Hadoop相关参数调优
”hadoop调优“ 的搜索结果
hadoop调优之一@(HADOOP)[hadoop]hadoop调优之一 一概述 一硬件环境 二map任务原因 三reduce任务的原因 四hadoop的配置不当 五JAVA代码及JVM调优 一硬件调优 1CPU内存使用情况vmstattop 2网络 3磁盘健康情况 二map端...

Hadoop数据倾斜问题 maptask将大量的相同的key分配到同于一个分区中导致reducetask接受的数据大小不均衡,降低mapreduce的运行速度 Hadoop数据倾斜问题解决方案 1)设定自定义分区规则平衡reduce获取的数据 2)使用...
NameNode进程挂了并且存储数据丢失了,如何恢复NameNode?...恢复NameNode的步骤:停止所有Hadoop进程启动Secondary NameNode从Secondary NameNode备份的编辑日志和文件系统镜像中恢复NameNode元数据。
linux参数以下参数最好优化一下: 文件描述符ulimit -n 用户最大进程 nproc (hbase需要 hbse book) 关闭swap分区 设置合理的预读取缓冲区 Linux的内核的IO调度器JVM参数JVM方面的优化项Hadoop Performance ...
Hadoop调优 mapred.tasktracker.map.tasks.maximum 官方解释:The maximum number of map tasks that will be run simultaneously by a task tracker. 我的理解:一个tasktracker最多可以同时...
hadoop调优参数列表.hadoop调优参数列表.hadoop调优参数列表. 相关下载链接://download.csdn.net/download/fantasy179/10418346?utm_source=bbsseo
Hadoop调优之调度算法详解一,大数据开发的基本语法在这里。 相关下载链接://download.csdn.net/download/caogan118/10307260?utm_source=bbsseo
Hadoop 相关调优
标签: hadoop 调优
作业调优检查的范围: Mapper的数量 mapper需要运行多长时间?如果平均只运行几秒钟,则可以看是否能用更少mapper运行更长时间,通常一分钟左右。时间长度取决于使用的输入格式。 Reducer的数量 为了达到...
hadoop job -list hadoop job -kill job_201212111628_11166 修改yarn.scheduler.maximum-allocation-mb 和 yarn.nodemanager.resource.memory-mb的默认值为2G 然后重启集群 如果资源充足也可以适当...
5、HDFS的Handler数量由dfs.namenode.handler.count、dfs.namenode.service.handler.count和dfs.datanode.handler.count控制。Dfs.namenode.service.handler.count Namenode的RPC服务端用于监听来自datanode和所有非...
Hadoop调优 mapred.tasktracker.map.tasks.maximum 官方解释:The maximum number of map tasks that will be run simultaneously by a task tracker. 我的理解:一个tasktracker最多可以同时运行的map...
version:spark-2.4.0-bin-hadoop2.7 #1.在HDFS创建目录 /spark/jars bin/hadoop dfs -mkdir -p /spark/jars#2.将$SPARK_HOME/jars下所有包上传到hdfs目录 /spark/jars bin/hadoop dfs -put /opt/bigdata/spark../...
https://blog.csdn.net/dehu_zhou/article/details/52808752https://blog.csdn.net/dxl342/article/details/52840455 ... Hadoop性能调优 1. 简介 Hadoop性能调优...
因为集群资源紧张,导致集群在使用的时候原来粗放示的任务已经极为耗集群的资源,于是进行调整, 把原来有mapreduce的jar任务和hive任务进行组合的任务进行修正,全部改成由jar包任务的任务模式, ...

hadoop经验调优
标签: hadoop
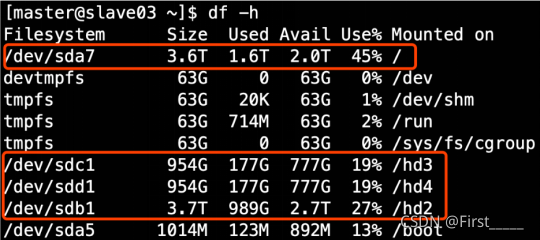
应用层面调优 排序在大数据中的使用 reduce数量的控制 执行计划在调优中的使用 join在大数据中的使用 官网描述: Syntax of Order By: 在使用“order by”子句时有一些限制:如果是在严格模式下:(hive.mapred....
NameNode多目录配置 NameNode的本地目录可以配置多个,且每个目录存放内容相同,增加了可靠性。 ...
注意:本文使用的Hadoop版本为3.2.1版本 目录 一、HDFS多目录存储 1.1 生产环境服务器磁盘情况 1.2 在hdfs-site.xml文件中配置多个目录,需要注意新挂载磁盘的访问权限问题。 二、集群数据均衡 2.1 节点间数据均衡 1...
hadoop参数调优: core-site.xml,hdfs-site.xml,mapred-site.xml三个配置文件,根据实际应用场景对参数进行配置,比如io.seqfile.compress.blocksize(块压缩时块的最小块大小),dfs.block.size(每个文件块的大小,默认是...
python脚本自动生成hadoop集群设置中的内存相关系数(Hadoop调优)小编在搭建hadoop集群的过程中,发现集群进程总是莫名其妙的被杀死,通过研究发现是hadoop默认的每台节点分配的内存大小为8G,在学习过程中一般都使用...
NameNode内存生产配置 NameNode内存默认是2000M,怎么配置NN的内存? ...

hadoop调优-HDFS集群数据不均衡处理hdfs balancer
Hadoop参数调优
标签: 大数据
Namenode有一个工作线程池用来处理Datanode的并发心跳及客户端的并发元数据操作 调节hdfs-site.xml中dfs.namenode.handler.count的参数,默认值10。
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地