// 使用通配符批量删除hive表' // 注意 这里是通配符 不是正则. 通配符中 星号相当于正则中的 .* 制作脚本 // eg: 删除ods下所有 ams开头的表名 # 开头 echo 'hive -e " ' > script.sh # 删除表的sql ...
”hive使用“ 的搜索结果
Hive自定义UDF函数详解一、UDF概述二、UDF种类三、如何自定义UDF四、自定义实现UDF和UDTF4.1 需求4.2 项目pom文件4.3 Hive建表测试及数据4.4 UDF函数编写4.5 UDTF函数编写 一、UDF概述 UDF全称:User-Defined ...
hive中case when 的两种用法
规范上不允许create table as select然后使用, 应该create temporary table as select,同样可以insert into进去数据 在create table as select的时候,会有插入为null导致该表的数据类型为void的情况,这样这个...
Hive使用GBK等非UTF8字符集

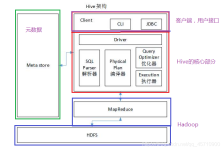
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的...
Hive动态分区一)hive中支持两种类型的分区:二)实战演示如何在hive中使用动态分区 一)hive中支持两种类型的分区: 静态分区SP(static partition) 动态分区DP(dynamic partition) 静态分区与动态分区的主要...
OR-AND 数据源: 1,22 1,21 2,22 1,20 select * from id_age where (id=1 or id =2) and age=22; 表示: 查询id=1,同时age=22或者id=2,同时age=22的数据,数据只要id=1或者id=2都要加age=22这个条件 ...
1、在from语句中使用子查询 Hive在0.12版本后就支持了from条件中子查询,例如: SELECT ... FROM (subquery) name ... SELECT ... FROM (subquery) AS name ... (Note: Only valid starting with Hive 0.13.0) 但是...

在大数据学习当中,尤其...Hive简介根据官方文档的定义,Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件1、进入hive数据库:hive2、查看hive中的所有数据库:show databa...
hive各版本主要特征 Hive 各版本关键新特性(Key New Feature)介绍 官网下载页面的介绍 hive基础 命令行接口 hive提供的用户接口包括:CLI、Client、WebUI...早期的hive版本主要使用HIVE CLI(old),之后发展为使
1.Hive安装1.1下载官网下载地址apache.fayea.com/hive/,目前最新版为...1.2 配置hive-env.sh解压文件至本地文件夹,进入/conf文件夹,编辑hive-env.sh# Set HADOOP_HOME to point to a specific hadoop install di
原始表数据最后一条的month字段信息有误,由于无法删除,所以考虑新建一张表将该条数据过滤掉。 原始表信息: 一共四个字段,其中month和day为分区字段。 执行ctas命令 create table stu_partition3 as select *...
1.Hive配置属性 (1)命令行方式 Hive配置属性存储于 hiveconf 命名空间中,该命名空间中的属性是可读写的。在查询语句中插入 '${hiveconf:变量名}',就可以通过 hive -hiveconf来替换变量。例如,查询语句和执行...

hive对数据库的基本操作
1.1 Hive引擎简介 Hive引擎包括:默认MR、tez、spark Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。 Spark on Hive : Hive只作为存储元...
最近使用hive一个多月下来(终于完成第一期数据分析迁移...总的来说,除了目前网上所介绍的常规hive使用和优化外。 因为目前hive只支持0.20的相关版本,所以我们的环境还是使用的0.20版本的hadoop来进行搭建。 使用hiv
原文:http://lxw1234.com/archives/2016/05/673.htmHive从1.1之后,支持使用Spark作为执行引擎,...具体来说,你使用的Hive版本编译时候用的哪个版本的Spark,那么就需要使用相同版本的Spark,可以在Hive的pom.xml...
统计省份出现的次数: select province,count(*) from track_info where day=‘2013-07-21’ group by province; 由于上面的只能显示在控制台,我们需要把查到的数据放在数据库中的一个表中 创建省份统计表: ...
1.创建表的时候指定为lzo格式 CREATE EXTERNAL TABLE foo ( columnA string, columnB string ) PARTITIONED BY (date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" ...
Hive之——Thrift服务
标签: Hive
Hive有个可选的组件叫做HiveServer或者HiveThrift,其允许通过制定端口访问Hive...Thrift是一个软件框架,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive。 启动Thrift Server ...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地