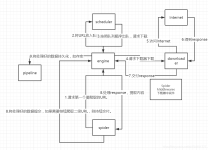
通过Scrapy,我们可以轻松地完成一个站点爬虫的编写。但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码。如果我们将各个站点的Spider...本节我们就来探究一下Scrapy通用爬...
”Scrapy框架的使用之Scrapy通用爬虫“ 的搜索结果

目录1. CrawlSpider2. Item Loader3. 基本使用 ...例如,像 Google、百度这样的搜索引擎就是使用这种通用爬虫抓取了整个互联网的数据,然后经过复杂的处理,最终将处理过的数据保存到分布式数据库中,通过搜
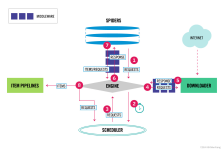
主要介绍了Python Scrapy框架:通用爬虫之CrawlSpider用法,结合实例形式分析了Scrapy框架中CrawlSpider的基本使用方法,需要的朋友可以参考下
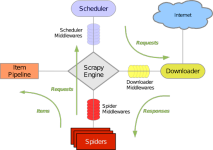
scrapy爬虫框架
标签: python

近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。 一、初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息...
初识scrapy
Python爬虫—scrapy框架
Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
编辑推荐:本文来自于e-learn,文章主要探究一下Scrapy框架通用爬虫的实现方法等相关内容,希望对您的学习能有所帮助。通过Scrapy,我们可以轻松地完成一个站点爬虫的编写。但如果抓取的站点量非常大,比如爬取各大...
答案当然是有的,下面博主就为大家介绍一下Scrapy框架(也是业内运用最为广泛的框架)的基本使用。 Scrapy简介 Scrapy使用纯Python实现,是一个为了爬取网站数据,提取结构性数据而编写的应用框架,其用途非常广泛,...
近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。 一、初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息...
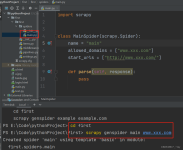
要实现新闻的爬取,我们需要做的就是定义好Rule,然后实现解析函数。下面我们就来一步步实现这个过程。首先将start_urls修改为起始链接,代码如下所示:之后,Spider爬取start_urls里面的每一个链接。...

所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。 一、背景 在做爬虫项目...
近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。一、初窥ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理...


前言转行做python程序员已经有三个月了,这三个月用Scrapy爬虫框架写了将近两百个爬虫,不能说精通了Scrapy,但是已经对Scrapy有了一定的熟悉。准备写一个系列的Scrapy爬虫教程,一方面通过输出巩固和梳理自己这段...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续...然而,使用爬虫需要遵守法律和伦理规范,尊重网站的使用政策,并确保对被访问网站的服务器负责。


Scrapy是用Python实现一个为爬取网站数据、提取结构性数据而编写的应用框架。 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。...AmazonAssociatesWebServices)或者通用的网络爬虫。 接下来的
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地