松下FP0R用于替代FP0系列,性能比FP0有很大提升,同时指令的用法上也有差别。
”fp“ 的搜索结果
FP树是用来挖掘最大频繁k项集的一种数据结构,相对来说难度较大,因为在前辈们的博客中,对于FP树的实现讲的是比较清楚了,但是对于FP的编程思路却提的很少。在这里做一个简单的梳理。 FP树的基础知识 首先请花...


这个报错说的是whisper要使用cpu,而你音频是fp16的,cpu不支持。要点在于如何解决为什么whisper没使用GPU应该是搞别的时候把torch给搞成cpu版本的了。
一张图深入理解机器学习的各种晦涩难懂的评价指标!
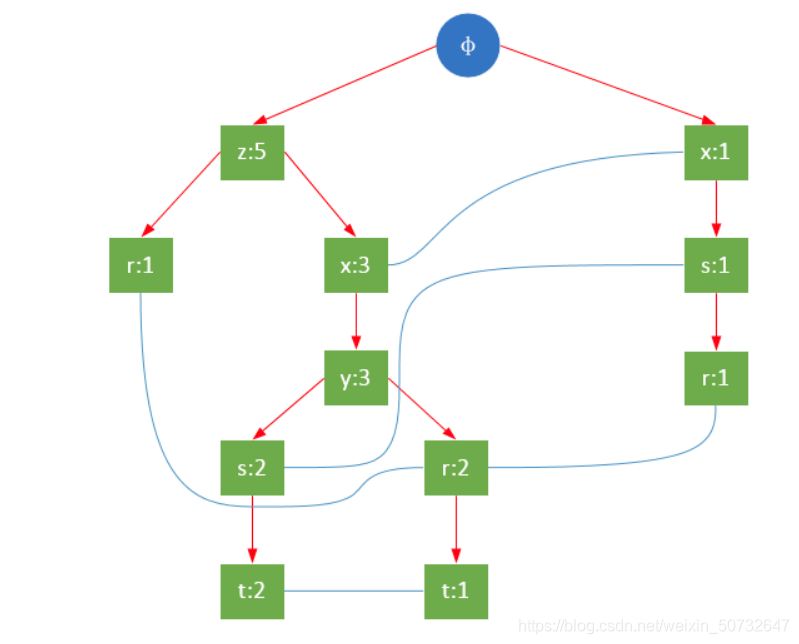

利用函数单向S-粗集和函数单向S-粗集对偶,结合元素迁移的随机特征,给出了Fp-规律的概念及Fp-规律的随机结构,提出了的Fp-规律的积分度量,讨论了Fp-规律积分度量依概率变化的特性。并举例说明Fp-规律积分度量在系统...
松下FP-XH手册位置功能篇
标签: PLC
松下FP-XH手册位置功能篇,最新松下PLC控制、编程。
关联规则--FpGrowth算法思想及编程实现构建FpTree 本文为博主原创文章,转载请注明出处,并附上原文链接。 原文链接: FpGrowth算法,全称:Frequent Pattern Growth—-频繁模式增长,该算法是Apriori算法的改进版本...
以西瓜数据集为例,我们来详细解释一下什么是TP、TN、FP以及FN。 一、基础概念 TP:被模型预测为正类的正样本 TN:被模型预测为负类的负样本 FP:被模型预测为正类的负样本 FN:被模型预测为负类的正样本 二、...


c++实现的fp—tree的生成过程,有图形化界面。
FP5139 DC-DC升降压
标签: 5139
dc-dc升降压芯片,外置mos,带on/off管脚
关于fp-ts生态系统的令人敬畏的事情的集合。 一般资源 fp-ts是用于TypeScript中的类型化功能编程的库。 学习资源 一本清晰的gitbook,其中包含基本说明 Guilio Canto(FP-TS创作者)博客文章 功能设计系列 高级...
在运用LoRA对ChatGLM-6B(FP16)大语音模型时,遇到了bug1:ValueError: Attempting to unscale FP16 gradients. 和 bug2: AttributeError: 'ChatGLMTokenizer' object has no attribute 'sp_tokenizer'. Did you ...

FP增长(FP-growth)算法是一种高效发现频繁项集的方法,只需要对数据库进行两次扫描。它基于Apriori构建,但在完成相同任务时采用了一些不同的技术。该算法虽然能更为高效地发现频繁项集,但不能用于发现...
文章目录sp 栈顶指针寄存器fp 栈底指针寄存器 (x29)arm64没有push 和 pop操作栈开辟的空间是16的倍数叶子函数的栈平衡非叶子函数的汇编操作栈平衡 sp 栈顶指针寄存器 这个跟win32的esp一样.始终指向栈顶的地址....
FP32(Full Precise Float 32,单精度)占用4个字节,共32位,其中1位为符号位,8为指数位,23为尾数位。 FP16(float,半精度)占用2个字节,共16位,其中1位为符号位,5位指数位,十位有效数字位。与FP32相比,FP...

之前的格物汇文章给大家介绍过,无论是提供商品还是服务,用户画像都是数据挖掘工作的重要一环。而要深度构建用户画像,就必须对用户的数据进行关联...今天的格物汇就带大家来了解一种新的算法:FP Tree。只需要全部...
构建FP树 挖掘频繁项集 算法简介 FP-growth算法的应用我们经常接触到。比如,你在百度的搜索框内输入某个字或词,搜索引擎会自动补全查询词项,而这些词项都是和搜索词经常一起出现的。 FP-growth算法被用来...
FP32 format. kHALF //!< FP16 format. kINT8 //!< INT8 format. kINT32 //!< INT32 format. kTF32 //!< TF32 format. TF32精度 TF32 Tensor Cores 可以使用 FP32 加速网络,通常不会损失准确性。 ...
FP-growth算法简介 FP-growth算法是在2000年提出的频繁项集挖掘算法,前面我们介绍了Apriori挖掘频繁项集并且进行关联分析,FP-growth和Apriori选择频繁项集有类似地地方,但是本质和Apriori完全不一样。 FP-growth...
是用C++语言编写的FP算法,代码可读性好,而且可以直接可以运行的!

社区驱动实用程序包 ... fp-ts-contrib取决于 ,从0.1.0开始,您必须手动安装fp-ts ( fp-ts在peerDependency列出) TypeScript兼容性 fp-ts-contrib版本 所需的typescript版本 0.1.x + 3.5+ 文献资料
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地