如今,神经网络模型已经非常深入和复杂,需要学习很多的权重。训练此类模型非常具有挑战性。数据科学家需要建立分布式训练,检查点等。即使如此,数据科学从业者也可能无法达到理想的性能和收敛速度。...
”horovod“ 的搜索结果
PyTorch 分布式训练
标签: pytorch

RTX3090+python3.8+tensorflow1.15虚拟环境配置

home文件下空间满了,安装软件可能会出现这个问题。
step1: copy conda docker cp 本机conda虚拟环境路径 容器内虚拟环境路径 查看虚拟环境路径: conda info -e 例如: ...docker cp /home/XXX/anaconda3/envs/py38torch18 容器IP:/opt/conda/envs/ ...
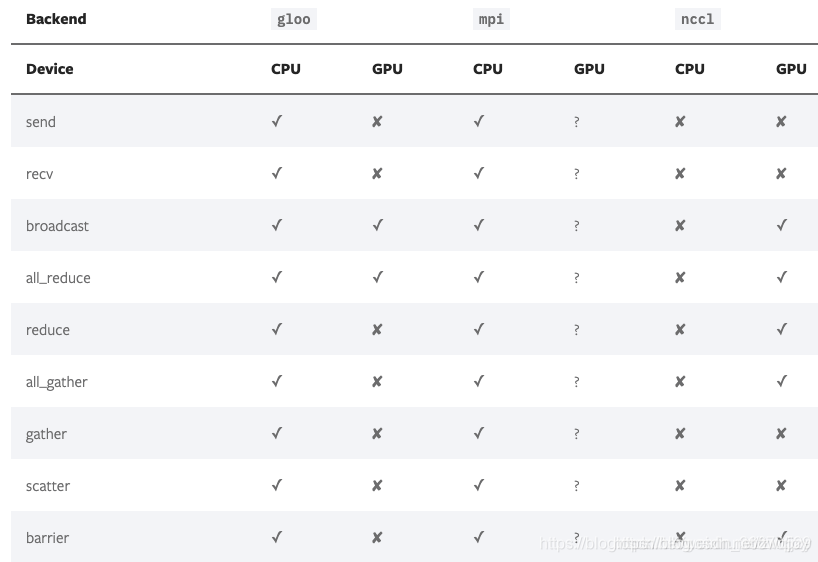
【作者】 笋江(林立翔) 驭策(龚志刚) 蜚廉(王志明) 昀龙(游亮) 一,背景——横空出世的BERT全面超越人类2018年在自然语言处理(NLP)领域最具爆炸性的一朵“蘑菇云”莫过于Google Research提出的BERT...

Linux下安装matplotlib时的报错
Ubuntu + RTX 30 series 安装 TensorFlow-GPU 在实验室服务器上安装TensorFlow遇到挺多坑,包括30系显卡适用的TensorFlow版本,以及如何在公用环境中配置自己的环境时不影响到别人,所以记录一下这些问题和解决方案...
加速。大模型
创建hadoop用户设置密码,按提示输入两次密码为 hadoop 用户增加管理员权限方便操作。
通过使用Horovod,用户可以将深度学习训练作业分发到多个计算节点上,并通过高效的通信机制将它们连接起来。总之,Horovod是Uber开源的一个分布式深度学习框架,它提供了一组工具和优化策略,帮助用户在分布式环境中...
could build wheels for horovod and tokenizers 问题解决方案
【代码】AttributeError: type object 'IOLoop' has no attribute 'initialized'

写了一个TOP-N推荐的程序,用变分自编码器对电影和用户分别进行编码和更新,然后点乘计算相似度。当我用torch.nn.functional 预定义的binary_cross_entropy_with_logits作为损失函数时,代码能够正常运行,训练没...

背景 在使用之前的代码构建环境时,报错:ERROR: Failed building wheel for xxx 翻译: ``` 错误:为xxx构建轮子失败 ``` 原因 经过查阅资料,发现是这个错误产生的原因是由于没有安装python-dev导致的,需要安装...
参考:... Horovod是Uber开源的又一个深度学习工具,它的发展吸取了Facebook "Training ImageNet In 1 Hour" 与百度 "Ring Allreduce" 的优点,可为用户实现分布式训练提供帮助。 ...
安培架构下的30系显卡仅支持CUDA11以上的版本,目前最新的Tensorflow和PyTorch虽然都可以直接使用,然而谷歌不再维护的tensorflow1.x却无法安装在CUDA11环境下。好在NVIDIA一直在维护一个1.15版本的nvidia-...
uber开源I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up ...
简介:由于云计算在资源成本和弹性扩容方面的天然优势,越来越多客户愿意在云上构建 AI 系统,而以容器、Kubernetes 为代表的云原生技术,已经成为释放云价值的最短路径, 在云上基于 Kubernetes 构建 AI 平台已经...
最近需要跑个旧代码,不知道为啥,3090 采用docker运行tensorflow1.x 版本,巨慢无比 发现一个巨好用的方法:不需要重装cuda,...pip install nvidia-tensorflow[horovod] conda install -c conda-forge openmpi exp
MacBook M1芯片下安装keras!
使用Docker搭建Hadoop技术平台,包括安装Docker、Java、Scala、Hadoop、 Hbase、Spark。集群共有5台机器,主机名分别为 h01、h02、h03、h04、h05。其中 h01 为 master,其他的为 slave。
horizon多网卡配置
标签: vmware
为某个桌面分配了3张网卡,导致原来登录正常的桌面,通过Horizon Client无法正常连接了。 查看日志,会发现有以下类似报错: Unable to launch from Pool for user <domain/user>: There were no machines ...
通过使用阿里的 AiACC 或者社区的 horovod 等分布式训练框架,仅需修改几行代码,就能将一个单机的训练任务扩展为支持分布式的训练任务。 在 Kubernetes 上常见的是 kubeflow 社区的 tf-operator 支持 Tensorflow ...
failed buliding wheel for pillow
推荐文章
- Ubuntu/linux下下载工具_ubuntu下载软件助手 linux版本-程序员宅基地
- HTML、JSP前端页面国际化(i18n)_html全局国际化-程序员宅基地
- Python高级-08-正则表达式_写出能够匹配只有下划线和数字还有字母组成(且第一个字符必须为字母)的163邮箱(@1-程序员宅基地
- 寻仙手游维护公告服务器停服更新,寻仙手游2月1日停服更新公告 2月1日更新了什么...-程序员宅基地
- 用python自动预约图书馆座位_微信图书馆座位秒抢脚本-程序员宅基地
- Android真机或模拟器激活Xposed框架的方法_de.robv.android.xposed.installer-程序员宅基地
- 操作系统为什么要分用户态和内核态_用户态和内核态都需要cpu参与,为什么要区分-程序员宅基地
- 01—JVM与Java体系结构(简单介绍)_01_jvm与java体系结构.pptx-程序员宅基地
- 国有建筑企业数字化转型整体解决方案_建筑企业数字化转型行动方案-程序员宅基地
- 性能测试的软件------loadrunner_loadrunner有有三个图标,-程序员宅基地