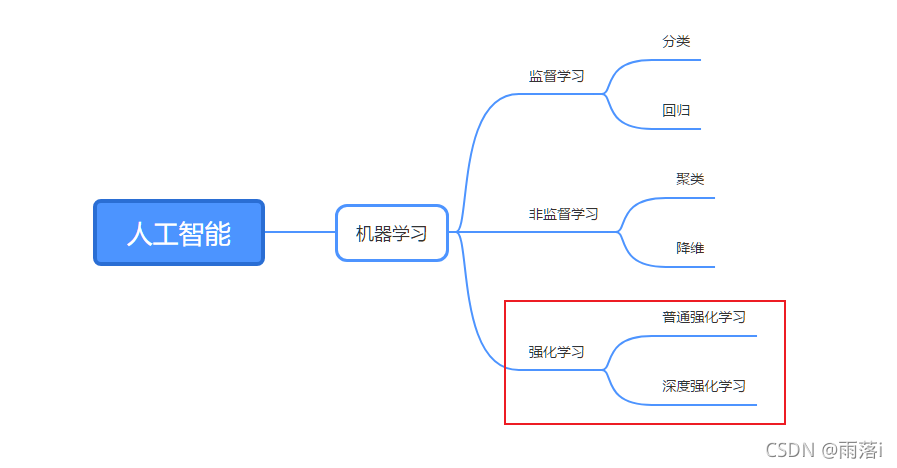
强化学习(Reinforcement Learning,简称RL)是一种机器学习方法,它通过与环境的交互来学习如何做出最佳决策。在这篇文章中,我们将从基本概念到核心算法的原理和具体操作步骤,以及最佳实践、实际应用场景、工具和...
标签: JupyterNotebook
RL
在本篇文章中,我们全面而深入地探讨了强化学习(Reinforcement Learning)的基础概念、主流算法和实战步骤。从马尔可夫决策过程(MDP)到高级算法如PPO,文章旨在为读者提供一套全面的理论框架和实用工具。...
主要介绍的算法有:Q Learning、Sarsa、Sarsa(lamda)、TD、Policy Gradient、AC、A3C、DQN、DoubleDQN、DuelingDQN、DDPG、MCTS、UCT (1)Q Learning:建立Q值表,根据当前state预测Q值,用查表的方式选择action。...
RL基线动物园:预先训练的强化学习代理的集合 使用,具有经过调整的超参数的训练有素的强化学习(RL)代理的集合。 我们正在寻找有助于完成收藏的贡献者! 该存储库的目标: 提供一个简单的界面来训练和享受RL...
RL Baselines3 Zoo:稳定的Baseline3强化学习代理的培训框架 RL Baselines3 Zoo是使用强化学习(RL)的培训框架。 它提供了用于训练,评估代理,调整超参数,绘制结果和录制视频的脚本。 此外,它还包括针对常见环境...
CRC校验详解
CLLD USB_Blaster制作全套资料 ...4、运行MProg3.0_Setup.exe,将altera.ept文件烧入FT245RL的内部EEPROM(FT245BM是在外部94LC46中) 5、打开QUARTUS,就可以在下载器中发现USB-0(USB-BLASET),正常下载了
内含瑞萨RL78G13单片机资料,入门教程,原理图,例程资料,以及相关说明手册。刚接触瑞萨或者参加国赛的小伙伴可以下载了解
使用OpenAI Gym和TensorFlow结合广泛的数学知识来掌握经典RL,深度RL,分布式RL,逆RL等关于这本书 近年来,随着算法质量和数量的显着提高,《 Python上的动手强化学习》第二版已完全改编为示例丰富的指南,用于学习...
(RL)是一个独立的C ++库,用于刚体运动学和动力学,运动计划和控制。 它涵盖了空间矢量代数,多体系统,硬件抽象,路径规划,碰撞检测和可视化。 它已用于研究项目和教育中,已获得BSD许可,可免费用于商业应用。 ...
标签: Python
D4RL:用于深度数据驱动的强化学习的数据集 D4RL是用于离线强化学习的开源基准。它为培训和基准测试算法提供了标准化的环境和数据集。还提供了补充和。设置可以通过以下方式克隆存储库来安装D4RL: git clone ...
本设计分享的是基于FT232RL-USB转串口适配器设计,附原理图/PCB源文件等。该USB转串口适配器集成的FT232RL可用于与MCU进行编程或通信。另一方面,您可以通过该USB转串行接口适配器模块将PC连接到各种无线应用。FT232...
基于 瑞萨 RL78系列 R5F10DPJJ的 CAN总线通信例程, 包括 CAN初始化,报文接收和 发送
D2RL D2RL的官方PyTorch代码:强化学习中的深度密集架构。 下面列出了有关独立复制的TF2实现的详细信息。 论文: : 博客: : 该代码包括训练SAC-D2RL,TD3-D2RL和CURL-D2RL代理的代码。 如果有任何与代码...
Easy-RL 李宏幽默老师的《深度强化学习》是强化学习领域经典的中文视频之一。李老师幽默风趣的上课风格让晦涩难懂的强化学习理论变得轻松易懂,他会通过很多有趣的例子例证解强化学习理论。某些老师经常会用玩Atari...
d4rl-小球 使用Pybullet环境进行数据驱动的深度强化学习的数据集。 这项工作旨在通过开源项目符号模拟器为数据驱动的深度强化学习提供数据集,从而鼓励更多的人加入该社区。 该存储库建立在。 但是,当前,如果不...
1.RL78G13用户手册硬件篇-中文 2.RL78G13用户手册软件篇-英文 3.RL78介绍资料以及芯片选型
RL78 G12 20P中文开发手册 瑞萨单片机开发
RL4J:Java 强化学习有关 RL4J 的支持问题,请联系 。 RL4J 是一个与 deeplearning4j 集成并在 Apache 2.0 开源许可下发布的强化学习框架。 DQN(带双 DQN 的深度 Q 学习) 异步强化学习(A3C,异步 NStepQlearning...
提供了有关RL算法在训练时如何使用内存的见解。 对于PPO之类的基于策略的算法,有必要在整个轨迹上进行训练并丢弃RNN的内存。 但是,是否可以保留每个时间步的隐藏状态,并将每个时间步用作独立的“批”项? 对于...
瑞萨RL78系列pfdl.lb,使用CCRL编译工具。将文件夹添加到工程后,添加包含路径即可
贡献者:Datawhale开源项目组 作为人工智能里最受关注的领域之一,强化学习的热度一直居高不下,但它的学习难度也同样不低。 在学习强化学习的过程中,遇到了有无数资料却难以入门的问题,于是发起了Datawhale强化...
RL-algorithms 更新一些基础的RL代码 离散的动作空间 DQN 可用于入门深度强化学习,使用一个Q Network来估计Q值,从而替换了 Q-table,完成从离散状态空间到连续状态空间的跨越。Q Network 会对每一个离散动作的Q值...
瑞萨RL78系列入门教程及例程,以及瑞萨RL78G12,RL78G14中文数据手册,瑞萨资料比较少,此资料来源于网络收集
相扑SUMO-RL通过用于交通信号控制的提供了一个简单的界面来实例化强化学习环境。 主类继承了的 。 如果使用参数'single-agent = True'实例化,则其行为类似于来自的常规 。 负责使用 API检索信息并在交通信号灯上。 ...
FT232RL驱动 FT232RL
S-RL工具箱:用于机器人技术的强化学习(RL)和状态表示学习(SRL)工具箱该存储库用于评估使用强化学习的状态表示学习方法。 它集成(自动记录,绘图,保存,加载受过训练的代理)各种RL算法(PPO,A2C,ARS,ACKTR...
matlab信任模型代码RL-脑血流 该代码在两个无基线模型的算法之上实现了RL-CBF算法:信任区域策略优化(TRPO)和深度确定性策略梯度(DDPG)。 RL-CBF算法在学习过程中提供了安全保证,有关该算法的详细信息,请参见...