Flume NG 是Cloudera提供的分布式数据收集系统,它能够将不同数据源的海量日志数据进行高效的收集、聚合、移动,最后存储到存储中心。Flume NG支持(故障转移)failover和负载均衡。
”flume“ 的搜索结果
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的...
flume事务,flume组件结构,flumeSource类型
集群flume详细安装步骤
标签: 实时大数据
集群flume详细安装步骤,接收Kafka消息配置
上面构建的镜像只是将相应的服务打进了镜像里,使用时应挂载相应flume-ng配置和supervisor应用配置,以下为我使用。-compose启动flume服务的相应docker-compose.yaml部分配置。的解压包conf复制出来,因为映射会影响...
Flume 的 nagios 检查 如果您使用 Apache Flume ( ) 来移动数据,就像我们在 Voxer 的生产分析系统中所做的那样,您可能会发现这个 Nagios 插件很有用。 我们最终会在这里添加一些更有用的信息。
如果你的flume中配置了向kafka中发送数据的sink,需要将这些jar包放到flume的lib目录下

文章目录一、启动 Kafka二、创建 Topic 消息队列三、查询 kafka 消息队列四、启动 consumer 监控窗口五、写 Flume 自定义配置文件六、开启 Flume七、结果分析 一、启动 Kafka kafka-server-start.sh /opt/soft/kafka...
flume-ng-sql-source-1.5.2源码
利用Flume将MySQL表数据准实时抽取到HDFS、MySQL、Kafka用到的jar包
flumeng-kafka-plugin 技术指标水槽1.4 Kafka 0.8.0 Beta



batchSize——Maximum number of messages written to Channel in one batch 每批次写入channel的最大条数 capacity——The maximum number of events stored in the channel channle 容纳的最大event条数 ...
ansible自动部署flume集群组成消费组共同消费kafka集群Topic,压缩包包含了详细的ansible部署代码、编译好的flume压缩包、以及生产环境flume参数设置,可以私信请教我,详细指导讲解

水槽附加器 Flume appender 从一系列日志库(log4j、logback)推送日志事件
spark-streaming-flume-sink_2.11-2.0.0.jar的jar包。
flume-ng-sql-source-1.5.1 flume连接数据库 很好用的工具
sparkstreming结合flume需要的jar包,scala是2.11版本,spark是1.6.2版本。也有其他版本的,需要的留言找我要
flume-ng-1.5.0-cdh5.3.6.rarflume-ng-1.5.0-cdh5.3.6.rar flume-ng-1.5.0-cdh5.3.6.rar flume-ng-1.5.0-cdh5.3.6.rar flume-ng-1.5.0-cdh5.3.6.rar flume-ng-1.5.0-cdh5.3.6.rar flume-ng-1.5.0-cdh5.3.6.rar flume...
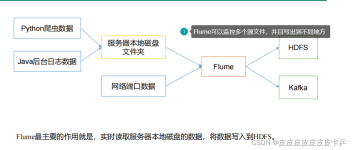
Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是帮助用户将大规模数据从各种数据源(如日志文件、网络数据源、消息队列等)采集、传输和加载到数据存储系统(如 Hadoop HDFS、...
由于Flume的netcatudp为sources,avro为sink时,udp数据发送会报null of map in field headers of org.apache.flume.source.avro.AvroFlumeEvent of array。但是此类解决了这个问题。只需要将此类放在Flume安装的lib...

kafkaSink.type = com.zyy.bi.flume.sink.KafkaSink kafkaSink.channel = kafkaSink.metadata.broker.list = kafkaSink.topic = custom.partition.key = Flume事件标头custom.encoding =事件主体编码
如果是日志类型的日志,需要用到Flume导入大数据平台。 Flume是一个分布式、 基于流式数据。Flume的灵魂(Agent)就是采集(source)、聚合(channel)、转移(sink)。对于Flume只需要会配置,并不需要(或者...
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地