1.抽象出来一个动态表,并未进行存储,是Flink支持流数据的tableAPI和sql的核心概念,随时间变化的,查询动态表会生成一个连续的查询,结果是一个动态表2.hive进入命令行需要先启动元数据服务,在查数据的时候数据是...
”flink-sql“ 的搜索结果

这个资源提供了一系列关于大数据流处理框架FlinkCDC 3.0的实战教程,从基础到进阶,涵盖了DataStream和FlinkSQL的深入解读和应用。资源包括了详细的资料和相关视频,帮助学习者全面掌握FlinkCDC 3.0的使用和应用。 ...
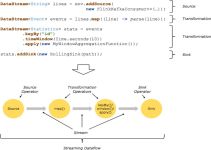
Table API和SQL是最上层的API,在Flink中这两种API被集成在一起,SQL执行的对象也是Flink中的表(Table),所以我们一般会认为它们是一体的。Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理...
flinksql 从入门到入门...
flink-sql-connector-oceanbase-cdc 2.5-SNAPSHOT
flink同步mysql数据库所用包
flink-sql-submit-client 执行Flink SQL 文件的客户端 Flink 版本:flink 1.11.0 其他版本待测试 是在的基础上修改而来 使用简单方便 需要指定FLINK_HOME 下载上面code中的jar包 修改 sql-submit.sh 脚本中jar包的...
由于jar包的下载速度很慢,我想也有很多下载慢的同学,分享下
flink-sql-connector-hive-3.1.2_2.11-1.11.6.jar 已经解决guava冲突亲测可以
flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar
flink-sql-connector-kafka_2.11-1.12.0
flink cdc mysql jar包,2021年最新版
flink cdc postgres 数据同步 jar包,2021年最新版
flink-sql-connector-mysql-cdc-1.1.1.jar
flink-sql-connector-kafka_2.11-1.11.2.jar
使用Flink SQL,Kafka,MySQL,Elasticsearch和Kibana构建端到端流应用程序。 您可以在此处下载数据: : 这是用于构建将在tuturial中使用的docker的存储库。 博客: :
flink-sql-connector-kafka_2.12-1.13.1.jar 是 Apache Flink 的一个 Kafka SQL Connector 的 JAR 包,用于在 Flink SQL 环境中与 Apache Kafka 集成。这里面的数字 2.12 和 1.13.1 分别表示了这个 JAR 包所依赖的 ...
flink-sql集成rabbitmq
flinkcdc oracle 2.3.0
flink-sql-connector-mongodb-cdc 2.5-SNAPSHOT
flink-streaming-platform-web系统是基于Apache Flink 封装的一个可视化的、轻量级的flink web客户端系统,用户只需在web 界面进行sql配置就能完成流计算任务。主要功能:包含任务配置、启/停任务、告警、日志等功能...
使用flink-connector-sqlserver-cdc 2.3.0把数据从SQL Server实时同步到MySQL中。
齐柏林飞艇上的flink-sql-cook
flink-sql-connector-kafka_2.11-1.12.2.jar
flink-sql-demo所用到的测试数据part2.
flink-sql-demo flink-sql-demo 一个yml文件 部署集群 打开可以看到 备份
flink-sql-hdfs-connector支持根据数据的事件时间落到对应的分区目录分支说明master分支不放代码,分支对应适应相同版本的flink,例如分支flink-1.10就仅在flink 1.10版本上测试通过使用方法下载代码编译cd flink-...
Flink1.14.4自定义flink-connector-jdbc连接SQLServer和SAP数据库
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地