
”bert“ 的搜索结果
BERT
标签: JupyterNotebook
BERT

本课件是对论文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 的导读与NLP领域经典预训练模型 Bert 的详解,通过介绍NLP领域对通用语言模型的需求,引入 Bert 模型,并对其...
1.即使下游任务各有不同,使用BERT微调时君只需要增加输出层2.但根据任务的不同,输入的表示,和使用Bert特征也会不一样!pip install d2l==0.17.6 ### 很重要,不要下载错了,对于colab。
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型,它是自然语言处理(NLP)领域的重大里程碑,被认为是当前的State-of-the-Art模型之一。BERT的设计理念和结构基于Transformer...

不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~给大家准备的...
此外,还引入了Hugging Face的transformers库,用于使用BERT和roBERTa模型进行文本处理。最后,为了结果的可重现性,设置了一个种子(seed),并对绘图样式进行了一些配置。通过传入真实标签 y、预测标签 y_pred 和...
BERT详解:概念、原理与应用
在pytorch上实现了bert模型,并且实现了预训练参数加载功能,可以加载huggingface上的预训练模型参数。 主要包含以下内容: 1) 实现BertEmbeddings、Transformer、BerPooler等Bert模型所需子模块代码。 2) 在子模块...
1、内容概要:本资源主要基于bert(keras)实现文本分类,适用于初学者学习文本分类使用。 2、数据集为电商真实商品评论数据,主要包括训练集data_train,测试集data_test ,经过预处理的训练集clean_data_train和...
多模态情感分析——基于BERT+ResNet50的多种融合方法,数据学院人工智能课程第五次实验代码 本项目基于Hugging Face和torchvision实现,共有五种融合方法(2Naive 3Attention),在Models文件夹中查看 ...
bert,BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google AI在2018年提出。BERT的出现标志着自然语言处理(NLP)领域的一个重大突破,因为它在多项NLP任务中...
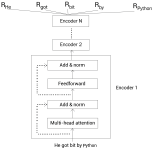
bert文本分类 代码+数据bert文本分类 代码+数据bert文本分类 代码+数据
Fast-Bert是一个深度学习库,允许开发人员和数据科学家针对基于文本分类的自然语言处理任务训练和部署基于BERT和XLNet的模型。 FastBert的工作建立在优秀的提供的坚实基础上,并受到启发,并致力于为广大的机器...
在Pyrotch上实现情感分类模型,包含一个BERT 模型和一个分类器(MLP),两者间有一个dropout层。BERT模型实现了预训练参数加载功能,预训练的参数使用HuggingFace的bert_base_uncased模型。同时在代码中实现了基于预...
bert,传统的语言模型通常是从左到右或者从右到左进行训练,这样的模型只能捕捉到文本的一个方向的上下文信息。然而,现实世界中的语言理解往往需要同时考虑上下文的前后信息。BERT的核心思想是通过使用Transformer...
bert,Next Sentence Prediction (NSP):这个任务旨在预测两个句子是否在原始文本中是连续的。BERT会接受两个句子作为输入,任务是预测第二个句子是否紧跟在第一个句子之后。
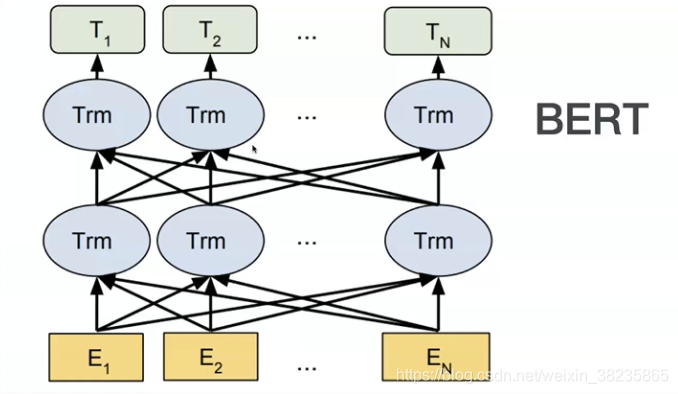
BERT-pytorch
标签: Python
伯特·比托奇 Google AI的2018 BERT的Pytorch实现,带有简单注释BERT 2018 BERT:用于语言理解的深度双向变压器的预培训论文URL: : 介绍Google AI的BERT论文显示了在各种NLP任务(新的17个NLP任务SOTA)上的惊人...
BERT的对抗性嵌入 上基于BERT的情感分类对抗嵌入生成与分析。 建立在对Google Research之上。 IMDB加载器和处理器功能取自。 存储库还包括一种算法,用于投影对抗性嵌入内容以获得对抗性离散文本候选对象。 尽管该...
bert,BERT通过两个主要的预训练目标来学习语言表示: Masked Language Model (MLM):在这个任务中,输入文本中的一部分单词会被随机遮蔽(替换为一个特殊的[MASK]标记),BERT的目标是预测这些遮蔽的单词。
词向量 词向量_使用BERT预训练模型生成词向量+句向量
使用说明保存预训练模型在数据文件夹下├──数据│├──bert_config.json │├──config.json │├──pytorch_model.bin │└──vocab.txt ├──bert_corrector.py ├──config.py ├──logger.py ├──...
Bert
https://huggingface.co/google-bert/bert-base-chinese pytorch和tensorflow都有
我们已经证明,除了BERT-Base和BERT-Large之外,标准BERT配方(包括模型体系结构和训练目标)对多种模型尺寸均有效。 较小的BERT模型适用于计算资源有限的环境。 可以按照与原始BERT模型相同的方式对它们进行微调。...
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地