减少statreduce 是一个库,用于使用 Java 中的 map step 和 R 中的 reduce step 编写用于统计计算的 Hadoop mapreduce 作业。 它提供了简单的抽象,如 ListStatReducer 和 MatrixStatReducer。 ListStatReducer 将 ...
”mapreduce编写“ 的搜索结果
通过Java编写MapReduce程序,统计每个订单中最便宜的商品,最后输出到一个文件中 本题声明: 1.采用Linux系统 2.已搭建好的hadoop集群 3.使用java编写MapReduce程序 题目分析: 1.编写MapReduce程序 2.hadoop调用...
参考链接操作步骤参考链接,来自我们老师PPT,我只是写自己的操作过程。
需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key...
一、数据格式准备 创建一个新的文件 【在master节点中】vim wordcount.txt 向其中放入内容并保存hello,world,hadoop hive,sqoop,flume,hello kitty,tom,jerry,world hadoop ...上传到HDFShdfs dfs -mkdir /wordcount...
MapReduce是Hadoop的组成部分,它是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据...


目录 前言 一、获取相应版本的hadoop-...现在进入到了学习MapReduce的阶段,当然要利用JAVA编写MaoReduce的脚本要使用Hadoop-Eclipse-Plugin的插件,这篇文章就是详细讲述如何安装该插件。在此领域本人有诸多不.
一、MapReduce主要继承两个父类: 二、使用代码实现WordCount: 回到顶部 一、MapReduce主要继承两个父类: Map 1 protected void map(KEY key,VALUE value,Context context) throws IOException,...
1.用系统自带的程序运行 运行环境:centos7 VMwareworkstation12pro hadoop2.7.7 关闭防火墙,启动hadoop。 # systemctl stop firewalld # systemctl disable firewalld 2.创建测试文件 [root@vml april]# vi ...
核心框架是MapReduce,使用Java语言编写,在执行时传递args[0]和args[1]即可。可以根据图片转换的Base64编码的不同达到去除相同内容不同文件名图片的目的。 在识别指定目录(args[0])下的图片后将去重后的图片结果...

准备工作 希望你在开始之前已经在Linux中安装好了以下几样东西: (1)jdk1.8(最新版的eclipse必须得jdk1.8以上,根据你下的eclipse版本来安装jdk,楼主原来是jdk1.7,后来换成了jdk1.8。... (2)e...
通过使用三种不同语言编写来编写分词及词频统计程序,比较在大数数据背景下,MapReduce和Spark对三种语言的适应性及其各自的效率对比;项目均采用IDEA+Maven进行构建,相关依赖均在对应pom.xml中给出; 软件架构 ...


编写MapReduce任务 实验要求 本次实验输入为包含各科成绩文本,每一行分别为科目和成绩,要求使用MapReduce模型进行编程,输出单科最高分。要求实验报告包含编写的代码以及实验步骤。 将数据上传到hdfs hadoop fs -...



hadoop-mrx Hadoop-2 的 Java MapReduce 客户端的工作示例细节Hadoop for Dummies 有这个例子来解释如何编写 Java MapReduce 客户端。 提供的代码有效,但没有引用可运行的基于 Maven 的项目。 这个项目填补了这一...


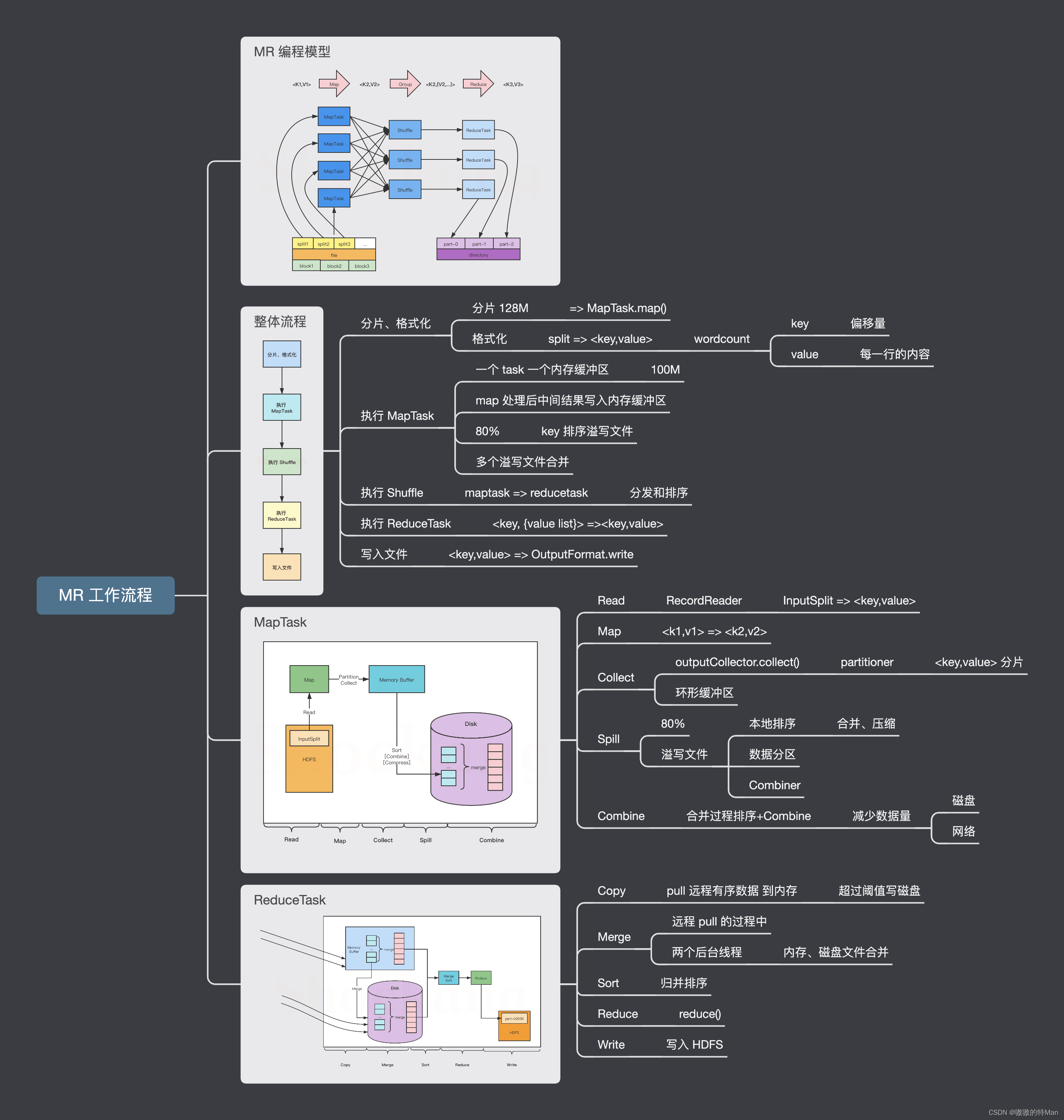
MapReduce就是一系列键值变换 一个完整的MapReduce作业,涉及三个要素:Mapper、Reducer的Driver,可以将处理过程描述成 {K1,V1} -> {K2,List} ->{K3,V3} ...而用户只需编写处理单条记录的Mapper类,框架会负责将大
MapReduce是一个用于处理和生成大型数据集的编程模型和相关实现。用户指定处理键/值对的map函数来生成一组中间键/值对,以及合并与同一中间键相关的所有中间值的reduce函数。如本文所示,该模型可以表达许多现实世界...
csv是由逗号“,”来分割的文件,在编写Mapper类的时候需要以“,”分割成一个个的数据 查看一下csv数据 以上是为了测试做的数据,要处理的结果就是经过mapreduce再原封不动的出来,因为是测试,所以内容不做任何...
现有的在多核平台上实现的MapReduce的库(如凤凰)一般是用共享内存P线程编写的,它会使共享内存访问具有不确定性。如果应用程序提供的地图或reduce函数对输入数据的顺序敏感的话,基于这些MapReduce库的应用程序在...
推荐文章
- Java---简单易懂的KNN算法_jf.knn-%; 9 &-程序员宅基地
- 最新版ffmpeg 提取视频关键帧_从视频中获取flag-程序员宅基地
- 【ARM Cache 系列文章 11 -- ARM Cache 直接映射 详细介绍】
- Objective-C学习计划
- 【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码
- python访问组策略_python 模块 wmi 远程连接 windows 获取配置信息-程序员宅基地
- html把div做成透明背景,DIV半透明层 CSS来实现网页背景半透明-程序员宅基地
- 关机恶搞小程序
- mnist手写数字分类的python实现_TensorFlow的MNIST手写数字分类问题 基础篇-程序员宅基地
- wxpython窗口跳转_WxPython-用按钮打开一个新窗口-程序员宅基地