Flume是一种分布式、具有高可靠和高可用性的数据采集系统,可从多个不同类型、不同来源的数据流汇集到集中式数据存储系统中。本篇文章介绍Flume架构、安装配置及其Spark应用。
”flume“ 的搜索结果
flume学习总结3
标签: flume
flume是分布式的,可靠的,用于从不同的来源有效收集 聚集 和 移动 大量的日志数据用以集中式的数据存储的系统。 是apache的一个顶级项目
推荐项目:Flume-Kafka-Storm 数据流处理框架 项目地址:https://gitcode.com/supermy/flume-kafka-storm 该项目(GitCode仓库)是一个集成Apache Flume、Kafka和Storm的数据流处理解决方案,旨在提供高效、可扩展且...
Flume本身是由Cloudera公司开发的后来贡献给了Apache的一套针对日志数据进行收集(collecting)、汇聚(aggregating)和传输(moving)的机制Flume本身提供了简单且灵活的结构来完成日志数据的传输Flume-ogFlume-ng。
flume学习总结1
标签: flume
flume是分布式的,可靠的,用于从不同的来源有效收集 聚集 和 移动 大量的日志数据用以集中式的数据存储的系统。 是apache的一个顶级项目
flume 用户操作手册 flume 用户操作手册 flume 用户操作手册
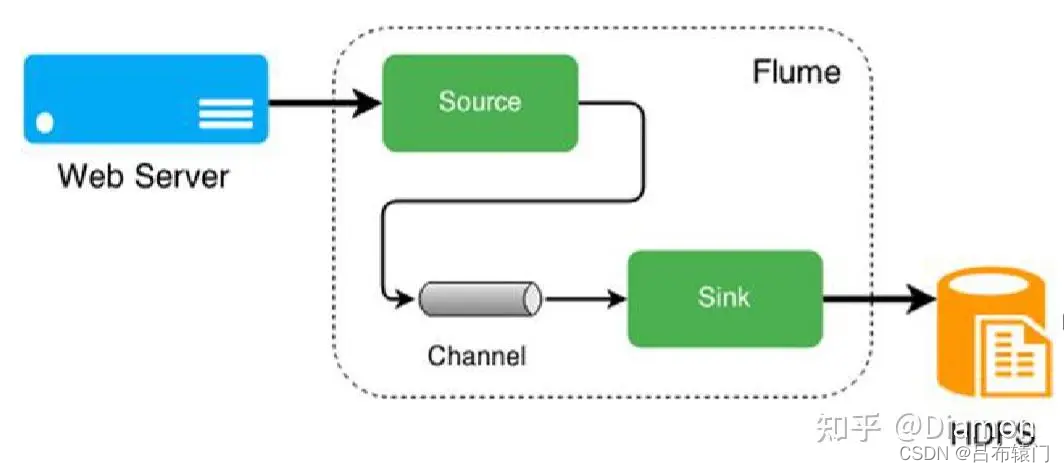
Flume组件: agent source channel sinkkafka组件:节点集群服务器 **consumer **
分享一套我整理的面试干货,这份文档结合了我多年的面试官经验,站在面试官的角度来告诉你,面试官提的那些问题他最想听到你给他的回答是什么,分享出来帮助那些对前途感到迷茫的朋友。
Flume实战篇-采集Kafka到hdfs
一、Flume优化 1、调整Flume进程的内存大小, 建议设置1G~2G,太小的话会导致频繁GC 因为Flume进程也是基于Java的,所以就涉及到进程的内存设置,一般建议启动的单个Flume进程(或者说单个Agent)内存设置为1G~2G,...
这个报错的原因是里面有JSONObject这个类找不到,解决办法有两个,要么把对应的这个类单独上传到flume的lib目录下,要么重新打包,把带dependencies的jar传到lib目录下。我要起一个将kafka上的topic_log主题中的数据...
配置Channel agent。配置Source agent。配置Sink agent。
Apache Flume 是一个分布式、可靠、高可用的日志收集、聚合和传输系统。它常用于将大量日志数据从不同的源(如Web服务器、应用程序、传感器等)收集到中心化的存储或数据处理系统中。Apache Flume 是一个强大的数据...
华为大数据认证,Flume组件介绍
* 下载安装包:apache-flume-1.11.0-bin .tar.gz * 上传至 linux 的 /opt/ 目录下 * 解压至 /opt/apps(可以自定义目录) * 修改简短名称(方便配置) * 配置环境变量(方便调用)
项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 ...
文章目录一、复制和多路复用二、负载均衡和...使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储 到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local File...
用于flume的安装,zookeeper的安装,Hadoop的安装,安装mysql的一些jar包。安装好flume,要先安装好java环境
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。为什么选用 Flume?
说我这个文件打不开,我一查,后面有段注释,删了再跑?、讲解视频,并且后续会持续更新**哟,正常了,原来如此~
flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析【大数据】
flume增量读取mysql数据写入到hdfs-附件资源
大数据之flume开发实例
标签: flume

apache-flume-1.9.0-bin.tar.zip apache-flume-1.9.0-bin.tar.zip apache-flume-1.9.0-bin.tar.zip

flume-ng-core版本:1.9.0-CDH-6.2.0 这个jar包是从Git上下载源码并修改Pom.xml文件之后,重新编译过的。之所以重新编译,是因为源码直接编译出来的jar包,里面有一个方法返回值不兼容,编译详情可以参考我的文章...
flume定制化sink
标签: flume
flume定制化sink,用于参考,使用了多线程及读取配置文件的技术
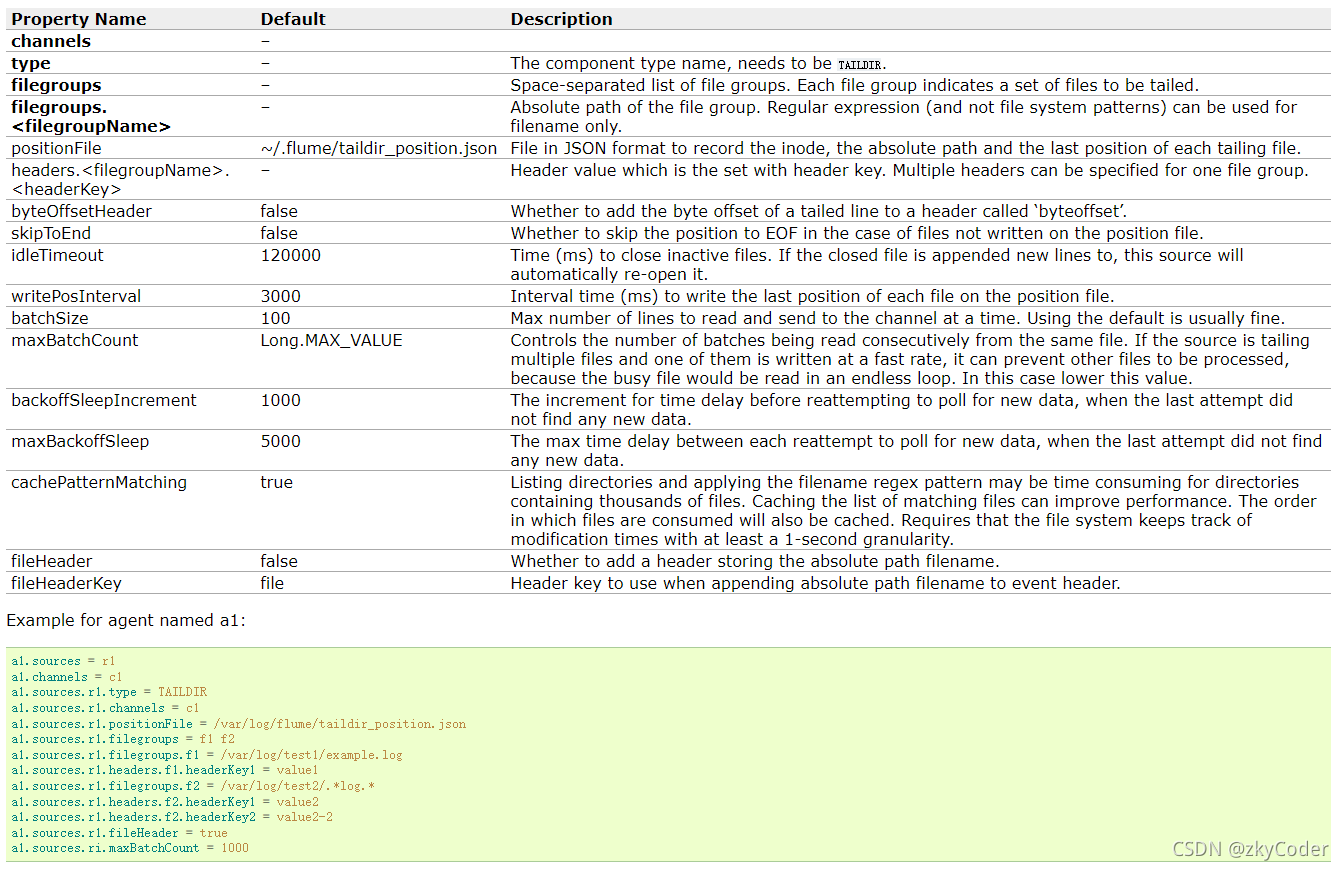
flume-chd版本
标签: flume-
这个是linux下flume-chd版本压缩包
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地