storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂...
”Storm,Spark和Flink三种流式大数据处理框架对比_天高地阔的专栏-程序员宅基地“ 的搜索结果
storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂...
Flink,Storm,Spark Streaming三种流框架的对比分析。比较清晰明确
storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂...
通过编写核心代码实现,以及使用Spark SQL对数据进行分析和统计,我们可以发现Spark和Flink在数据处理和分析方面具有很强的性能优势,并且我们可以使用它们来处理大规模数据。同时,本文将重点介绍如何使用Spark和...
本文主要调研了Apache Kafka、Apache Flink、Apache Storm、Apache Apex和Apache Spark Streaming五种流式大数据系统。主要的工作有:1)通过文献阅读和试用比较了它们的实现原理;2)利用了kafka自带的测试脚本进行...
本文主要是想了解下Storm、Flink、Spark Streaming这三种流式计算框架的区别以及它们适合的应用场景。 Storm: Storm 是 Twitter 开源的分布式实时大数据处理框架,擅长处理海量数据,适用于数据实时处理而非...
微信公众号(SZBigdata-Club):后续博客的文档都会转到微信公众号中。 1、公众号会持续给大家推送技术文档、学习视频、技术书籍、数据集等。...随着新设备,传感器和技术的出现,数据增长率在不断加速,根据...
我们知道,大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计算...目前主流的流式计算框架有Storm、Spark Streaming、Flink三种,其基本...
在分布式计算框架中,角色即进程,任务通常是以线程的形式跑在计算层的JVM进程中,但是每个框架中是有差异的,以下针对Spark/Storm/Flink三大主流计算框架进行对比。 二.横向对比 在生产中,.

目前我们所接触的比较流行的开源流式处理框架:Flink、Spark Streaming、Storm、Kafka Streams,我会对以上几个框架的应用场景、优势、劣势、局限性一一做说明,大家快来看看哪个流式处理的框架更适合你吧!
转自:https://blog.csdn.net/wjandy0211/article/details/78802044大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机...
天然对接Spark生态栈中的其他组件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高,有问题响应速度也是比较快的,比较适合做流式的ETL,而 且Spark的发展势头也是有目共睹的,相信未来性能和功能将会...
除了计算速度快、可扩展性强,Spark 还为批处理(Spark SQL)、流处理(Spark Streaming)、机器学习(Spark MLlib)、图计算(Spark GraphX)提供了统一的分布式数据处理平台,整个生态经过多年的蓬勃发展已经非常...

Hadoop、Spark、Storm、Flink是比较常用的分布式计算系统 ...3)混合框架:Spark常用于离线的快速的大数据处理(基于内存),Flink可扩展的批处理和流式数据处理的数据处理平台。 关于Hadoop H...
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop、Storm,还是后来的Spark、Flink。然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能有任何一个框架可以...


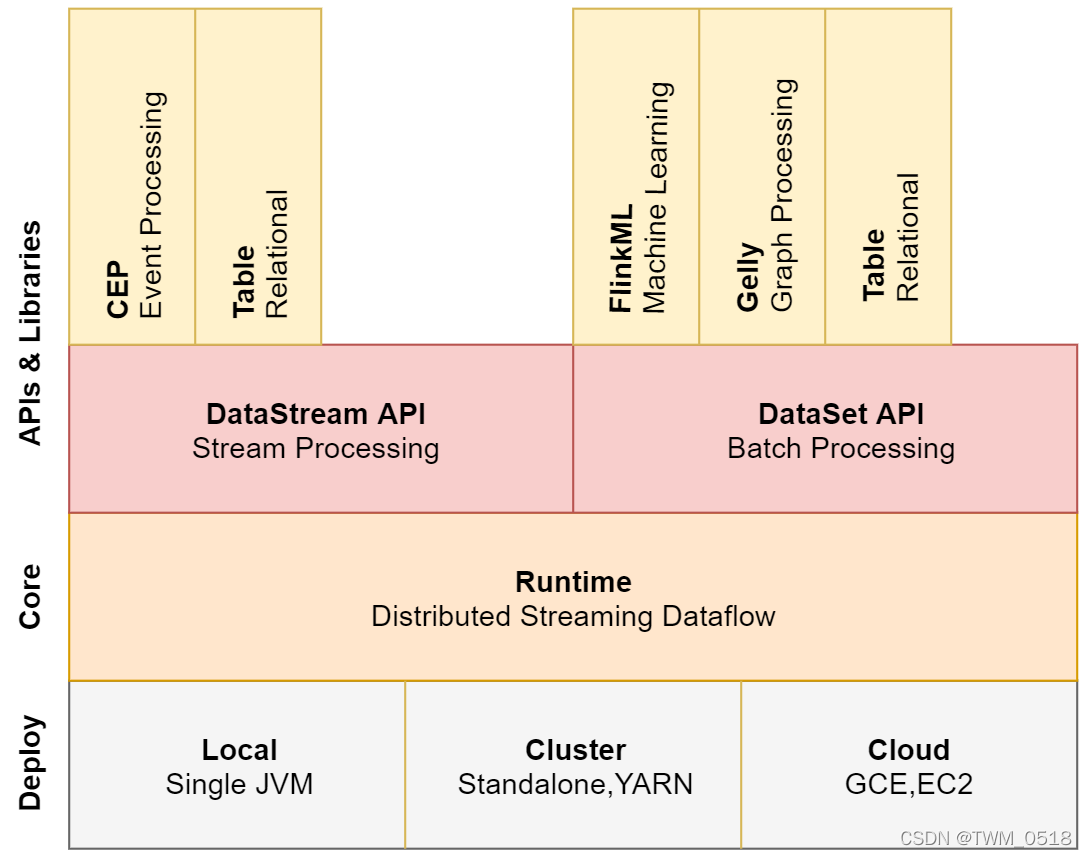
大数据流式处理框架Flink介绍
标签: 大数据
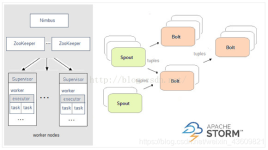
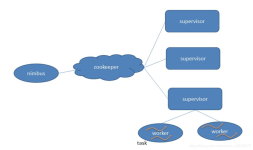
许多分布式计算系统都可以实时或接近实时地处理大数据流。本文将对三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。 Apache Storm 在Storm中,先要设计一个用于实时计算的图状结构,我们称之为...
storm、spark streaming、flink是三个最著名的分布式流处理框架,并且都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都...


Flink CDC有两种实现方式,一种是DataStream,另一种是FlinkSQL方式。 DataStream方式:优点是可以应用于多库多表,缺点是需要自定义反序列化器(灵活) FlinkSQL方式:优点是不需要自定义反序列化器,缺点是只能...
推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地