Scrapy是一个快速的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、舆情监测和自动化测试。1.Scrapy简介1.1Scrapy整体框架1.2 Scrapy组成部分(1)引擎...
【爬虫】scrapy爬虫框架
标签: python

推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地