”python—scrapy框架爬虫—链家二手房数据_m0_50360098的博客-程序员宅基地“ 的搜索结果
scrapy爬虫框架
标签: python

此爬虫主要基于Scrapy MySQL爬取链家网中,北京地区的租房信息。 Python版本为Python3.6

一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...


在使用命令行创建scrapy项目后,会发现在spider.py文件内会生成这样的代码: name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] 其中比较好理解的是name,...

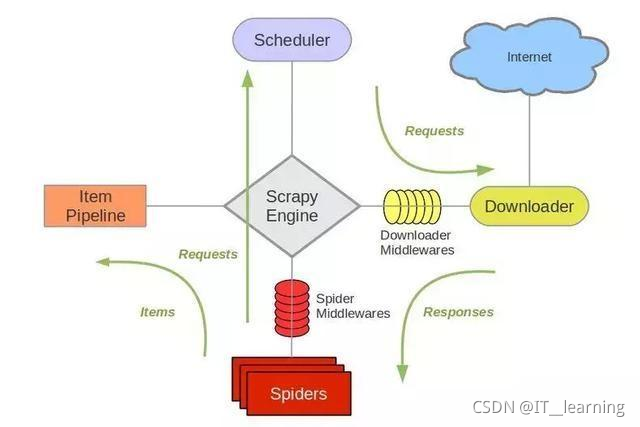
Scrapy 爬虫框架 1. 概述 Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于...

Item Pipeline介绍 Item对象是一个简单的容器,用于收集抓取到的数据,其提供了类似于字典(dictionary-like)的API,并具有用于声明可用字段的简单语法。 Scrapy的Item Pipeline(项目管道)...Scrapy犹如一个爬虫...

我们通过以上学习,仅编写了2行代码,就完成了爬取数据的工作。
由于数据量较大,本次只获取如下图热门城市房源数据 点击上图中的热门城市入口会进入该城市的首页,该网页下存放着新房、二手房以及租房的url链接。 以上海为例:url=https://sh.fang.com/ : 上海新房:url=...
商品参数书名:Python应用编程丛书:解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫定价:52.00元作者:[中国]黑马程序员出版社:中国铁道出版社出版日期:2018-08-01ISBN:9787113246785字数:页码:版次:装帧...

Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理。它的设计思想是基于Twisted异步网络框架,可以同时处理多个请求,并且可以使用多种处理数据的方式,如提取数据、存储数据等。本...
导语:网络爬虫是一种重要的数据采集技术,而Python提供了多种强大的网络爬虫框架。本文将详细介绍两个知名的Python网络爬虫框架:Scrapy和PySpider。我们将分别探讨它们的特点、用法以及示例代码,帮助你选择适合的...
Scrapy中使用ImagePipeline 保存图片
分布式爬虫scrapy-redis的搭建与运行


scrapy提供一个工具来生成项目,生成的项目中预置了一些文件,用户需要在这些文件中添加自己的代码。 打开命令行,执行:scrapy startproject tutorial,生成的项目类似下面的结构 tutorial/ scrapy.cfg ...

正是这种对数据利用的强烈需求催生了网页数据采集,也就是网络爬虫技术。网络爬虫是搜索引擎的一部分,其主要的功能就是将网络上的数据下载到本地形成一个互联网内容的本地镜像,应用十分广泛的。大数据时代,海量的...

在学习Scrapy-Redis爬虫过程中,将别人的源码导入运行后报错 TypeError: __init__() got an unexpected keyword argument 'encoding' 分析 在爬虫settings.py文件中有如下两个配置 # 调度器启用Redis存储Requests...
推荐文章
- 大数据技术未来发展前景及趋势分析_大数据技术的发展方向-程序员宅基地
- Abaqus学习-初识Abaqus(悬臂梁)_abaqus悬臂梁-程序员宅基地
- 数据预处理--数据格式csv、arff等之间的转换_csv转arff文件-程序员宅基地
- c语言发送网络请求,如何使用C+发出HTTP请求?-程序员宅基地
- ccc计算机比赛如何报名,整理:加拿大的CCC是什么,怎么报名?-程序员宅基地
- RK3568 学习笔记 : ubuntu 20.04 下 Linux-SDK 镜像烧写_rk3568刷linux-程序员宅基地
- Gradle是什么_gradle是干嘛的-程序员宅基地
- adb命令集锦-程序员宅基地
- 【Java基础学习打卡15】分隔符、标识符与关键字_java分隔符有哪三种-程序员宅基地
- Python批量改变图片名字_python批量修改图片名称-程序员宅基地