本文由 网易云 发布本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)2.Spark Streaming架构及特性分析2.1 基本架构基于是spark core的spark streaming架构。Spark Streaming是将流式...
”Storm,Spark和Flink三种流式大数据处理框架对比_天高地阔的专栏-程序员宅基地“ 的搜索结果
Flink也提供 API来像Spark一样进行批处理,但两者处理的基础是完全不同的。Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有 的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。1.1 基...


在 Flink Forward Asia 2021 的主题演讲中,Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰提出了 Flink 下一步的发展方向——流式数仓(Streaming Warehouse,简称 Streamhouse),Flink 要从 ...
文章目录Flink 是什么Flink定义有界流和无界流有状态的计算架构为什么要用Flink应用场景特点和优势流式计算框架对比 Flink 是什么 在数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据...
对于流式处理查询,与连续表上的常规 Top-N 不同,窗口 Top-N 不会发出中间结果,而只会发出最终结果,即窗口末尾的前 N 条记录总数。此外,Window Top-N可以与基于窗口TVF的其他操作一起使用,例如窗口聚合,窗口...
本文介绍的CDC是基于2.4版本,当前版本已经发布至3.0,本Flink 专栏介绍是基于Flink 1.17版本,CDC 2.4版本支持到1.17版本。Apache Flink®的CDC连接器是用于Apache Flnk®的一组源连接器,使用更改数据捕获(CDC)...
为提供 Java/Scala 的自定义函数,你首先需要实现和编译函数类,该函数继承自 ScalarFunction、 AggregateFunction 或 TableFunction(19、Flink 的table api与sql之内置函数: Table API 和 SQL 中的内置函数一个或...
一、Flink 专栏Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、...
Spark Streaming vs Flink 两者最重要的区别(流和微批) (1). Micro Batching 模式(spark) Micro-Batching计算模式认为"流是批的特例",流计算就是将连续不断的微批进行持续计算,如果批足够小那么就有足够小的延时,...
Batch 计算的,但是在 2014 年, StratoSphere 里面的核心成员孵化出 Flink,同年将 Flink 捐赠 Apache,并在后来成为 Apache 的顶级大数据项目,同时 Flink 计算的主流方向被定位为 Streaming, 即用流式计算来做...
Flink 流数据处理
标签: Flink教程
序言 基于官网教程整理的一个教程。基于Flink1.12.0版本。 参考资料: ...无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是...
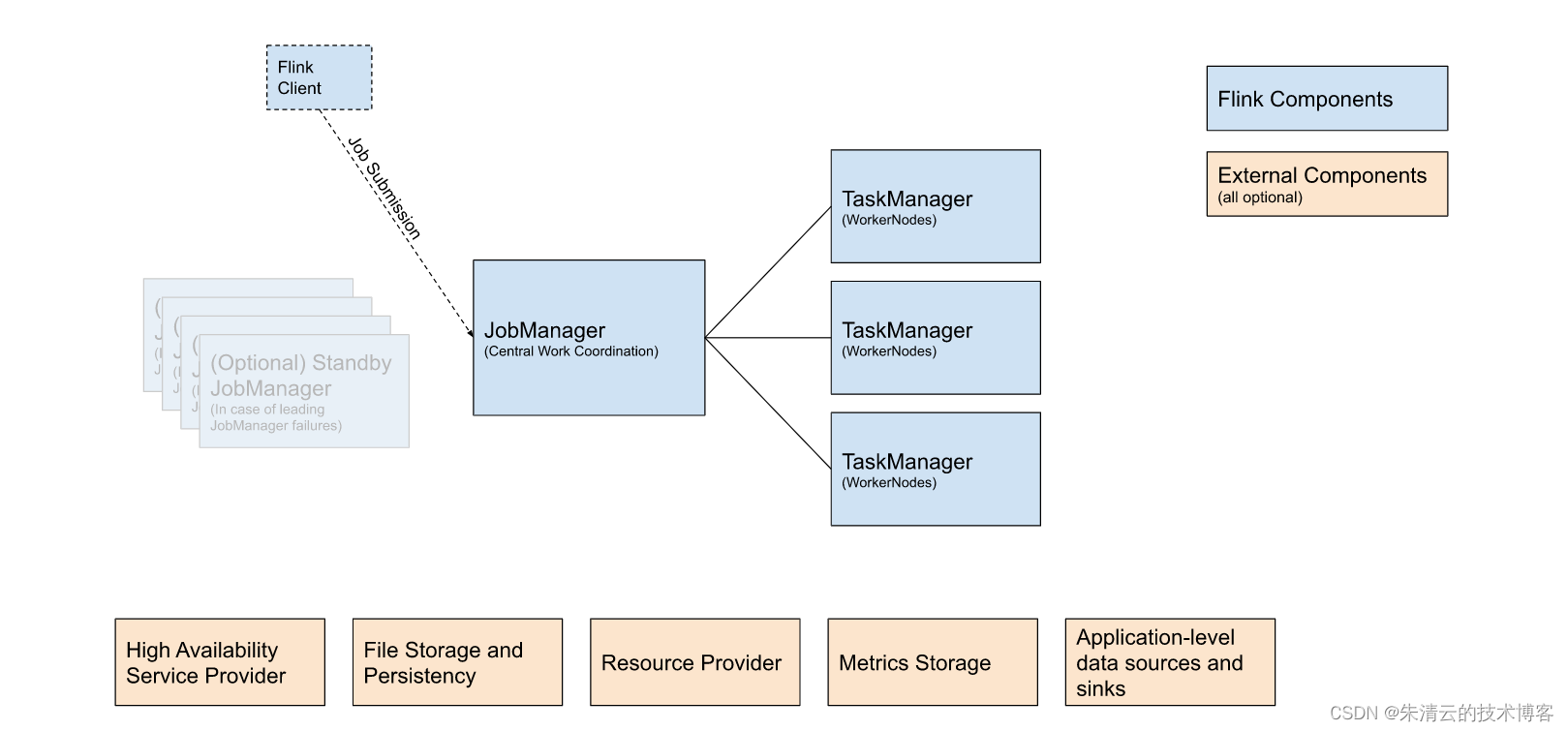
我深入分析了五个大数据处理框架:Hadoop,Spark,Flink,Storm,Samaza Hadoop 顶尖的框架之一,大数据的代名词。Hadoop,MapReduce,以及其生态系统和相关的技术,比如Pig,Hive,Flume,HDFS等。Hadoop是第一个...
Spark大数据分析实战课后答案

模块允许用户扩展 Flink 的内置对象,例如定义行为类似于 Flink 内置函数的函数。它们是可插拔的,虽然 Flink 提供了一些预构建的模块,但用户可以编写自己的模块。例如,用户可以定义自己的地理函数,并将它们作为...
实时计算、离线计算、流式计算和批量计算分别是什么?有什么区别?...其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。 流数据(或数据流)是指在时间分布...
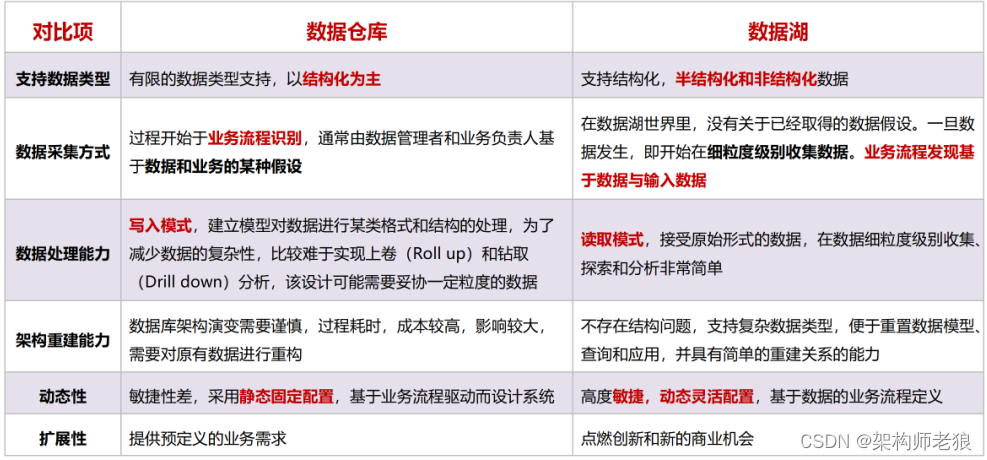

查询块(query block)是 SQL 语句的一个基础组成部分。例如,SQL 语句中任何的内联视图或者子查询(sub-query)都可以被当作外部查询的查询块。一个 SQL 语句可以由多个子查询组成,子查询可以是一个 SELECT,...
Flink 允许我们把 Table 和 DataStream 做转换:我们可以基于一个 DataStream,先流式 地读取数据源,然后 map 成 POJO,再把它转成 Table。Table 的列字段(column fields),就是 POJO 里的字段,这样就不用再...
flink 1.11 支持用户直接使用sql将流式数据写入hive,并且可以自动的创建和刷新hive的分区,支持的数据格式包括json、csv、parquet、csv。 底层是使用了写入文件系统的功能,所以具体的配置可以参考写入文件系统的...
Debezium是一个 CDC(Changelog Data Capture,变更数据捕获)的工具,可以把来自 MySQL、PostgreSQL、Oracle、Microsoft SQL Server 和许多其他数据库的更改实时流式传输到 Kafka 中。Debezium 为变更日志提供了...
一、Flink 专栏Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、...
在flink中,StreamingFileSink是一个很重要的把流式数据写入文件系统的sink,可以支持写入行格式(json,csv等)的数据,以及列格式(orc、parquet)的数据。 hive作为一个广泛的数据存储,而ORC作为hive经过特殊优化的...
本文对比了Spark和Flink的核心特点,指出Flink基于流的模型支持实时性更好,提供高级API和灵活的数据处理。文章建议根据场景选择框架,Spark适用于大批数据处理和历史数据查询,而Flink适用于低延迟的实时数据处理。...
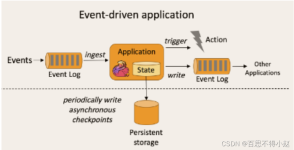
从面试回答的角度出发,介绍了hive和spark的区别,spark和flink的区别和hive和hbase的区别。
推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地