
”hdfs“ 的搜索结果
HDFS
数据科学导论 实验2:熟悉常用的HDFS操作 1. 编程实现以下指定功能,并利用 Hadoop 提供的 Shell 命令完成相同任务: 2. 编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream...
A.2实验二:熟悉常用的HDFS操作 本实验对应第4章的内容。 A.2.1 实验目的 (1)理解 HDFS在Hadoop体系结构中的角色。(2)熟练使用HDFS操作常用的 Shell命令。(3)熟悉HDFS操作常用的Java API。 A.2.2 实验平台 (1)操作...
$ hdfs = new \ Hdfs \ Cli (); 实例化 WebHDFS 实现: $ hdfs = new \ Hdfs \ Web (); $ hdfs -> configure ( $ host , $ port , $ user ); 更改本地文件系统的包装器。 如果您需要 hdfs 与另一个远程服务而...
以上内容仅为学习记录,如若发现问题请大家补充指正,一起学习一起记录一起进步!超全hdfs命令,包含使用案例。
编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本...
Hadoop的第一个核心组件:HDFS(分布式文件存储系统)
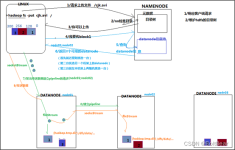
在Hadoop 中,NameNode 所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由NameNode 来管理,NameNode的可用性直接决定了Hadoop 的可用性,一旦NameNode进程不能工作了,就会影响整个集群的正常使用。...
大数据技术基础实验报告-HDFS常用操作命令
HDFS Shell UI(CLI工具) HDFS Shell是可与一起使用的HDFS操作工具目的有3种可能的用例: 运行用户交互式UI Shell,按用户插入命令使用特定的HDFS命令启动Shell 在守护程序模式下运行-使用UNIX域套接字进行通信为...
Hive的库在HDFS上就是一个以.db结尾的目录。LIKE 允许用户复制现有的表结构,但是不复制数据。LOCATION 指定表在HDFS上的存储位置。建表语句中的语法顺序要和语法树中顺序保持一致。| 表示使用的时候,左右语法二选...
Hadoop基础学习---3、HDFS概述、HDFS的Shell操作、HDFS的API操作
大数据技术基础实验报告-调用Java API实现HDFS操作
WebHDFS Python 客户端实现 WebHDFS 是 HDFS 的 REST-API。 为了方便从 Python 访问 WebHDFS,开发了 webhdfs-py。 该库可以通过 easy_install 或 pip 轻松安装: easy_install webhdfs Webhdfs-py 没有进一步的...
HDFS(Hadoop Distributed File System),意为:Hadoop分布式文件系统。是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在,也可以说大数据首先要解决的问题就是海量数据的存储问题。...
①从 NameNode 维护的的目录树里面删除路径,这也是为什么执行删除操作之后就无法再通过hdfs dfs -ls xxx 或其它 api 方式再查看到路径的根本原因**(拒绝需要被删除的文件的外部访问)**EditLog记录了hdfs操作的每...
HDFS架构、文件块大小、shell命令和读写流程等介绍
角色变量hdfs_version - HDFS 版本hdfs_cloudera_distribution - Cloudera 发行版(默认: cdh5.4 ) hdfs_conf_dir - HDFS 的配置目录(默认: /etc/hadoop/conf ) hdfs_namenode - 确定节点是否为 HDFS NameNode ...
webhdfs-Hadoop WebHDFS和HttpFs的客户端库实现,用于Ruby webhdfs gem用于访问Hadoop WebHDFS(EXPERIMENTAL:和HttpFs)。 WebHDFS :: Client是客户端类,而WebHDFS :: FileUtils是类似“ fileutils”的实用程序。...
当 Hadoop 的集群当中, NameNode的所有元数据信息都保存在了FsImage 与 Eidts 文件当中这两个文件就记录了所有的数据的元数据信息, 元数据信息的保存目录配置在了hdfs-site.xml文件中。
在提交读取或者写入map任务的时候,每个任务会有一些前置准备工作,为了尽可能接近真实数据,本次测试对比涉及了两个指标。吞吐量平均值 = 读取或者写入的总数据量 ÷ 最后一个map任务日志中显示的exec time。...
windows平台下的HDFS文件浏览器,就像windows管理器一样管理你的hdfs文件系统。现在官网已经停止更新这款软件。具体配置如下: HDFS配置页面及端口http://master:50070 配置HDFS服务器 配置WebHDFS HDFS Explorer...
HDFS的Shell操作,bin/hadoop fs 具体命令 OR bin/hdfs dfs 具体命令 dfs是fs的实现类等等。
文件写入过程是找到可以存储文件block的DataNode服务器,以便进行文件block的存储。文件读取过程是找到所需读取文件block所在的服务器DataNode,以便读取文件...hdfs文件读取过程和 上期讲的hdfs文件写入过程相反。
如上一篇博客所讲,HDFS是Hadoop的一个组件。HDFS到底用来干甚么?为什么使用它?如何使用它?我将在本篇博客中详细赘述。
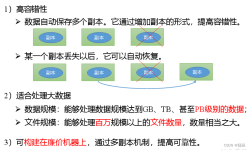
分布式文件系统(HDFS)的高可靠性主要是由多种策略及机制共同作用实现的。
HDFS特点概况 HDFS核心组件的职责 HDFS数据流程 HDFS写数据流程 HDFS读数据流程 HDFS高可用 HDFS小文件问题 HDFS特点概况 特点: 廉价 流数据读取(流数据是一组顺序、大量、快速、连续到达的数据序列) 大数据集 ...
推荐文章
- 回调函数使用详解_回调函数的用法-程序员宅基地
- [STM32F0xx]的AD转换驱动程序_stm32f0xx adc_in-程序员宅基地
- 优秀的程序员都热爱写作_程序员写作-程序员宅基地
- 为什么加深神经网络如此有效?从卷积滤波器解释_卷积深度变深什么作用-程序员宅基地
- Android Studio 混淆_android studio 开启混淆-程序员宅基地
- 专业学位计算机技术排名,山东师范大学计算机技术(专业学位)专业考研难度分析-专业排名-难度大小...-程序员宅基地
- idea配置tomcat环境_idea的tomcat,连接不显示explore-程序员宅基地
- 说说内核与计算机硬件结构-程序员宅基地
- 数据结构应用案例——栈结构用于8皇后问题的回溯求解-程序员宅基地
- c语言scanf中的分隔符的作用,C语言中scanf与分隔符(空格回车Tab)-程序员宅基地