2018和2019年是大数据领域蓬勃发展的两年,自2019年伊始,实时流计算技术开始步入普通开发者视线,各大公司都在不遗余力地试用新的流计算框架,实时流计算引擎Spark Streaming、Kafka Streaming、Beam和Flink持续...
”Storm,Spark和Flink三种流式大数据处理框架对比_天高地阔的专栏-程序员宅基地“ 的搜索结果

一、Flink 专栏Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、...
一、Flink 专栏Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、...
流式数据一但进入就实时进行处理,这就允许流数据灵活地在操作窗口。它甚至可以在使用水印的流数中处理数据(It is even capable of handling late data in streams by the use of watermarks)。此外,flink的代码...
处理时间是指执行相应操作的机器的系统时间。事件时间是每个事件在其生产设备上发生的时间。下图形象的展示了event time 和 processing time的所处阶段。一般将Flink data source下的箭头表示为到达Flink的时间,即...
三、Flink & Storm 四、总结 这四个项目能放在一起比较的背景应该是分布式计算的演进过程。 一、MapReduce 开源分布式计算的第一个流行的框架是 Hadoop 项目中的 MapReduce 模块。它将所有计算抽.
一、Flink 专栏Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、...
上次的例子https://blog.csdn.net/xxkalychen/article/details/117149540?spm=1001.2014.3001.5502将Flink的数据源设置为Socket,只是为了测试提供流式数据。生产中一般不会这么用,标准模型是从消息队列获取流式...

大数据流计算框架包括Storm、Spark Streaming和Flink,满足大规模数据的实时处理需求。文章探讨了大数据实时计算与业务逻辑分离的历史,以及流计算架构对互联网在线业务开发的影响。未来互联网应用开发可能朝着异步...

Flink、Storm与Spark Stream的区别Apache StormApache SparkApache Flink这三种计算框架的对比如下扩展项目应用 Apache Storm 在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑...
3) 数据处理 4) 构建 sink 需求:使用socket统计单词个数 步骤 1) 获取 Flink 批处理运行环境 2) 构建一个 socket 源 3) 使用 flink 操作进行单词统计 4) 打印 前提:安装nc服务 yum install -y nc ...
目前开源大数据实时计算引擎有很多选择,我们可以对他们大致分为流处理和 批处理 第一类是流处理(Native Streaming):这类引擎中所有的data在到来的时候就会被立即处理,一条接着一条(HINT: 狭隘的来说是一条接着一...
sparkstreaming和flink的区别 参考 https://blog.csdn.net/b6ecl1k7BS8O/article/details/81350587 – 组件: sparkstreaming: Master:主要负责整体集群资源的管理和应用程序调度; Worker:负责单个节点的资源管理...
flink是基于事件的真正的实时流式处理,Spark是批量或者微批处理 Flink 用流处理去模拟批处理的思想,比Spark 用批处理去模拟流处理的思想扩展性更好。 Flink最核心的数据结构是Stream,它代表一个运行在多分区上的...
2、Flink是基于事件驱动的,是面向流的处理框架, Flink基于每个事件一行一行地流式处理,是真正的流式计算. 另外他也可以基于流来模拟批进行计算实现批处理。 3.2 架构方面 1、Spark在运行时的主要角色包括:Master...
Spark streaming、Storm、Flink和Beam都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现...
max(field)与maxBy(field)的区别: maxBy返回field最大的那条数据;max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。本文示例中使用的maven依赖和java bean ...
flink kafka 连接配置项目总结
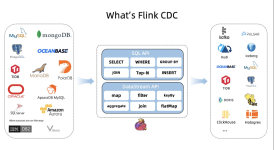
系统介绍某一知识点,并辅以具体的示例进行说明。...3、Flik Table API和SQL基础系列本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。
1. Hadoop vs Spark vs Flink - 数据处理 Hadoop:Apache Hadoop专为批处理而构建。它需要输入中的大数据集,同时处理它并产生结果。批处理在处理大量数据时非常有效。由于数据的大小和系统的计算能力,输出会产生...
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。下图显示了单击事件流(左侧)如何转换为表...
Flink 系列文章 一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如...
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: ...
Apache软件基金会下的顶级开源项目之一,Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm) Flink Apache 软件基金会顶级项目,是Apache软件基金会的5个最大的大数据项目之一 Storm ...
本文由 网易云 发布本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)2.Spark Streaming架构及特性分析2.1 基本架构基于是spark core的spark streaming架构。Spark Streaming是将流式...
推荐文章
- I2C知识大全系列六 —— I2C应用之Linux下的I2C_linux控制i2c应用编程-程序员宅基地
- 微擎URL路由_noloading: true, noredirect: true-程序员宅基地
- 关于arduino程序编译成功但上传失败的情况_arduino编译完成但上传错误-程序员宅基地
- 机器学习中的数据预处理_机器学习数据预处理顺序-程序员宅基地
- 谈一次java web系统的重构思路_java web 如何做系统重构-程序员宅基地
- 如何一文认识 AngularJS_angularjs理解-程序员宅基地
- 编写C语言程序,输入每个学生的学号和身高,保存在二进制文件中,并统计每个身高的人数打印出来...-程序员宅基地
- R语言 最优子集选择与K折交叉验证_最优子集法做交叉验证-程序员宅基地
- antd From 中 Form.Item里含有自己封装的组件,获取不到值的解决方法_from.item 拿到组件无法获取参数-程序员宅基地
- 爬虫的基本原理-程序员宅基地