linux 下使用jupyter交互pyspark1. 准备(使用的是云平台的同学可以忽略此步)2. jupyter与pyspark交互 1. 准备(使用的是云平台的同学可以忽略此步) 最重要的是一定安装好了spark 安装python环境或anaconda环境,...
”linux运行pyspark“ 的搜索结果
林子雨 VirtualBox + Ubuntu[linux] 配置 java、hadoop、Spark、pyspark流程
前两篇文章详细介绍了如何在Linux系统安装单机版Spark,以及如何实现在spark里操作Anaconda,具体见链接: Linux系统安装单机版Spark Spark里使用Anaconda配置及实现 说明: 有了spark的计算环境,可以操作anaconda...
0 环境OS: Linux Mint 17.1 Rebecca (based on Ubuntu 14.04)Python: 2.7, 3.4Java: 7u1511 安装本人主要使用 python3,于是用 pip3 安装:pip3 install pyspark设置环境变量 SPARK_HOME:export SPARK_HOME="/usr/...
官网下载JDK安装包 http://www.oracle.com/technetwork/java/javase/downloads/index.html这里下载的是:jdk-8u144-Linux-x64.tar.gz2. 将安装包上传到服务器上3. 解压JDK 创建要安装Scala的目录sudo mk...
CENTOS7 Anaconda+Jupyter+Pyspark联合安装

下载spark包: ...配置环境变量 export SPARK_HOME=/home/spark-3.1.2-bin-hadoop3.2 export JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk export PATH=${PATH}:${JAVA_HOME}/bin:${SPARK_HOME
以下是在Linux系统上配置Pycharm中使用Python Spark的步骤: 1. 安装Java和Spark:首先需要安装Java和Spark。如果您已经安装了它们,请跳过此步骤。如果没有安装,请执行以下命令: ``` sudo apt-get update ...
Linux上提交文件命令。
Pyspark+TIDB
标签: 大数据
Spark 提供了大量内建函数,它的灵活性让数据工程师和数据科学家可以定义自己的函数。这些函数被称为用户自定义函数(user-defined function,UDF)。UDF分为两种类型:临时函数和永久函数。临时函数只在当前会话中...
from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession from pyspark.sql import Row from pyspark.sql.types import * # 一、创建spark sql指挥官 spark = SparkSession.builder....


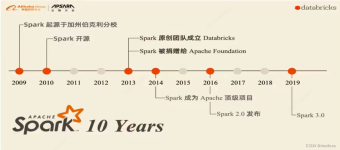
Spark风雨十年s2012年Hadoop1.x出现,里程碑意义2013年Hadoop2.x出现,改进HDFS,Yarn,基于Hadoop1.x框架提出基于内存迭代式计算框架Spark1-Spark全家桶,实现离线,实时,机器学习,图计算2-spark版本从2.x到3.x很...
1、pyspark启动 正常情况pyspark shell的启动成功后的界面: ...[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux2 Type "help", "copyright", "credits" or "license" for more information. Welcome to ...

学习Hadoop前的准备工作:1.网络 主机名称 主机映射目前是动态IP,所以需要配置IP地址为静态IP/etc/sysconfig/network-scripts ll | grep ifcfg-ens33可查看此文件的权限,只能在root下更改vi ifcfg-ens33:BOOTPROTO...

目的:安装pyspark使其启动的默认python版本为python3 python3.7.3 (1)首先安装依赖包gcc(管理员或其权限下运行) yum -y install gcc (2)安装其他依赖包(可以不安装,但是可能会安装过程中报错): yum -y ...
PySpark笔记 PySpark:Python on Spark 基于python语言,使用spark提供的pythonAPI库,进行spark应用程序的编程 ============================================================== 一、搭建PySpark的环境 1.windows上...

安装Anaconda Anaconda各版本_官网 ...bash Anaconda2-2.5.0-Linux-x86_64.sh -b -b 是指batch,即批次安装,会自动省略阅读License条款,自动安装到 /home/hduser/anaconda2 路径 添加环境变量 s
ModuleNotFoundError: No module named 'py4j'
在安装Spark之前linux的python编程环境,首先请确保您的计算机上已安装Java 8或更高版本.火花安装访问Spark下载页面,然后选择最新版本的Spark直接下载. 当前最新版本是2.4.2. 下载后,需要将其解压缩到安装文件夹...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地